Bases de données relationnelles... adéquates pour des relations ?
Avertissement : cet article nécessite des connaissances élémentaires en bases de données.
Bases de données relationnelles et relations
Les bases de données relationnelles servent à représenter des relations. Cette affirmation peut sembler un euphémisme. Pourtant, à y regarder de plus près, les choses ne sont peut-être pas si évidentes. Essayons de comprendre pourquoi au travers de quelques exemples simples.
Supposons d'abord que l'on souhaite représenter des travailleurs, et les entreprises pour lesquelles ils travaillent, en supposant dans un premier temps qu'un travailleur ne travaille que pour une seule entreprise. 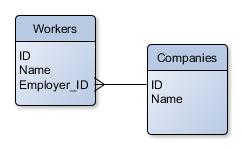 Une modélisation relationnelle simple consistera à utiliser deux tables : une première que nous appellerons "Workers", et une seconde "Companies". Typiquement, les deux tables posséderont une "clé primaire" (primary key) permettant d'identifier chaque ligne de façon unique ("ID" dans le schéma ci-contre). Chaque table possédera également des attributs tels que "Name", ou des identifiants nationaux. Pour savoir pour quelle entreprise emploie un travailleur en particulier, il conviendra de placer une clé étrangère (foreign key) dans la table Workers, faisant référence à la clé primaire de la table Companies (Employer_id dans notre exemple).
Une modélisation relationnelle simple consistera à utiliser deux tables : une première que nous appellerons "Workers", et une seconde "Companies". Typiquement, les deux tables posséderont une "clé primaire" (primary key) permettant d'identifier chaque ligne de façon unique ("ID" dans le schéma ci-contre). Chaque table possédera également des attributs tels que "Name", ou des identifiants nationaux. Pour savoir pour quelle entreprise emploie un travailleur en particulier, il conviendra de placer une clé étrangère (foreign key) dans la table Workers, faisant référence à la clé primaire de la table Companies (Employer_id dans notre exemple).
Dans ce premier schéma, on distingue bien deux types d'entité (à savoir des travailleurs et des entreprises), mais ce qui les lie est un attribut ("Employer_id"), qui n'est pas distinguable des autres attributs, tels que "Name". Ce qui fait que cet attribut "joue le rôle d'une relation", c'est que lorsque l'on exécutera une requête SQL, on précisera dans le "JOIN" quels sont les attributs à lier. Par exemple, pour obtenir la liste des employés de la société "Smals", on écrira :
SELECT Workers.Name
FROM Workers
JOIN Companies
ON Workers.Employer_ID = Companies.ID
WHERE Companies.Name = 'Smals'
La base de données elle-même, mise à part éventuellement la définition de contraintes d'intégrités (optionnelles) lorsqu'elles sont disponibles, n'a pas "conscience" de l'existence de la relation. C'est au développer de l'application (et non au concepteur de la base de données) de préciser dans chaque requête, d'une part quelle est la structure de la table (JOIN ... ON), d'autre part la sélection qu'il désire obtenir (WHERE ...).
Supposons maintenant qu'un travailleur puisse travailler pour plusieurs employeurs (on veut donc une relation "many-to-many"). Ou bien que l'on souhaite ajouter des attributs à la relation de travail (date de début, ...). 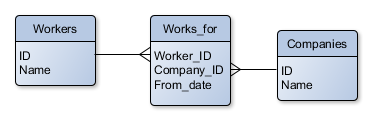 Le modèle ci-dessus ne tient plus, et il faut rajouter une "table de jointure" ("join table") que nous appellerons "Works_for". La structure est alors représentée par le schéma ci-contre. Nous avons donc maintenant deux tables qui décrivent des entités (Workers et Companies), et une table qui décrit une relation (Works_for). Fondamentalement, mise à part l'utilisation qu'on en fait, rien ne permet de distinguer les tables qui jouent le rôle d'entité, de celles qui jouent le rôle de relation. En général, les tables représentant des entités peuvent être caractérisées par un nom commun (personne, société, facture, produit...), alors que les tables représentant des relations seront plus caractérisées par des verbes (travaille pour, achète, contient...).
Le modèle ci-dessus ne tient plus, et il faut rajouter une "table de jointure" ("join table") que nous appellerons "Works_for". La structure est alors représentée par le schéma ci-contre. Nous avons donc maintenant deux tables qui décrivent des entités (Workers et Companies), et une table qui décrit une relation (Works_for). Fondamentalement, mise à part l'utilisation qu'on en fait, rien ne permet de distinguer les tables qui jouent le rôle d'entité, de celles qui jouent le rôle de relation. En général, les tables représentant des entités peuvent être caractérisées par un nom commun (personne, société, facture, produit...), alors que les tables représentant des relations seront plus caractérisées par des verbes (travaille pour, achète, contient...).
