Ingestion de données pour les applications d’IA générative: concepts-clés
L’ingestion de données est le processus de collecte et d’importation de données provenant de différentes sources vers un système de stockage centralisé (data warehouse, data lake, vector store, etc.) en vue de les exploiter pour des usages spécifiques. Les données peuvent provenir de sources diverses telles que les bases de données, les fichiers PDF/excel/xml, les logs, les APIs et événements ou les sites web. Le processus d’ingestion doit s’assurer que les données sont correctes, complètes et disponibles en temps quasi-réel pour soutenir les analyses d’entreprise.
Si les méthodes d’ingestion de données traditionnelles sont bien connues, l’utilisation de données pour alimenter de grands modèles de langage (LLM) présente quelques spécificités. Dans cet article, nous allons discuter de l’ingestion de données, principalement non structurées, pour constituer les bases de connaissance sur lesquelles s’appuient des applications d’IA générative telles que les chatbots.
Description d’un pipeline d’ingestion de données
Le pipeline présenté ci-dessous s’applique à un système de type RAG (Retrieval-Augmented Generation) pour la génération de réponses aux questions basée sur une base de connaissance. La base de connaissance est alimentée par plusieurs sources de données qui traverse le pipeline, de la collecte à l’indexation dans une base de données vectorielle. Les principales étapes de ce pipeline sont les suivantes.
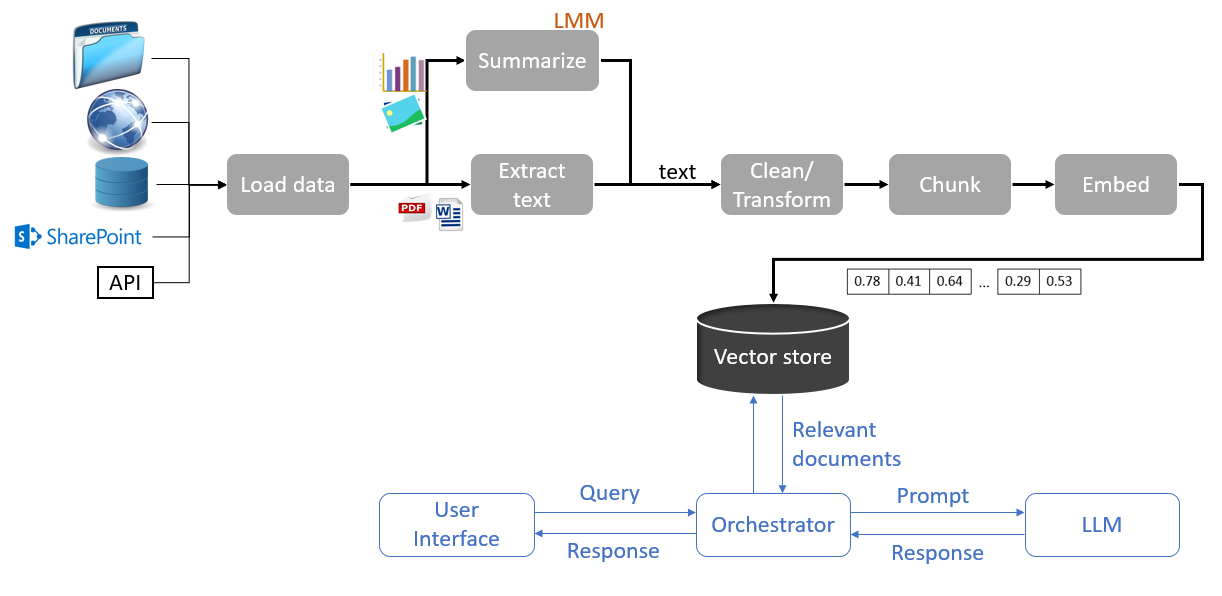
Chargement des données
L’étape la plus importante dans la construction d’un pipeline d’ingestion pour un projet donné consiste à identifier les sources de données nécessaires pour la réalisation de ce projet. Les inputs utilisées dans le cadre de projets RAG sont principalement des données non structurées provenant de multiples sources telles que les sites internet, les réseaux sociaux, les répertoires locaux, bases de données, les outils de gestion de contenus (par exemple SharePoint), Confluence et les services de stockage (par exemple S3). Pour chacune des sources utilisées, il est essentiel de disposer des connecteurs appropriés et de vérifier que l’on possède les droits d’accès nécessaires.
