Dédoublonnage et couplage : comment ça marche ?
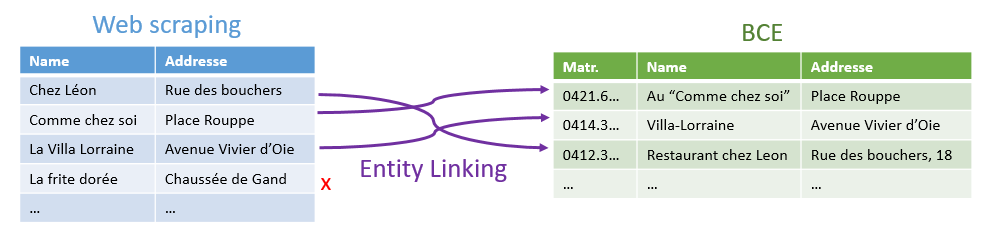
Dans un article précédent à propos du webscraping, nous avons été confrontés à une situation où nous obtenions une liste de commerces, avec un nom et une adresse. Nous voulions, pour chacun de ces commerces, le lier à une liste de commerces "officielle", à savoir celle de la Banque Carrefour des Entreprises, ayant une structure similaire.
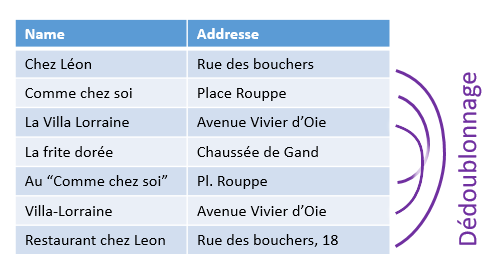
Une situation semblable se produit lorsqu'on a un listing unique (un fichier clients, un carnet d'adresses, un listing d'articles...), et que l'on se rend compte qu'il comporte des doublons. Cette situation n'est pas rare : même si souvent les propriétaires de telles bases de données n'en sont pas conscients, leur très grande majorité comporte des doublons. Même le registre national en comporte !
 La résolution du premier problème est en général nommé "couplage de documents" ("entity linking", "matching" ou "record linkage" dans sa version anglaise) ; celle du second, la déduplication ou dédoublonnage. Ces deux problèmes, qui semblent a priori très différents, vont en fait se résoudre avec les mêmes outils.
La résolution du premier problème est en général nommé "couplage de documents" ("entity linking", "matching" ou "record linkage" dans sa version anglaise) ; celle du second, la déduplication ou dédoublonnage. Ces deux problèmes, qui semblent a priori très différents, vont en fait se résoudre avec les mêmes outils.
Comparaison de candidats
Imaginons que nous voulions comparer deux enregistrements (issus de bases différentes dans le cas du record linkage, ou de la même, dans le cas de la déduplication) :
- Nom = "Comme chez soi" ; adresse = "Place Rouppe"
- Nom = "Au 'comme chez soi'" ; adresse = "Pl. Rouppe"
Ou encore:
- Nom = "Chez Léon" ; adresse = "Rue des bouchers"
- Nom = "Restaurant chez leon" ; adresse = "Rue des bouchers, 18"
L'approche classique consiste à comparer champ par champ les deux enregistrements, pour ensuite donner un certain nombre de "scores", ou d'indicateurs. Cette comparaison dépendra fortement de la nature des informations. Commençons par les noms des restaurants dans nos deux exemples ci-dessus
- Typiquement, on commence toujours par "nettoyer" les textes, de façon à supprimer les détails qui pourraient perturber les comparaisons : accents, guillemets, casse, espaces superflues... ; ceci se fera toujours en fonction de la connaissance que l'on a de la nature des données :
- "Chez Léon" ⇒ "chez leon",
- "Restaurant chez leon" ⇒ "restaurant chez leon",
- "Comme chez soi" ⇒ "comme chez soi",
- "Au 'comme chez soi'" ⇒ "au comme chez soi" ;
- En fonction du secteur d'activité, on peut désirer supprimer (ou déplacer dans un champ additionnel) les mots qui apportent peu d'information, comme la forme légale (S.A., ASBL, SPRL...), ou des mentions comme "entreprise" ou "restaurant". "restaurant chez leon" devient alors "chez leon" ;
