Le web scraping : utile pour l’eGov ?
Le web scraping, parfois appelé web crawling ou web harvesting, reprend toutes les techniques d’extraction de contenu sur des sites web, au moyen d’outils (scripts, programmes, plugins…) dans le but de son utilisation dans un autre contexte. Cette extraction se fera sans que des outils dédiés aient été proposés par les propriétaires du site web, comme des APIs (comme celles proposées par Facebook, Twitter, Wikipedia) ou des flux RSS.
Ceci ne veut pas dire que l’extraction de contenu est nécessairement non désirée par les propriétaires : les moteurs de recherches tels que Google, Bing et autres, ne sont rien d’autre que des crawlers. Il y a de nombreux autres exemples où le web scraping ne pose aucun préjudice au propriétaire : le ministère de l’économie, en Belgique, utilise par exemple le web scraping pour collecter des prix de différents articles de façon à calculer l’indice des prix à la consommation.
La question est cependant éminemment sensible, a fortiori quand il s’agit de données personnelles. Le ministère de finances, toujours en Belgique, ne se cache pas de chasser la fraude sur les sites comme Uber ou Airbnb :
(…) nous obtenions les données pertinentes concernant l’économie partagée au moyen de scripts, soit des petits programmes développés par le SPF Finances lui-même.
Nous reviendrons plus bas sur ces aspects éthiques ou juridiques, et allons dans un premier temps nous concentrer sur des considérations plus techniques.
Plus de détails peuvent être trouvés dans notre webinaire donné en juin 2020 (présentation ; vidéo)
Du web scraping… pour quoi faire?
Collecter de l’information n’est pas une fin en soi. De nombreux acteurs s’en servent pour agréger de l’information de plusieurs plateformes pour en proposer des comparateurs (voyages, hôtels, immobilier…). Plusieurs d’entre eux ont été condamnés pour ça (Immoweb vs Wegener), d’autres plaintes n’ont pas abouti (Ryanair vs Opodo).
Dans le secteur public, il peut être intéressant, comme le fait le SPF finance (voir plus haut) de faire correspondre ses propres données aux données glanées sur le web. Prenons un exemple simple : un organisme publique s’intéressant aux restaurants (en Belgique, ce pourrait être la police, l’ONSS, le Fisc, l’AFSCA, l’INASTI, …) pourrait agir de la sorte :
- Collecter une liste de restaurants dans une zone définie, sur un site comme resto.be, deliveroo, tripadvisor, …, avec un nom, une adresse et éventuellement d’autres informations annexes (note de popularité, …)
- Extraire une liste similaire provenant de ses propres données, ou d’une source authentique, comme la Banque Carrefour des Entreprises (CBE).
- Tenter d’établir un lien entre chaque ligne de la première liste avec une ligne de la seconde.
La première opération est le web scraping. La seconde, qui lui donne tout son sens, est communément appelée “l’entity linking”, ou le “record linkage”. 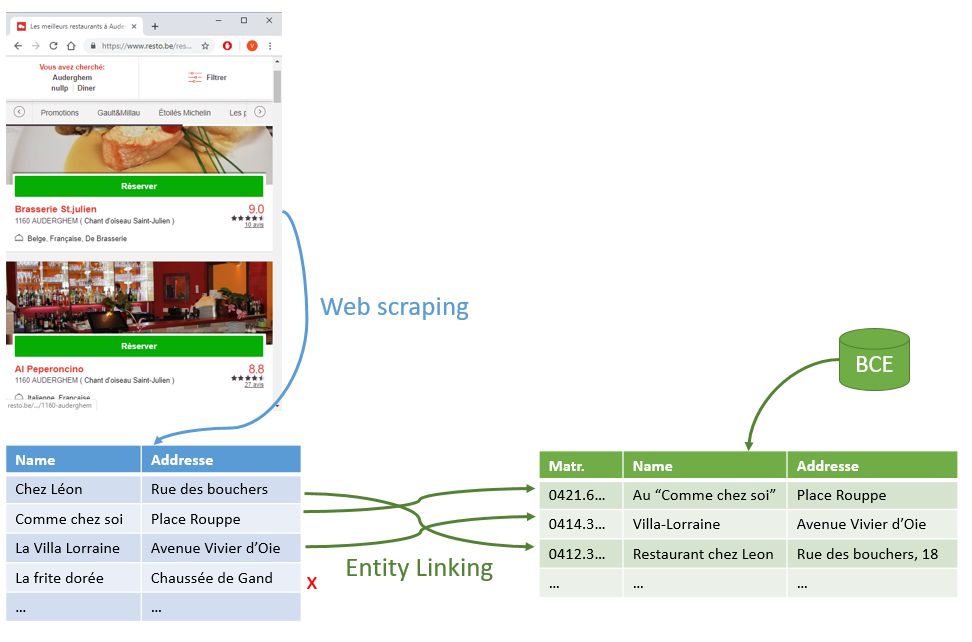
Web scraping
Du point de vue du “web scraper”, il existe principalement deux types de sites web : ceux qui sont “orientés HTML”, et ceux qui sont “orientés Javascript”.
