Les graphes de connaissance, incontournable pour l'intelligence artificielle
La technologie des graphes a déjà été abordée dans des articles précédents [1] [2] qui mettaient en évidence l’utilité des graphes pour l’analyse de réseaux dans le cadre de la recherche de comportements frauduleux. En effet, de façon générale, les graphes sont relativement faciles à développer et à "comprendre" ce qui en fait un des outils importants d’analyse. Dans ce blog, nous explorons le potentiel de l’approche « graphe » pour des cas autres que l’analyse de réseaux mais où la relation/le lien entre différentes entités est une information qu’on veut entre autre pour des applications d’intelligence artificielle.
Les « knowledge graphs » ou graphes de connaissance
Pour rappel, un graphe est un ensemble d’entités reliées entre elles, composé de nœuds qui représentent les entités et d’arcs ou arêtes qui représentent les relations. Les relations ou arcs peuvent être enrichis par des attributs ou encore une valeur quantitative représentant le poids de la relation.
Le Knowledge Graph, terme introduit par Google, est une représentation de la connaissance relative à un domaine ou une entreprise sous une forme qui est facilement exploitable par la machine. Il est constitué d’entités et de relations, les entités étant des noms de personnes, des concepts, des objets. Bien que cette représentation graphique de la connaissance ne soit pas récente, elle a gagné en popularité et est un élément clé pour des applications d’intelligence artificielle liés à la recherche rapide et contextuelle d’information ainsi qu’à la prise de décision. Les données sont stockées dans des et peuvent être structurées ou non-structurées.
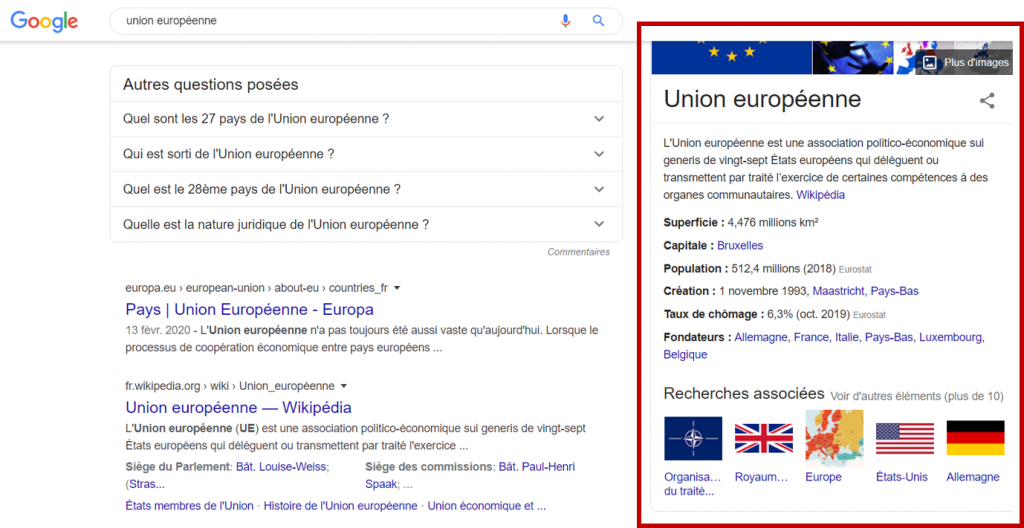
Pour une recherche simple dans Google du terme « union européenne », on a à gauche les résultats issus des ressources indexées et à droite l'infobox qui contient des informations extraites du Google Knowledge Graph.
Le graphe de connaissance est une base de connaissance sémantique qui permet de décrire la sémantique des sources d’information et rendre ainsi le contenu explicite. En effet, une entité ou un mot seul ne porte pas beaucoup de sens en soi, celui-ci se révèle quand l’entité est prise dans son contexte qui est défini par les propriétés de l’entité et les relations avec des entités auxiliaires. Chaque entité participe donc à la compréhension des entités auxquelles elle est liée. On dit alors que la base de connaissance est sémantique car elle encode le sens des données afin de mieux permettre aux machines de comprendre une requête introduite par l’humain. On peut donc utiliser le langage naturel pour interroger une base de connaissance et générer une réponse en langage naturel car les mots sont reliés aux concepts. C’est ce qui permet aux assistants vocaux tels que Google Assistant, Siri ou Alexa de comprendre la requête de l’utilisateur et de répondre avec précision.