Extraction
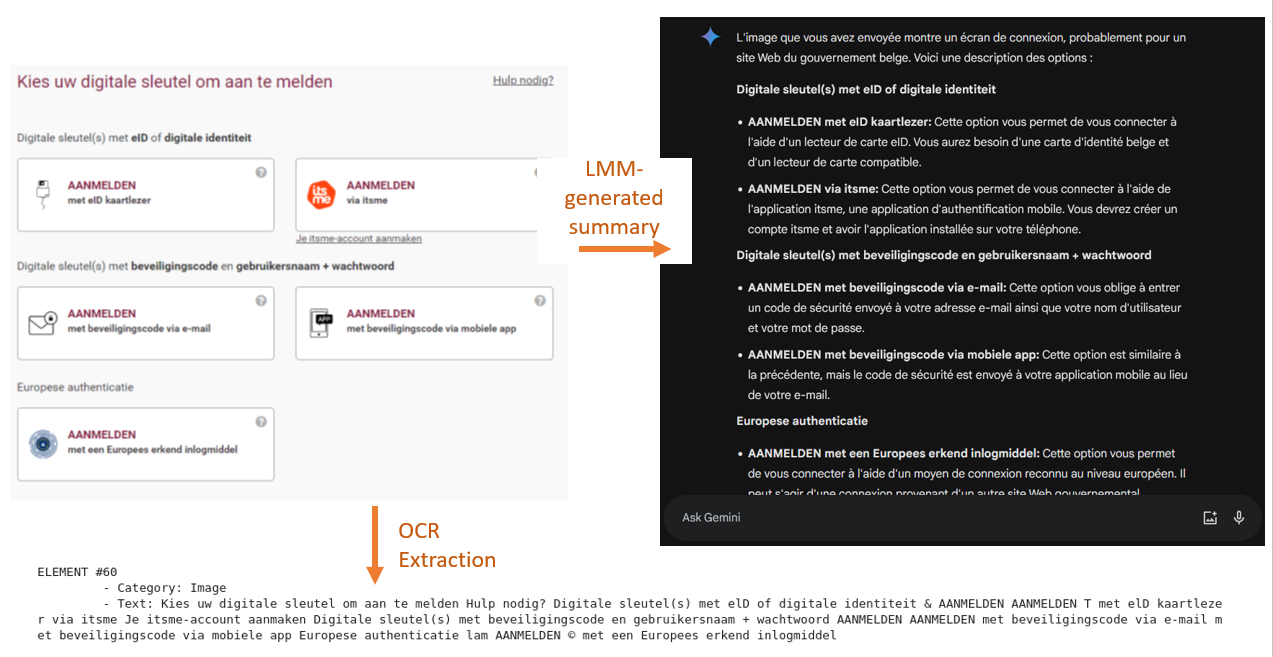
Une fois les sources identifiées et les connecteurs configurés, l’extraction du contenu peut commencer. Le processus d’extraction dépend de la source de données et du format de données. Si la source de données est une page web, il convient d’utiliser un outil de scraping pour extraire le contenu HTML, puis d’analyser ce contenu pour en extraire les informations pertinentes. Si la source de données est une image, il sera nécessaire d’utiliser un outil OCR, tandis que pour les bases de données, il faudra écrire des requêtes SQL appropriées.
L’opération d’extraction du contenu peut être associé à un processus d’enrichissement du contenu par génération de métadonnées. Ces métadonnées sont extraites de la source de données elle-même (par exemple le nom du document, le nom de l’auteur, l’URL, les dates de création et de modification, les tags) ou du contenu lui-même (l’en-tête, le titre, les tags XML). Une autre méthode d’enrichissement de données consiste à utiliser des modèles génératifs pour générer les descriptions images et de tableaux se trouvant dans les données.