Le requête ci-dessus devient encore un peu plus complexe :
SELECT Workers.Name
FROM Workers
JOIN Works_for
ON Workers.ID = Works_for.Worker_ID
JOIN Companies
ON Works_for.Company_ID = Companies.ID
WHERE Companies.Name = 'Smals'
On voit donc avec ces deux exemples que dans une base de données relationnelle, une relation peut être représentée de deux façons différentes :
- Soit en détournant le rôle d'un attribut, en transformant sa fonction "caractérisante" pour lui donner une fonction "relationnelle",
- Soit en détournant le rôle d'une table, en transformant sa fonction "entité" au profit d'une fonction "relationnelle".
Dans les deux cas, ce n'est pas le concepteur de la base de données qui assure les relations (bien qu'il puisse, optionnellement, définir les relations possibles via les contraintes d'intégrité), mais bien le développeur de requêtes SQL. Par ailleurs, le modèle relationnel requière bien souvent une table distincte pour chaque type de relation.
En termes de complexité, pour obtenir le résultat ci-dessus, le moteur du RDBMS doit d'abord trouver l'entrée dans la table "Companies" dont le nom est égal à "Smals", dont il obtient l'ID. Il va ensuite rechercher dans la table "Works_for" la ou les entrées ayant l'attribut "Company_id" correspondant à l'ID trouvé ci-dessus, ce qui peut se faire, grâce à un index, dans un temps logarithmique par rapport au nombre d'entrées dans la table. Ensuite, il doit à nouveau chercher tous les travailleurs correspondant aux entrées qu'il vient de trouver, au prix d'une nouvelle recherche logarithmique. Le temps de réponse de la requête augmentera donc en fonction de la taille de données.
Récursivité
Lorsque l'on s'intéresse à des relations exprimant plus un réseau qu'une hiérarchie, comme par exemple des relations d'amitiés (relations) entre des personnes (entités), ou des routes (succession de relations) empruntées par des données sur un réseau d'ordinateurs (entités), les choses se compliquent nettement si l'on désire utiliser une base de données relationnelle.
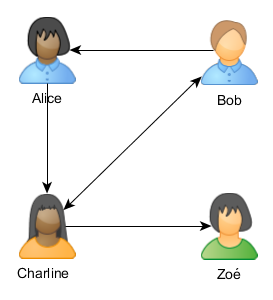 Prenons un exemple simple dans lequel des personnes sont liées par des liens d'amitié (il pourrait s'agir d'ordinateurs et des connexions réseaux, de packages Java et des dépendances...). On veut représenter le schéma suivant, dans lequel une flèche entre Bob et Alice indique que Bob aime Alice, mais que la réciproque n'est pas vraie.
Prenons un exemple simple dans lequel des personnes sont liées par des liens d'amitié (il pourrait s'agir d'ordinateurs et des connexions réseaux, de packages Java et des dépendances...). On veut représenter le schéma suivant, dans lequel une flèche entre Bob et Alice indique que Bob aime Alice, mais que la réciproque n'est pas vraie.
Une représentation classique relationnelle consistera à considérer une table "People", 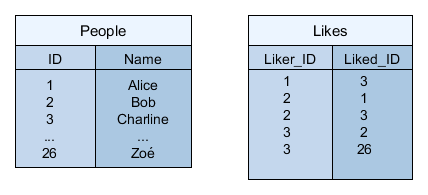 avec un attribut "Name", et une clé primaire "ID", et une table de jointure "Likes", avec deux clés étrangères Liker_ID, Liked_ID, indiquant qui (Liker_ID) aime qui (Liked_ID). Si l'on veut répondre à la question toute simple "Quelles sont les personnes que Bob aime" (Alice et Charline, en l'occurrence), il faudra écrire la requête suivante :
avec un attribut "Name", et une clé primaire "ID", et une table de jointure "Likes", avec deux clés étrangères Liker_ID, Liked_ID, indiquant qui (Liker_ID) aime qui (Liked_ID). Si l'on veut répondre à la question toute simple "Quelles sont les personnes que Bob aime" (Alice et Charline, en l'occurrence), il faudra écrire la requête suivante :
SELECT p1.Name
FROM People p1 JOIN Likes
ON Likes.Liked_ID = p1.ID
JOIN People p2
ON Likes.Liker_ID = p2.ID
WHERE p2.Name = "Bob"
Dans cette requête, deux lignes (la première et la dernière) indiquent ce que le développeur veut réellement, les quatre autres précisent comment la relation est structurée dans la base de données.
Pour retrouver la réciproque, à savoir "Qui aime Bob ?", il faudra modifier une série d'éléments de la requête, pour inverser les relations considérées.
