Les graphes de connaissance : quelques applications
Le blog « Les graphes de connaissance, incontournable pour l'intelligence artificielle » publié précédemment sur ce site introduisait les « knowledge graphs » (ou graphes de connaissance) ainsi que leur potentiel. On poursuit ici en s’intéressant à quelques applications concrètes qui peuvent aider à identifier des use cases intéressants pour notre organisation.
La recherche sémantique
C’est une des premières applications du KG (graphe de connaissance), ce concept a été lancé par Google.
Dans une recherche classique, on se base sur le calcul de similarité entre les termes introduits par l’utilisateur et le contenu des documents pour identifier les documents pertinents.
Dans une recherche sémantique, on identifie le concept ou l'intention dans la requête de l’utilisateur, ce qui permet de retrouver rapidement l’information. Les entités sont extraites de la requête de l’utilisateur pour interroger le KG. La construction de ce KG passe par l’étiquetage sémantique des documents, l’extraction de métadonnées, l’extraction d’entités, la désambiguïsation et l’extraction de liens entre les entités et l’enrichissement sur base de KG externes.
L’avantage de l’utilisation du KG est d’augmenter la pertinence des résultats grâce entre autres à :
- L’utilisation de synonymes
- La complétion automatique de la requête (suggestion)
- La recherche sur des données structurées et connectées. On dispose en outre, via une fiche info, d’une information additionnelle, factuelle et contextuelle. Celle-ci peut aussi contenir des liens permettant de naviguer facilement vers d’autres concepts ou d’autres sources.
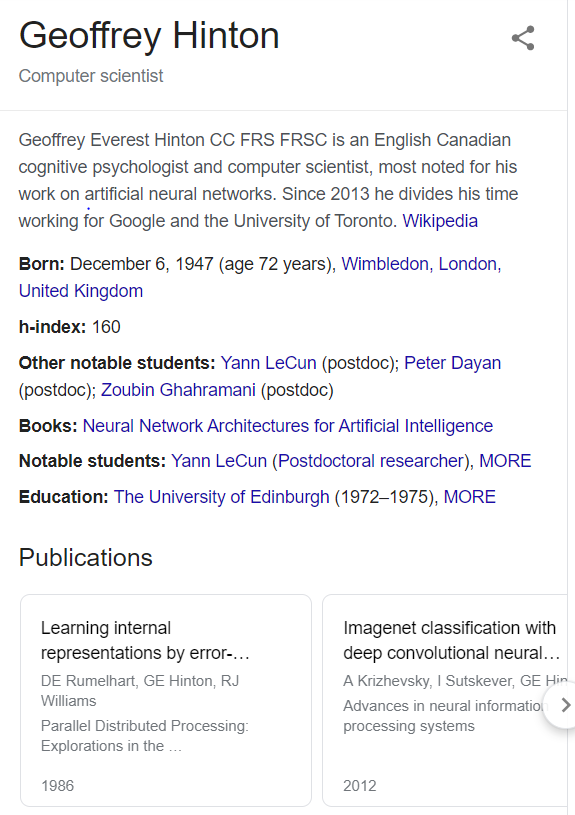
Exemple de fiche info affichée dans le moteur de recherche Google pour la requête "Geoffrey Hinton" (chercheur en IA et un des parrains du deep learning).
Les chatbots
Dans un chatbot, les requêtes des utilisateurs sont introduites en langage naturel. Le défi consiste alors à avoir une interprétation correcte de la question par la machine et de donner ensuite la bonne réponse à l’utilisateur.
Le KG apporte une information contextualisée qui est utilisée pour mieux comprendre la requête de l’utilisateur et guider la conversation en demandant si nécessaire plus d’informations à l’utilisateur. Par exemple, l’utilisateur pourrait poser la question « j’aimerais des chaussures Nike pointure 42 ». Le contexte ici est «chaussures de sport » et le chatbot répondrait alors à l’utilisateur « pour quelle utilisation ?» en proposant les options running ou fitness qui sont des attributs du produit stockés dans le KG. Une question telle que « j’aimerais des bottes » déclencherait la question « quelle couleur ? ». En outre, il est facile d’intégrer de nouvelles informations et donc de nouvelles réponses dans le graphe sans nécessairement ajouter une nouvelle intention au chatbot.
Dans le contexte de l’e-commerce, le KG est construit sur base des interactions passées avec les utilisateurs et enrichi avec les caractéristiques du produit.