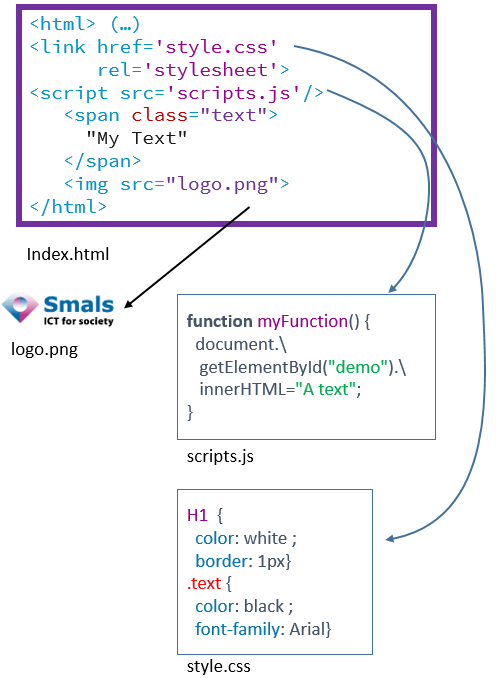 Dans le premier cas, le code source (HTML) envoyé par le serveur web contient toutes les informations que l’on veut extraire. Le site en question peut utiliser du Javascript, typiquement pour améliorer l’expérience utilisateur, mais son exécution n’est pas nécessaire pour obtenir le contenu. Le code HTML peut également appeler à l’inclusion d’images ou de feuilles de style CSS, mais à nouveau, celles-ci n’ont qu’un but esthétique, et n’ont donc pas besoin d’être chargées pour extraire le contenu désiré.
Dans le premier cas, le code source (HTML) envoyé par le serveur web contient toutes les informations que l’on veut extraire. Le site en question peut utiliser du Javascript, typiquement pour améliorer l’expérience utilisateur, mais son exécution n’est pas nécessaire pour obtenir le contenu. Le code HTML peut également appeler à l’inclusion d’images ou de feuilles de style CSS, mais à nouveau, celles-ci n’ont qu’un but esthétique, et n’ont donc pas besoin d’être chargées pour extraire le contenu désiré.
Un outil comme Scrapy (framework Python pour le web scraping) permet de collecter facilement (relativement peu de code à écrire) et efficacement (Scrapy se charge de gérer les chargements des pages, évite les doublons, limite de débit, parse le code HTML…). Certaines extensions de Chrome, comme webscraper.io le permettent encore plus facilement, mais avec moins de flexibilité.
En utilisant Scrapy, avec relativement peu de code, nous avons pu rapidement extraire une liste de restaurants sur Bruxelles (nom + adresse) sur resto.be (~1 500 restaurants), Tripadvisor (~2700) ou Deliveroo.be (~700).
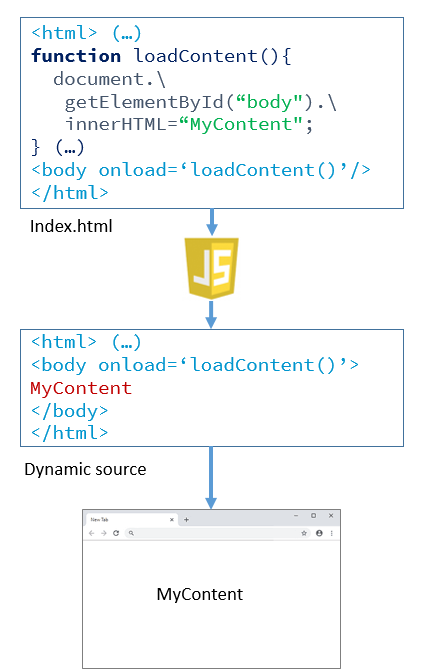 De l’autre côté, les site web “orientés Javascript” vont renvoyer des pages qui contiennent principalement du Javascript, qui lui-même va, dynamiquement, charger tout le contenu à afficher. Il est donc nécessaire d’exécuter le Javascript, ce qui nécessite en général de simuler le comportement d’un utilisateur, en automatisant l’utilisation d’un navigateur (qui chargera du coup également les images, feuilles de style, et autres scripts). Des sites comme Facebook ou Google adoptent cette technologie, qui complique fortement le web scraping. On pourra alors utiliser un outil comme Selenium. En 2014 – avant le scandale de Cambrige Analytica – , nous avions détaillé comme Selenium permettait de collecter une grande quantité d’information sur Facebook.
De l’autre côté, les site web “orientés Javascript” vont renvoyer des pages qui contiennent principalement du Javascript, qui lui-même va, dynamiquement, charger tout le contenu à afficher. Il est donc nécessaire d’exécuter le Javascript, ce qui nécessite en général de simuler le comportement d’un utilisateur, en automatisant l’utilisation d’un navigateur (qui chargera du coup également les images, feuilles de style, et autres scripts). Des sites comme Facebook ou Google adoptent cette technologie, qui complique fortement le web scraping. On pourra alors utiliser un outil comme Selenium. En 2014 – avant le scandale de Cambrige Analytica – , nous avions détaillé comme Selenium permettait de collecter une grande quantité d’information sur Facebook.