Quelle que soit le format des données d’origine, le résultat du processus d’extraction doit être uniformisé. Il consiste généralement en un texte et les métadonnées associées sous format JSON.
Nettoyage et transformation
Les données extraites des sources sont rarement utilisables telles quelles et nécessitent d’être nettoyées. L’opération de nettoyage est l’étape la plus chronophage et varie selon le cas d’utilisation. Les opérations les plus communes appliquées au contenu sont les suivantes :
- Nettoyage de la ponctuation et de caractères spéciaux.
- Suppression des doublons.
- Suppression des informations inutiles comme par exemple les bannières publicitaires et cookies présentes dans les contenus provenant de sites internet qui introduisent du bruit dans les données.
- Contrôle et correction des informations contradictoires, incohérentes ou fausses, celles-ci affectent fortement la réponse générée à l’autre bout de la chaine du processus RAG.
- Traitement des informations manquantes. Quelques exemples d’informations manquantes dans les données non structurées sont par exemple des liens vers d’autres page web contenant des informations complémentaires au contenu extrait, des emails renvoyant vers d’autres emails, etc.
Chunking
Le chunking est l’opération de découpage d’un texte en plus petites unités. Cela permet au modèle de récupérer uniquement les passages contenant l’information pertinente pour la réponse. Ils existent plusieurs méthodes de chunking qui peuvent être regroupées en deux catégories : le chunking basé sur des règles prédéfinies (taille fixe, par paragraphe) et le chunking basé sur la sémantique (groupement de segments similaires). Un chunking efficace nécessite de trouver le bon équilibre entre temps d’attente et coût. Plus petit est le chunk, plus on a besoin de stockage et plus le temps de latence est élevé, plus le chunk est grand, plus le contexte du modèle est grand et donc le coût élevé. Quelle que soit la méthode choisie, il est important de prendre en compte la structure du texte et la longueur maximale de contexte du modèle de langage.
Génération des représentations vectorielles de données (Embedding)
C’est l’étape de conversion des données textuelles en vecteurs sur lesquels pourra s’appliquer la recherche sémantique propre au RAG (retrieval). Ils existent plusieurs techniques d’embedding mais la plus performante est la technique d’embedding contextuelle basée sur les grands modèles de langage.
L’indexation
C’est l’étape ultime du pipeline d’ingestion. Les données en sortie du pipeline sont indexées dans une base de données vectorielle telle que Weaviate, Pinecone, ElasticSearch, etc. Les métadonnées sont également insérées dans la base de données, elles permettent d’affiner les résultats lors de l’opération de recherche (retrieval). Le choix de la base de données vectorielle ainsi que du type d’indexation se fait en fonction du volume de données à stocker et des performances recherchées.
Autres aspects à prendre en compte
Ingestion en batch ou en streaming
En mode batch, les données sont ingérées en masse à intervalles réguliers ou sur demande.
En mode streaming, les nouvelles données sont directement ingérées en temps réel ou presque. On choisit le mode streaming quand il est nécessaire d’avoir l’information la plus récente et que celle-ci évolue rapidement. L’ingestion en streaming requiert un monitoring constant afin de détecter le moindre changement dans la structure des données.
Gestion des mises à jour
Pour gérer les mises à jour, la traçabilité des données est importante. Ceci implique de traquer des informations tels que source, version, timestamp, date de dernière modification, … La mise à jour est alors déclenchée par les informations traquées. Deux stratégies sont possibles pour gérer les mises à jour dans les bases de données de destination : la mise à jour incrémentale (seules les données qui ont changé sont ingérées) ou la mise à jour intégrale. La multiplicité des sources et des formats des données utilisées par les applications basées sur les LLM introduit de nombreux problèmes qui sont soit dus à une mauvaise gouvernance des données à la source, soit dus à un mauvais traçage des changements par le consommateur de données.
