PII Filtering – door ******* uit *****
De populariteit van AI-toepassingen met chat-interface, doet een “oud zeer” opnieuw bovendrijven: hoe beschermen we persoonsgegevens die, vaak nietsvermoedend, via chat worden meegedeeld aan een geautomatiseerd systeem? Bij uitbreiding stelt zich deze vraag voor elke toepassing waar persoonsgebonden gegevens gedeeld moeten worden met derde partijen. De externe afhankelijkheden van een toepassing kunnen echter een ingewikkeld kluwen zijn. Het is ook niet altijd mogelijk (of economisch haalbaar) om de grote spelers op het vlak van cloud- en AI-diensten te ontwijken – toch niet als je mee wil zijn met de nieuwste mogelijkheden op een kostenefficiënte manier.
Een mogelijke oplossing staat bekend als PII Filtering. PII is daarbij het Engels acroniem voor Personal(ly) Identifiable/Identifying Information, i.e. de informatie waarmee iemand geïdentificeerd kan worden. Het idee is eenvoudig genoeg: we plaatsen een extra filter voor de applicatie, die de persoonlijke gegevens uit de input filtert, voordat die input aan de applicatie wordt doorgegeven. Als dat goed lukt, dan maakt het in principe niet meer uit wat de applicatie achter de schermen met die gegevens doet.
PII vs. Personal Data
Het is allereerst cruciaal om te begrijpen dat “PII” niet gelijkgesteld kan worden aan “Personal Data” zoals de GDPR en andere Europese wetgeving die definieert. PII is een concept dat geworteld is in Amerikaanse wetgeving. Het doelt meestal op een eindige set identificatiegegevens die kunnen worden gebruikt om de identiteit van een individu te onderscheiden of te achterhalen, zoals rijksregisternummers, adressen en telefoonnummers. Amerikaanse regelgeving is op dat vlak vaak prescriptief van aard: zo bevat de HIPAA (privacywetgeving m.b.t. gezondheidsgegevens) een lijst met 18 identifiers die als PII worden gedefinieerd. Dat heeft als groot voordeel dat het relatief gemakkelijk te implementeren is: wanneer het lijstje helemaal afgevinkt kan worden, is er ook juridisch weinig discussie meer.
Daarentegen hanteert de Europese GDPR (AVG) een principiële benadering: ze definieert een breder concept van Personal Data (persoonsgegevens). Dat omvat “alle informatie met betrekking tot een geïdentificeerde of identificeerbare natuurlijke persoon”. Dit betekent dat zelfs schijnbaar onschuldige informatie, zoals de kleur “rood”, beschouwd kan worden als persoonsgegeven, als deze bijvoorbeeld betrekking heeft tot iemands lievelingskleur. Deze contextafhankelijke definitie van persoonsgegevens, maakt het echter ook nagenoeg onmogelijk om generieke, algemeen inzetbare detectoren of filters ervoor te ontwikkelen. Wat beschouwd wordt als persoonsgegeven of niet, moet geval per geval beoordeeld worden. Niet alleen ontwikkelaars worden daardoor geconfronteerd met meer maatwerk dan hen lief is, ook juristen, DPO’s en Gegevensbeschermingsautoriteiten hebben met zulke beoordelingen in elk EU-land de handen vol.
Oplossingen voor PII-filtering die voldoen voor gebruik in de VS, lopen dus altijd een risico om in de EU slechts gedeeltelijk tegemoet te komen aan de vereisten. Omdat de term PII echter algemeen ingang gevonden lijkt te hebben in de globale markt, spreken we verder in dit artikel enkel nog over PII. Houd wel permanent in het achterhoofd dat Personal Data altijd het uitgangspunt moet zijn in EU-context.
PII Detectie en Filtering
Om tekstuele input te filteren gebruiken we doorgaans patroonherkenningstechnieken en Natural Language Processing (NLP)-modellen. Deze modellen scannen ongestructureerde gegevens, op zoek naar patronen zoals e-mailformaten of numerieke reeksen die lijken op rijksregister- of telefoonnummers, om deze nadien te kunnen redigeren of anonimiseren. Daarnaast worden aangepaste regex-patronen vaak toegevoegd om vormen van gevoelige informatie te herkennen die specifiek zijn voor de betrokken toepassing.
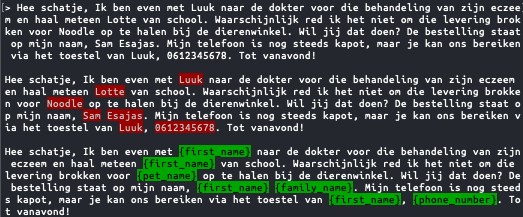
Effectieve PII-filtering steunt sterk op Named Entity Recognition (NER), een NLP-methode die entiteiten zoals namen, data en locaties in een tekst identificeert. We publiceerden daar eerder al over in meer detail – zie deze artikels over NLP en NER. De opkomst van generatieve AI heeft aan de opzet van NER-technieken nog niet veel veranderd. Ook vandaag gebruiken veel PII filtering tools achterliggend goed ontwikkelde NLP-toolkits zoals NLTK, SpaCy of Flair.
PII kan echter ook in afbeeldingen opduiken: scans van documenten, foto’s van gezichten of nummerplaten, … Om dat weg te filteren is een geavanceerdere aanpak vereist, omdat de gevoelige gegevens kunnen verschijnen in uiteenlopende vormen, van handgeschreven notities tot reflecties in foto’s. Optical Character Recognition (OCR) wordt gebruikt om tekst uit afbeeldingen te extraheren en deze om te zetten in een formaat dat op dezelfde manier kan worden geanalyseerd als tekstuele gegevens. Zodra de tekst is geëxtraheerd, ondergaat deze hetzelfde PII-filterproces met behulp van NLP-technieken. In gevallen waarin de afbeelding zelf gevoelige visuele elementen bevat (zoals gezichten of persoonlijke documenten), worden algoritmen voor beeldherkenning gebruikt om dergelijke inhoud te herkennen.
Eenmaal geïdentificeerd, moet je besluiten wat er dient te gebeuren met de gedetecteerde PII. Opties kunnen zijn:
- Vervanging / substitutie door een andere waarde. Deze kan eventueel aangemaakt worden met een synthetic data tool, zodat het origineel vervangen wordt door een realistisch ogend alternatief.
- Masking / obfuscation: vervang door een karakter of balkje. Dit kan eventueel gedeeltelijk, om nuttige algemenere info niet te verliezen: zo zien we nog dat +32********* een Belgisch telefoonnummer is.
- Verwijdering
- Hashing (best met salt ter preventie van brute-force attacks)
- Encryptie, eventueel formaat-behoudend
- …