Si l'on voulait suggérer à Bob de nouveaux amis, un système de recommandation classique chercherait à lui présenter les personnes qu'aiment les personnes que Bob aime, sur le principe de "les amis de mes amis sont mes amis". Une relation d'amitié de degré 2, en quelque sorte. La question, en l'apparence toute simple, nécessite une requête particulièrement difficile à lire, et donc à vérifier ou à maintenir :
SELECT p1.Name
FROM People p1 JOIN Likes l1
ON l1.Liked_ID = p1.ID
JOIN Likes l2
ON l1.Liker_ID = l2.Liked_ID
JOIN People p2
ON l2.Liker_ID = p2.ID
WHERE p2.Name = "Bob" AND p1.ID<>p2.ID
À nouveau, deux lignes (la première et la dernière) concernent le développeur de l'application ; toutes les autres devraient principalement être de la responsabilité du concepteur de la base de données (en tout cas si l'on considérait que celle-ci devait en effet gérer les relations).
Ce genre de requête ne pourrait tout simplement plus se faire raisonnablement si la liste des utilisateurs contenait plusieurs millions de personnes et que l'on voulait s'intéresser aux amitiés de degré 4 ou 5. Certaines bases de données incluent certes la syntaxe non-standard "CONNECT BY", comme par exemple Oracle, mais celle-ci, si elle simplifie bien l'écriture de la requête, ne simplifie en rien la complexité sous-jacente de l'exécution de la requête.
Une problématique très similaire se présente si l'on voulait répondre, dans l'exemple employeur-travailleur précédent, à la question, à nouveau relativement simple : "donner la liste de tous les anciens collègues des travailleurs d'une entreprise X" : une succession de JOINs et de multiples passages par la table "Works_for" seront nécessaires pour trouver l'entreprise de départ, tous ses travailleurs, tous les anciens employeurs de ces travailleurs, et puis enfin les travailleurs de ces employeurs.
Bases de données orientées graphe
Les systèmes de gestion bases de données relationnelles (RDBMS) sont matures, très performants dans la plupart des cas, et ont largement fait leur preuve depuis 30 ans. Il n'y a aucun doute sur le fait qu'elles géreront encore à juste titre la grande majorité des données dans les années à venir. Mais elles connaissent un certain nombre de limitations, et une nouvelle famille de bases de données, dites NoSQL (pour Not Only SQL) essaye depuis quelques années de répondre aux faiblesses des RDBMS. La famille NoSQL se divise principalement en quatre sous familles : "Key-value", "Column", "Document", et "Graph databases". C'est cette dernière famille qui nous intéresse ici, et qui a émergé sur le constat suivant :
"Facebook, for example, was founded on the idea that while there’s value in discrete information about people—their names, what they do, etc.—there’s even more value in the relationships between them."1
Les bases de données orientées graphes (ou graph databases), qui s'intéressent à la modélisation de données dans lesquelles les relations sont au cœur du métier, ont un double objectif :
- Offrir un langage de requêtage (querying language) dans lequel le développeur décrit les relations qu'il veut rechercher, sans devoir se préoccuper de la façon dont ces relations sont implémentées;
- Mettre en place un moteur particulièrement efficace pour gérer le parcours des relations (en opposition avec le mécanisme de "Join" des RDBMS, réputé lourd, en particulier lorsqu'ils sont multiples).
Pour en donner un avant-goût, en Cypher, le langage de requêtage de Neo4j2, un des leaders des bases de données orientées graphes, la requête ci-dessus exprimant la relation d'amitié de degré 2 s'écrira de la façon suivante :
MATCH (p1:Person {Name:"Bob"} ) -[:Likes*2]-> (p2:Person)
WHERE p1 <> p2
RETURN p2.Name
Historiquement, les bases de données relationnelles ont été introduites pour combler les lacunes des bases de données hiérarchiques et réseaux. On les a appelé "relationnelles" parce que, dans le contexte de l'époque, elle permettaient de mieux représenter les relations. Il peut sembler ironique qu'à l'heure actuelle, on revienne à des organisations en réseau parce qu'avec l'évolution de la technologie, on estime aujourd'hui que les bases de données relationnelles ne représentent pas bien les relations...
Conclusion
Les quelques exemples ci-dessus ont eu pour but de montrer que, si on veut mettre au cœur d'une analyse les relations entre des entités plutôt que ces entités elles-mêmes, les bases de données relationnelles ne sont pas forcément le meilleur candidat. Elles ont d'une part l'inconvénient de repousser au développeur de l'application l'implémentation des relations, et d'autre part de nécessiter l'exécution d'une machinerie très lourde.
Dans un prochain article, nous expliquerons plus en détails comment fonctionne une base de données orientées graphe (en particulier Neo4j2), et comment elles peuvent répondre aux problématiques détaillées ci-dessus. Il va de soi que les bases de données orientées graphes ne sont pas un remplaçant universel des bases de données relationnelles, et ne sont pas du tout adéquates dans un certain nombre de circonstances. Mais nous verrons qu'elles peuvent être très complémentaires aux RDBMS, en les surpassent largement, dans certains cas spécifiques, tant en termes de performances qu'en terme de lisibilité ou d'expressivité.
Références
- Graph Databases, New opportunities for connected data ; Ian Robinson, Jim Webber & Emil Eifrem ; O’Reilly, 2015. http://graphdatabases.com/
- www.neo4j.com