Gestion de la sécurité
Comme pour tout système qui traite des données, un minimum de mesures de sécurité s’applique au processus d’ingestion:
- Le contrôle des accès aux sources.
- L’attribution des droits d’accès appropriés au moment de l’insertion du contenu dans la base de données cible.
- La sécurisation du transfert des données entre la source et le système d’ingestion pour éviter la modification de données (data tampering).
- Etc.
Dans le cas des applications RAG, on retrouve régulièrement des données à caractère personnel dans les documents non-structurés. Celles-ci requièrent une attention particulière car soumise à une régulation stricte (RGPD). Bien souvent une anonymisation des données est nécessaire avant insertion dans la base de données de destination. Il faut donc prévoir une étape de filtrage de données personnelles identifiables ou PII filtering dans le pipeline. Des outils efficaces existent mais ceux-ci ne garantissent pas un filtrage à 100% correct.
Un autre point d’attention propre au RAG est le choix de sources fiables. Dans beaucoup d’applications RAG avancées, les informations sont extraites à la volée de sites web. Une bonne pratique consiste à restreindre l’application à une liste de sites web prédéfinis qui peuvent être interrogés.
Monitoring et gestion des erreurs
A chaque étape du pipeline les erreurs doivent être enregistrés dans des journaux et des systèmes d’alertes doivent être mis en place.
L’évaluation globale du système d’ingestion se fait de façon indirecte en monitorant les performances du système RAG. Une mauvaise réponse peut être due au manque d’informations dans la base de données (réévaluer les sources), à un mauvais chunking (mesurer l’utilisation des chunks, leur impact dans la réponse fournie), etc…
Quelques cas particuliers
Le RAG combiné à une recherche web
Typiquement, les sources d’information qui alimentent le système de question-réponse sont la base de connaissance alimentée par le pipeline d’ingestion et le résultat de requêtes web exécutées à la volée au moment de traiter la question.
Le processus d’extraction est piloté par le modèle génératif (LLM) qui, en fonction de la question, fait appel à la source la plus appropriée ou à une combinaison des deux.
Le RAG multimodal
Le RAG multimodal permet d’interroger les données sous différentes formes : texte, image, vidéo, audio. Plusieurs stratégies sont alors possibles pour ingérer ces différents types de données :
- Utilisation d’une modalité de référence. Une modalité sert de référence pour la représentation des données et les autres modalités sont ancrées dans cette modalité de référence grâce à des modèles spécifiques. Dans l’exemple de pipeline illustré ci-dessus, la modalité de référence est le texte et pour chaque image présente dans les données on génère un résumé textuel qui représente cette image.
- Utilisation d’un modèle multimodal. Un modèle d’embedding unique et multimodal est utilisé pour générer les représentations vectorielles des données quelque soit leur type.
Outils
Le choix d’une plateforme d’ingestion dépend de la complexité du processus, du volume de données traité, de la rapidité de traitement nécessaire et des connecteurs source et destination disponibles.
- Airbyte. Moteur d’intégration des données structurées et non structurées utilisé pour alimenter les data warehouse ou data lake.