- À ce stade, on peut donner un premier indicateur : après nettoyage, nos deux noms ont-il la même valeur ? Nommons cet indicateur "EXACT" : il vaudra "vrai" pour le premier cas ("chez leon" vs. "chez leon"), et "faux" pour le second ("comme chez soi" vs "au comme chez soi") ;
- On va ensuite utiliser des méthodes de calcul de similarité entre deux chaines de caractères :
- La méthode de distance Damereau-Lenveshtein va compter le nombre d'opérations nécessaires pour transformer une chaîne en une autre. Deux chaînes identiques auront une distance de 0. La distance entre "comme chez soi" vs "au comme chez soi" est de 3, pour l'ajout de "au ",
- La "similarité de Jaro-Winkler" va, elle, donner un pourcentage de similarité, entre 0 (rien en commun) et 100% (chaînes identiques). On observe une similarité de 82.2% entre "comme chez soi" vs "au comme chez soi" ;
- Dans certains contextes, il est intéressant de considérer d'autres métriques : une des deux chaînes est-elle un préfixe de l'autre ? Est-elle contenue dans l'autre ? Éventuellement, on rajoutera une métrique calculant la différence de longueur.
Chaque couple que nous comparons peut alors se résumer en une série de métriques :
| Chaine 1 | Chaine 2 | EXACT | DAM_LEV | JARO_WINK | PREFIX | DELTA_LENGTH |
| comme chez soi | au comme chez soi | False | 3 | 0.82 | True | 3 |
| chez leon | chez leon | True | 0 | 1 | True | 0 |
La même méthodologie sera ensuite appliquée sur les autres champs. Pour des adresses, il est souvent bénéfique de faire appel à un géocodeur, qui pourra d'une part standardiser et structurer les adresses, d'autre part les localiser. Il est alors possible de constituer de nombreuses métriques de comparaison. Les adresses sont-elles exactement les mêmes (SAME_ADDR) ? Identique à l'exception du numéro de boite ou de maison (SAME_STREET) ? Distantes de moins de 50 mètres (CLOSE_ADDR) ?
Pour d'autres types de champs, d'autres méthodes s'appliqueront. Par exemple, pour des dates, outre une première méthode de standardisation (pour rendre comparable "2023-01-23" et "23 janvier 2023"), on pourrait identifier des erreurs classiques comme une inversion de mois et jour (due à en encodage Anglo-Saxon), ou deux dates dont le jour et le mois sont le même, mais pas l'année (qui n'a jamais indiqué l'année courante en encodant sa date de naissance ? Ou oublié, en janvier, que l'on était passé à l'année suivante ? ).
Dans la pratique, on arrive vite à construire entre 5 et 10 métriques pour chaque champ, voire combinaison de champs.
Reste alors, en collaboration avec les spécialistes du business, à déterminer une règle permettant de déterminer "il s'agit de la même chose". Par exemple:
(EXACT and CLOSE_ADDR) or ( (DAM_LEV < 5 or JARO_WINK > 0.8) and SAME_ADDR)
Autrement dit, on est soit strict sur la correspondance du nom, et un peu flexible sur l'adresse, soit le contraire, mais pas flexible sur les deux.
Classiquement, on va décrire deux ensembles de règles :
- Les correspondances "certaines", que l'on pourra traiter (fusionner, lier...) automatiquement ;
- Les correspondances "suspectes", que l'on estime être probables, mais qu'il serait dangereux de traiter automatiquement. Elles pourront par exemple être envoyées à un agent.