Un graphe de connaissance ou knowledge graph se définit par trois éléments ( “Towards a definition of knowledge graph”, Lisa Ehrlinger and Wolfram Wöß) :
- l’ingestion d’information provenant de multiples sources contenant des données structurées et non structurées
Dans une organisation où la connaissance (et les données y afférentes) est organisée en silos, les graphes de connaissances permettent d’avoir une vue globale de l’information. En particulier, ils peuvent mieux que les bases de données relationnelles, capturer des données issues de multiples sources, hétérogènes et même incomplètes. Le principal avantage des bases de données graphes par rapport au bases de données relationnelles est qu’elles permettent de représenter l’information de façon sémantique et permettent d’absorber une grande quantité de données (voir le blog « Bases de données relationnelles... adéquates pour des relations ? »).
- l’intégration de cette information à une ontologie
L’ontologie permet, dans un domaine donné, de structurer les données extraites dans un graphe en décrivant les concepts (personne, lieu, ...), les types de relations entre ces concepts (enfant de), les propriétés, les règles business et les contraintes.
- l’application d’un système d’inférence pour dériver de nouvelles connaissances à partir du graphe
Il est possible avec les graphes d’inférer de nouvelles relations entre entités, générant ainsi une nouvelle information.
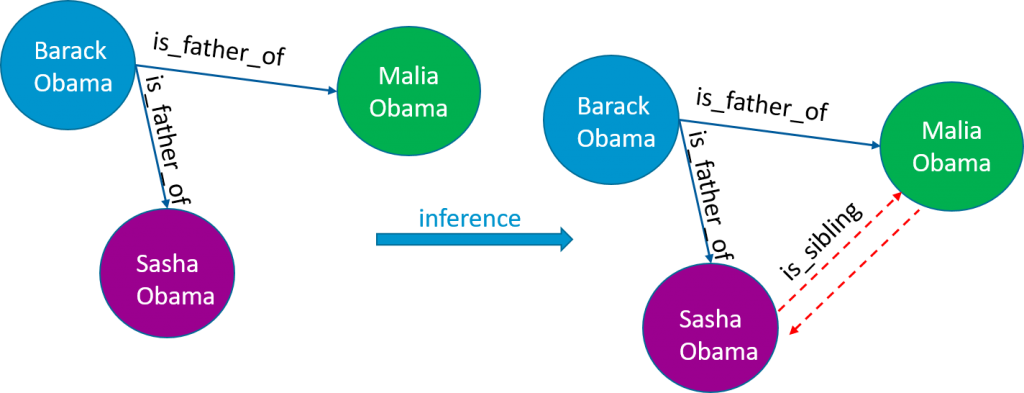
Exemple d'inférence simple: si on définit une règle telle que deux personnes issues du même parent sont dans la même fratrie, on peut rajouter une nouvelle relation "is_sibling"
Exemples de graphes de connaissance publiques:
Construction d'un graphe de connaissance
La construction d’un graphe de connaissance se fait en deux étapes.
Collection et extraction de l’information
Les types de données sont multiples et incluent les textes, les données structurées mais aussi la vidéo et l’audio. Pour l’extraction d’informations nécessaires à la construction du graphe à partir de textes non structurés, on a besoin de techniques de traitement automatique du langage ou NLP (Natural Language Processing) :
- extraction des entités/nœuds : named entity recognition , co-reference resolution et entity linking/named entity disembiguation
- extraction des relations : relation extraction, classification, pattern-based relation extraction
Une fois les entités et relations extraites, on construit le graphe en intégrant les concepts et les contraintes définis par l’ontologie.