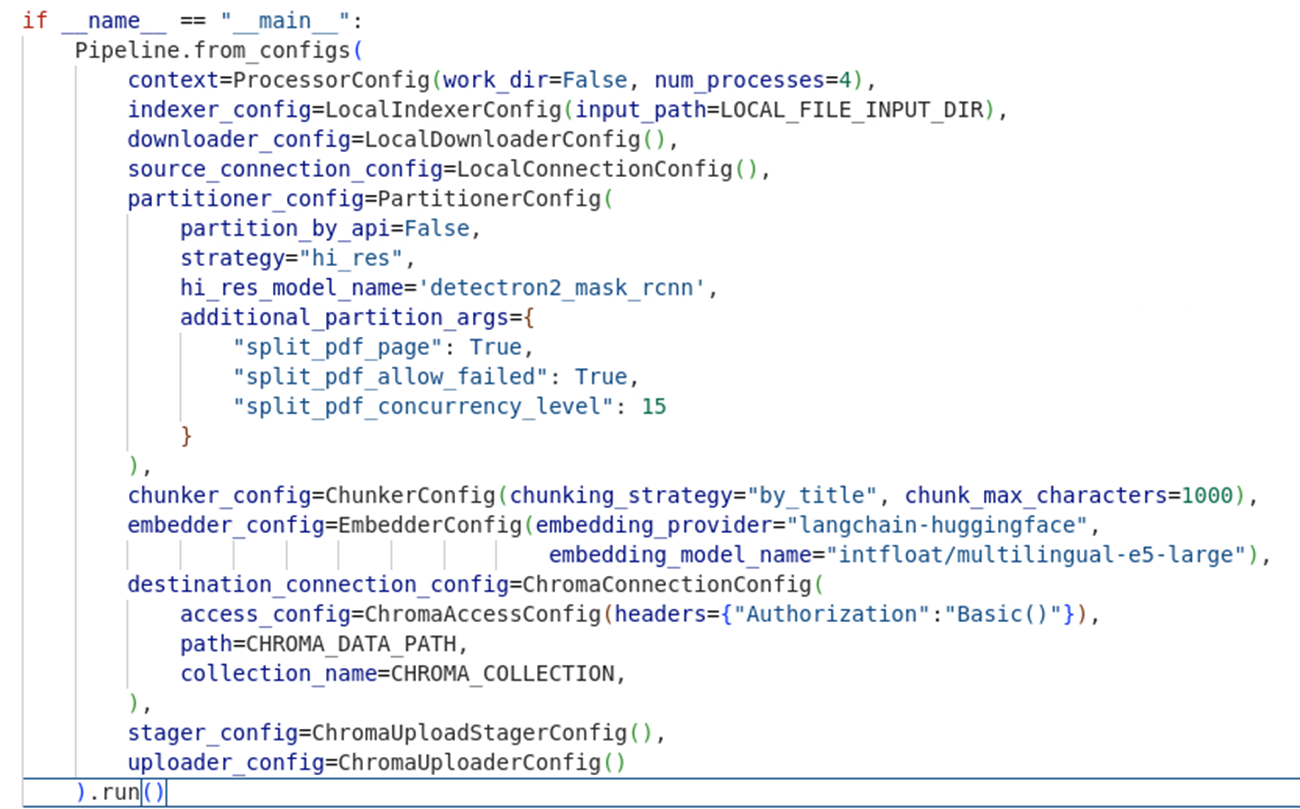
- Unstructured. Outil de construction de pipelines de données pour les LLM [vous trouverez une quick review que nous avons écrit sur cet outil en suivant ce lien].
- Langchain. Outil très versatile de développement d’applications basées sur l’IA générative, s’intègre avec de nombreuses sources de données ainsi que la plateforme Unstructured, propose de nombreuses fonctions de chunking.
- LlamaIndex. Outil de développement d’applications basées sur l’IA générative pour la recherche dans les bases de connaissance. LlamaIndex dispose également d’un service de gestion des pipelines de données LLamaCloud.
- Ray. Bibliothèque Python pour la gestion des processus computationnels distribués.
- Récupération des données d’une page web : BeautifulSoup (bibliothèque Python), Playwright, FireCrawl.
- Presidio : Filtrage des données personnelles identifiables.
Conclusions
L’ingestion de données est une étape critique dans la construction d’une application basée sur l’IA générative car comme le dit l’adage, « garbage in, garbage out ». L’article ci-dessus présente quelques techniques et bonnes pratiques d’ingestion de données ; cependant, chaque cas d’application a ses spécificités et ses difficultés qui dépendent largement du domaine d’application de la solution. C’est pourquoi, l’élaboration d’une stratégie d’ingestion de données doit être le résultat d’une collaboration étroite entre un expert technique et un spécialiste du domaine.
_________________________
Ce post est une contribution individuelle de Katy Fokou, spécialisée en intelligence artificielle chez Smals Research. Cet article est écrit en son nom propre et n’impacte en rien le point de vue de Smals.