Les systèmes de recommandation
Un système de recommandation permet de présenter à l’utilisateur un produit, une information susceptible de l’intéresser. Dans un modèle de recommandation objet (content based), on définit un profil pour chaque objet. Le système propose alors à l’utilisateur des objets aux profils similaires (« vous aimeriez aussi… ») à l’objet d’intérêt. Dans une approche dite sociale « collaborative filtering », c’est l’utilisateur qui est modelé. Les suggestions sont filtrées sur base des choix d’utilisateurs ayant le même profil. Ces modèles sont établis sur la base d’information récoltées sur les comportements et les actions passées d’utilisateurs aux profils variés.
Les KG sont utilisés pour augmenter les systèmes de recommandations. On capture dans le graphe les objets et leurs attributs, les utilisateurs et leurs préférences ainsi que les liens entre ces différents éléments. L’intégration des KG aux systèmes de recommandations présente deux avantages principaux :
- L’explicabilité grâce à l’analyse de la connectivité entre objets et utilisateurs (voir Figure 1) dans le KG; retracer le chemin entre l’utilisateur et l’objet permet de comprendre quel(s) élément(s) a/ont été déterminant(s) pour une recommandation donnée. Cet élément est important lorsque les systèmes de recommandation sont utilisés dans le domaine de la santé (Health recommender system).
- Le problème du « cold start » quand il y a peu de données disponibles pour la construction d’un modèle, ce qui arrive quand un nouveau produit ou un nouveau type d’utilisateur est introduit. On exploite alors l’information du KG.
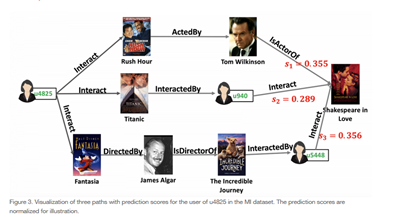
Figure 1. Trois chemins ou propositions d’explication de la recommandation du film Shakespeare in Love à l’utilisatrice u4825 . Dans le premier chemin, on constate que l’utilisatrice a regardé le film Rush Hour dans lequel joue l’acteur Tom Wilkinson. Ce dernier joue aussi dans le film Shakespeare in Love d’où la recommandation de ce film à l’utilisatrice (source https://tech.ebayinc.com/research/explainable-reasoning-over-knowledge-…).
Customer 360 (data analytics)
Cela consiste à avoir une vue holistique sur les données d’entreprise relatives à un client. Les données d’entreprise sont généralement compartimentées en silos. Elles se retrouvent sous forme structurée ou non structurée, et proviennent de multiples sources telles que les bases de données, les fichiers Excel, Sharepoint, etc. Grâce aux KG on peut intégrer et connecter ces données, ce qui permet de visualiser une entité sur plusieurs dimensions. De plus, la visualisation sous forme de graphe est beaucoup plus « naturelle » pour l’utilisateur. L’exemple donné ici se rapporte au client car c’est une des applications les plus courantes mais ce concept pourrait tout aussi bien s’appliquer à d’autres entités telles que le patient ou l’entreprise.
Catalogue de données ou « data catalog »
Le catalogue de données est un système facilement consultable dans lequel sont inventoriées toutes les données que possède une organisation (voir aussi https://data.world/blog/what-is-a-data-catalog/).
Il y a deux raisons importantes pour l’adoption d’un catalogue de données :
- Les exigences du RGPD. On doit pouvoir tracer le cycle de vie d’une donnée ainsi que son origine.
- L’adoption de projets d’intelligence artificielle et de data analytics. C’est sur ces derniers que le KG est particulièrement utile car il permet d’explorer les liens entre les données souvent réparties en silos ; on apporte une couche de connaissance au-dessus des données.
Le KG contient des informations sur les données (métadonnées) ainsi que les relations entre des données souvent hétérogènes et organisées en silos. La structure graphe est flexible et permet d’intégrer facilement de nouveaux types de données. En outre, ce modèle est facilement lisible aussi bien pour la machine que pour l’humain.
Conclusion
Les quelques applications de graphe de connaissance abordées ici sont liées à l’industrie mais ces concepts peuvent aussi s’appliquer au secteur public. Le « customer 360 » deviendrait « l’employeur 360 », l’adoption du KG dans un chatbot permettrait de gérer plus facilement la complexité administrative et de mieux guider le citoyen dans sa requête. Et enfin, un catalogue de données graphe pourrait permettre de valoriser les données pour des applications innovantes à destination du citoyen (voir https://turkucitydata.fi/#what-we-do).
Ce post est une contribution individuelle de Katy Fokou, spécialisée en intelligence artificielle chez Smals Research. Cet article est écrit en son nom propre et n'impacte en rien le point de vue de Smals.