Vérification et inférence
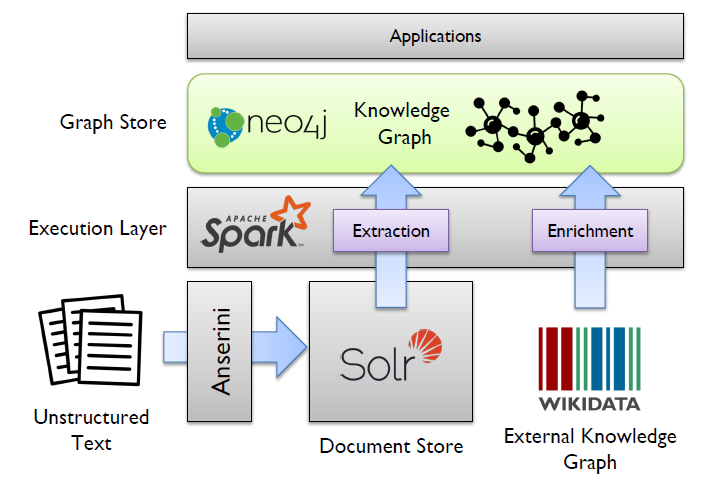
Knowledge Graph Construction from Unstructured Text (Proceedings of the Second Workshop on Fact Extraction and VERification (FEVER), pages 39–46)
Une étape de vérification est nécessaire afin de détecter les incohérences dans le graphe. La dernière étape de la construction d’un graphe de connaissance consiste à inférer de nouvelles relations entre les nœuds sur base des relations déjà présentes dans le graphe. Une première approche est d’utiliser l’inférence logique. Néanmoins cela peut s’avérer très vite ingérable car il faut pouvoir définir une ou plusieurs règles pour chaque type de relation. Une autre approche consiste à utiliser l’apprentissage automatique ou machine learning.
La création de graphes de connaissance est complexe et présente quelques challenges :
- La qualité des données, pour garantir la qualité d'un graphe de connaissance il faut:
- assurer la mise à jour permanente des données
- assurer que les données sont correctes
- assurer que les données sont complètes et couvrent suffisamment le concept que l’on veut ajouter au graphe (problèmes de relations manquantes et nœuds manquants)
- La vérification et l’enrichissement
- la vérification est difficile à réaliser manuellement à grande échelle
- il faut pouvoir détecter les doublons
- il faut pouvoir gérer les conflits
- L’établissement de contraintes sur les relations
Applications des graphes de connaissances
Les applications des graphes de connaissance sont multiples, ils sont notamment importants pour des applications d’intelligence artificielle qui nécessitent de comprendre le langage humain en leur apportant une dimension sémantique :
- La recherche d’information contextualisée, l’analyse de textes (text analytics). Cela permet d’avoir une vue holistique de l’information concernant un sujet donné en enrichissant les résultats.
- Les systèmes de recommandation proactifs (quel produit ou quel film proposer mais aussi quel document lire, quel collègue contacter,…).
- Les systèmes de « question answering». Les graphes de connaissance sont utilisés pour répondre aux questions exprimées en langage naturel.
- Les robots conversationnels ou chatbots; on utilise un graphe de connaissance pour lier des mots et des concepts afin d’apporter la réponse la plus pertinente à la question de l’utilisateur.
Nous essaierons d’aborder l’utilisation pratique des graphes de connaissance de façon plus détaillée dans un prochain blog.
[1] http://www.smalsresearch.be/un-fraudeur-ne-fraude-jamais-seul/
[2 ] http://www.smalsresearch.be/un-fraudeur-ne-fraude-jamais-seul-partie-2/
https://www.smalsresearch/bases-de-donnees-relationnelles-adequates-pour-des-relations/
https://www.smalsresearch.be/gerer-les-doublons-dans-une-graph-database/
“Towards a definition of knowledge graph”, Lisa Ehrlinger and Wolfram Wöß
“Knowledge Graph Construction from Unstructured Text”, Proceedings of the Second Workshop on Fact Extraction and VERification (FEVER), pages 39–46