Identification de candidats
Jusqu'ici, nous faisons l'hypothèse que nous savons quels enregistrements comparer. En théorie, ils suffirait de comparer tous les couples d'enregistrements : N x (N-1) pour un dédoublonnage parmi N enregistrements, ou N x M pour un couplage entre N et M enregistrements. Ceci reviendrait à comparer toutes les cases vertes dans l'illustration ci-contre. 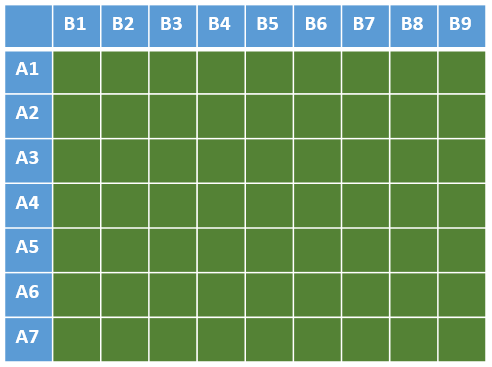 Mais dès que l'on atteint quelques milliers, voire millions d'enregistrements, cette approche n'est plus réaliste. Pour rendre le travail atteignable, nous allons classiquement procéder à une approche par "collision de clé". L'idée est de résumer chaque enregistrement par une "clé" (plus précisément, une série de clés), pour ensuite ne comparer que ceux qui partagent une même clé.
Mais dès que l'on atteint quelques milliers, voire millions d'enregistrements, cette approche n'est plus réaliste. Pour rendre le travail atteignable, nous allons classiquement procéder à une approche par "collision de clé". L'idée est de résumer chaque enregistrement par une "clé" (plus précisément, une série de clés), pour ensuite ne comparer que ceux qui partagent une même clé.
Dans certains cas, cette clé est directement disponible. On peut par exemple se servir du code postal. Ceci permettra de ne comparer que des commerces proches. Mais souvent, il sera nécessaire de construire cette clé.
Calcul de clé
Diverses méthodes existent. Une des plus répandues est l'utilisation de méthodes phonétiques, qui permettent d'évaluer "comment sonne" une chaîne de caractères. Le metaphone résume par exemple "comme chez soi" en "KM XS S". "Villa-Lorraine", ou "Vila-Lorène" seront tous les deux abrégés "FL LRN". On peut considérer comme clé soit le metaphone complet, soit, pour augmenter le nombre de candidats à la comparaison, les 4 premières ou dernières lettres de ce metaphone. Ainsi, "Comme chez soi" ("KM XS S") et "Au comme chez soi" ("A KM XS S") seront considérés. D'autres méthodes phonétiques, comme le Soundex, peuvent être utilisées.
Il est aussi utile, avant d'appliquer un metaphone, de solidement nettoyer les textes, par exemple en supprimant une série de mots trop courts ou trop fréquents (souvent appelés "stop words"), voire même de trier les mots. Être plus agressif à ce stade n'augmente pas le risque de faux-positifs, la réelle comparaisons se faisant bien comme décrit dans la section précédente. 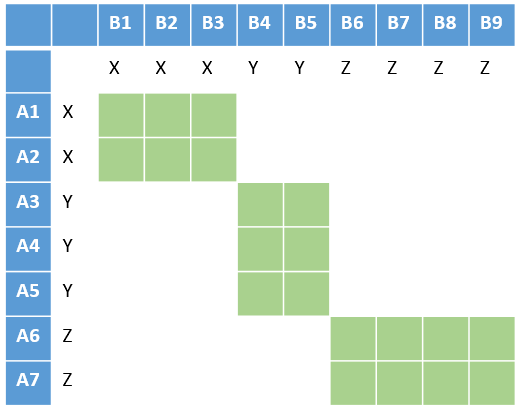 Par contre, elle diminue le risque de faux-négatifs (couplage non trouvé), mais au prix d'une baisse de performance, puisque plus de paires d'enregistrements seront comparés. Il y a donc un compromis à trouver et à affiner expérimentalement.
Par contre, elle diminue le risque de faux-négatifs (couplage non trouvé), mais au prix d'une baisse de performance, puisque plus de paires d'enregistrements seront comparés. Il y a donc un compromis à trouver et à affiner expérimentalement.
Si la clé est suffisamment sélective, on ne doit plus que comparer les cases vertes ci-contre, où les clés ont pour valeur X, Y ou Z.