Entity linking
Idéalement, l’entity linking se fait en comparant chaque enregistrement d’une liste avec chaque enregistrement de l’autre. Pour chaque comparaison, on regardera typiquement si le nom est similaire (en utilisant par exemple une distance de Levenshtein), et ou si l’adresse, après nettoyage avec une API comme OpenStreetMap (cf notre article à ce sujet) est identique ou presque. Dans la pratique, le nombre de comparaisons serait trop important : on se contente en général de grouper les enregistrement en se basant sur le code postal, ou sur différentes variantes du metaphone du nom.
Nous avons, avec la libraire recordlinkage, comparé les 1 500 restaurants trouvé sur resto.be à 140.000 entreprises (410.000 enregistrements, en tenant compte des différentes adresses et dénominations) trouvées dans les données Open Data de Banque carrefour des entreprises pour le secteur “HoReCa” à Bruxelles. Dans 71% des restaurants sur resto.be (voir plus de détails dans notre présentation), nous trouvons une équivalence dans les données de la BCE, avec une confiance élevée :
- Dans 44 % des cas, on trouve une entreprise avec la même dénomination (sans tenir compte de différences mineures comme les accents, majuscules ou ponctuation), à la même adresse
- Dans 15 % des cas, on trouve, à la même adresse, une entreprise avec un nom similaire (par exemple “Mille délices” vs “Aux mille délices”, ou “La cité du Tigre – Bruxelles” vs “La cité du Tigre”.
Dans 10 % des cas, on trouve quelque chose, mais avec un degré de confiance insuffisant pour affirmer mécaniquement qu’il s’agit d’une correspondance. En général, il est facile de vérifier humainement si la correspondance est correcte ou pas. Et dans 18 % des cas, rien n’a été trouvé. On a souvent (11 %) trouvé une ou plusieurs entreprises à l’adresse mentionnée, mais aucune portant un nom approchant.
Nous avons pu conclure lors de notre expérience que d’un point de vue technique, la combinaison web scraping + entity linking, dans le cas des restaurants (secteur particulièrement visible en ligne) est efficace. Reste à s’assurer qu’elle est légitime et morale.
Aspects juridiques et éthiques
Chez Smals Research, nous sommes des spécialistes de l’informatique, pas du droit ! Nous ne pouvons que donner quelques éléments ici, mais une analyse pas des experts en la matière est nécessaire avant de démarrer le moindre projet.
Premier élément : le web scraping va presque systématiquement à l’encontre des “conditions générales d’utilisation”. Celles de resto.be, par exemple, stipulent que “le contenu (…) est protégé par un droit sui generis qui (…) interdi[t] toute extraction et/ou réutilisation (…) de ce contenu. “.
Est-ce un problème ? Les avis divergent. La jurisprudence américaine semble estimer que l’on n’est pas soumis aux conditions d’utilisation avant de les avoir expressément acceptées (par exemple en créant un compte). Certains juristes que nous avons contactés estiment cependant que l’on y est soumis dès que l’on navigue sur un site web.
Mais dans la pratique, il semble que le web scraping en tant que tel n’est pas condamné, mais uniquement l’utilisation commercial des données qui en découlent, qui enfreint le droit à la propriété intellectuelle et le droit de la concurrence.
Reste bien sûr l’épineuse question du RGPD : les données collectées sont-elles personnelles ? L’auteur du web scraping y est-il soumis ? Les sociétés privées n’y sont par exemple pas contraintes de la même façon que des services étatiques d’enquête ou de renseignement.
Pour conclure
La petite expérience que nous avons menée nous a permis de nous rendre compte que le web scraping était une technique accessible, nécessitant dans un premier temps relativement peu de moyens, en tout cas pour collecter des données sur des sites simples et bien structurés. Cela nécessite cependant pas mal de “bricolage” (par exemple pour pouvoir déterminer de façon fiable l’emplacement d’une page où se trouve le nom d’un restaurant), avec aucune garantie de stabilité. En effet, les sites web évoluent, et un script qui marche un jour peut très bien ne plus du tout marcher le lendemain, même si aucune évolution visible pour l’utilisateur classique n’est intervenue.
Notons que nous avons considéré ici un cas simple : on extrait des données de sites bien structurés, qui contiennent des “listes” des entités qui nous intéressent, chaque élément (nom, adresse…) étant facilement identifiable. S’il était nécessaire, par exemple, d’aller explorer le site web de chaque restaurant pour y trouver des adresses ou des numéros d’entreprise, la tâche serait autrement plus ardue.
En dehors de l’aspect technique, il nous parait essentiel de ne pas démarrer un projet de web scraping s’il n’est pas “blindé” juridiquement. Au risque de devoir l’abandonner complètement avant sa mise en production, voire pire, de faire l’objet de poursuites en justice. Que ce soit de la part du site web visé, ou des personnes dont on aurait collecté les données.
Par ailleurs, la collecte ne doit jamais être la finalité, il conviendra d’abord d’évaluer ce qu’on comptera faire des données. Et de ne collecter, du coup, que ce qui est strictement nécessaire à la finalité.