En général, on choisira un certain nombre de méthodes (certaines basées sur la dénomination, d'autres sur l'adresse, d'autres encore sur des dates), et l'on comparera formellement chaque paire d'enregistrements pour lesquels au moins une de ces clés entre en collision. 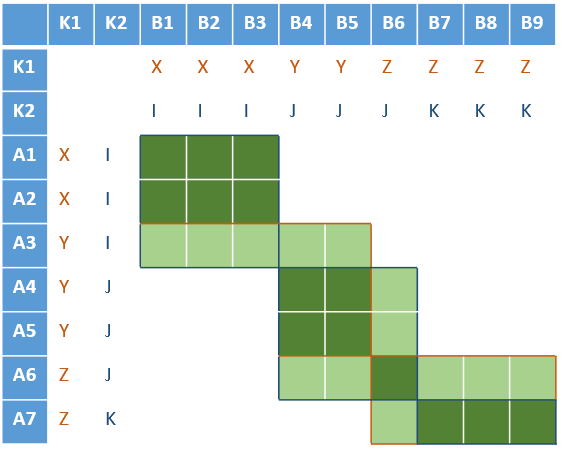 Dans l'illustration ci-contre, avec deux clés K1 (X, Y ou Z) et K2 (I, J, K), on étend un peu la zone à comparer (vert foncé pour les cas concernés par les 2 clés, vert clair pour une seule clé).
Dans l'illustration ci-contre, avec deux clés K1 (X, Y ou Z) et K2 (I, J, K), on étend un peu la zone à comparer (vert foncé pour les cas concernés par les 2 clés, vert clair pour une seule clé).
En pratique
Avec la librairie Python comme "recordlinkage", qui permet très efficacement d'implémenter tout ce qui est décrit ci-dessus, une certaine souplesse est donnée sur l'utilisation des clés de collision. Par exemple, on peut comparer les enregistrements d'une clé à tous ceux de la même clés, mais aussi des clés voisines.
L'outil OpenRefine, permettant de faire une partie de ce qu'on expose ici sans écrire la moindre ligne de code, propose, en plus du mécanisme par collision de clé, une méthode dans laquelle on compare tous les enregistrements entre eux, mais on ne procédera aux calculs complexes (Levenshtein, Jaro...) que si on trouve un certain nombre (configurable) de caractères communs entre les deux chaînes (ce qui peut se faire très rapidement, la plupart du temps en n'examinant qu'une toute petite partie du texte).
Bien sûr, à côté des outils open source décrits ci-dessus, toutes les solutions commerciales permettent également de faire du couplage ou de la déduplication : Trillium (SyncSort), RedPoint, ou le module "Data Quality" de la plupart des gros vendeurs de solution de gestion de données (Informatica, IBM, SAS, SAP, Talend, Oracle...)
Nous décrivons ci-dessus une méthode déterministe : sur base de critères définis, deux enregistrements sont un "match" ou éventuellement un "match suspect". Il existe également des méthodes probabilistes, qui expriment par exemple que ces deux enregistrements ont 92 % de chances d'être des doublons (dans le cas du dédoublonnage) ou une correspondance (pour le couplage). Des nouvelles méthodes basées sur le machine learning sont aussi apparues ces dernières années.
Le mot de la fin
Maintenir une bonne qualité de données est essentiel pour permettre à n'importe quelle entreprise ou organisme publique d'atteindre ses objectifs ou remplir sa mission. Le couplage et la déduplication, deux facettes de la même problématique, font partie des fondamentaux de la gestion de la qualité de données.
Souvent, la nécessité de mettre en place de telles méthodes est un signe de défaut de qualité. Il s'agira dès lors d'une approche curative, mais il est également raisonnable de mettre en place des approches préventives pour éviter que la problématique ne se pose !
Ce post est une contribution individuelle de Vandy Berten, spécialisé en data science chez Smals Research. Cet article est écrit en son nom propre et n’impacte en rien le point de vue de Smals.