Voor afbeeldingen zijn andere functies mogelijk, waaronder:
- Vervagen (blurring) of andere filters. Hierbij moet men er wel op letten dat sommige filters omkeerbaar zijn.
- Bedekken of overschrijven, bijvoorbeeld met een zwarte rechthoek.
- …
De vervanging door een alternatieve waarde van dezelfde soort kan echter soms ook voor vreemde effecten zorgen, omdat de entiteit niet altijd correct wordt ingeschat of omdat er te weinig of geen rekening gehouden kan worden met de context. Zo kan het zijn dat sommige tools geen acht slaan op het geslacht als een willekeurige naam moet worden gekozen om een echte naam te vervangen, terwijl dat wel nodig kan zijn om grammaticaal of inhoudelijk consistent te blijven. We zien soms ook plaatsnamen zoals Sint-Niklaas geanonymiseerd worden als pakweg Sint-Kevin, omdat Niklaas als naam werd aanzien. De taalmodellen gebruikt voor NER zijn dus zeker niet feilloos.
Het zou in theorie mogelijk moeten zijn om betere resultaten te halen door recente LLMs zoals GPT-4 in te schakelen met slim geconstrueerde prompts. Waarschijnlijk zullen er binnenkort wel stappen in die richting worden gezet, maar vandaag zijn de rekenkrachtvereisten, energieconsumptie en kostprijs daarvan nog te hoog, en de responstijd te traag, om dat ook schaalbaar te maken.

Tools of the trade
Wie op zoek gaat naar grootschalige PII Filtering systemen, en volledige databases, netwerken of filesystems wil kunnen scannen, komt terecht bij Data Loss Prevention tools. Deze moeten verhinderen dat PII het bedrijf verlaat zonder de nodige toelatingen. Voor een marktoverzicht verwijzen we naar Gartner. Ook de internetgiganten bieden daarvoor oplossingen aan, zoals Amazon Macie, Google SDP, of IBM Guardium. De daarbij gebruikte technieken zijn enigszins verwant met diegene gebruikt bij forensisch onderzoek – de zogenaamde eDiscovery, waarover we ook al eerder schreven.
Applicatiebouwers zijn waarschijnlijk eerder geïnteresseerd in tools in de vorm van bibliotheken, SDK’s of API’s. Interessante projecten zijn:
- Voor tekst:
- Microsoft Presidio (demo) (ook beschikbaar als Docker containers), of de PII detection dienst op Azure
- Amazon Comprehend (demo)
- De EU Language Services voor NLP (inloggen vereist): voor anonymisering van documenten in EU-talen, gebaseerd op het MAPA-EU project dat ook via Docker Compose gebruikt kan worden.
- PIICatcher (voor databases en filesystems)
- Voor afbeeldingen:
- Google Magritte (voor gezichten)
- Meta Research EgoBlur (voor gezichten en nummerplaten)
- OctoPII (enkel detectie en geen redactie. Voor documenten en filesystems, met Tesseract als OCR engine)

Ook in academia wordt er verder onderzoek gedaan. Zo is PII-Codex het resultaat van een universitair project, met een interessante feature: achterliggend maakt het gebruik van Presidio of Comprehend, maar het voegt ook een eigen risico-score toe, die moet kunnen aangeven in welke mate het niet-redigeren van de herkende PII een (privacy-)risico zou kunnen inhouden. Daarnaast laten de meeste tools ook toe om andere of eigen modellen in te pluggen. Deze kan je eventueel zelf gefinetuned hebben voor detectie van custom entiteiten, als je daarvoor de nodige trainingsdata hebt.
Als we vertrouwen op NER of beeldherkenning voor PII-detectie, dan kunnen we er zeker van zijn dat sommige PII niet gedetecteerd zal worden, en dat ook andersom niet-PII foutief als PII aangemerkt kan worden. Geen van deze technologieën garandeert immers 100% accuraatheid. Het succespercentage zal ook variëren afhankelijk van de taal en het entiteitstype dat men probeert te detecteren. Volledige vervanging of verwijdering van elke entiteit in een document kan nooit worden gegarandeerd. Daar waar dat cruciaal is, wordt het resultaat achteraf dus best nog gecontroleerd.
Conclusie
Oplossingen voor PII-filtering kunnen in Europese context zeker bijdragen aan de bescherming van persoonsgegevens. De techniek is eenvoudig te begrijpen en gemakkelijk inzetbaar. Er is echter nooit een garantie op volledige accurate detectie van alle persoonsgegevens, en dus zal hun gebruik in de meeste gevallen een onderdeel moeten zijn van een ruimere waaier aan maatregelen om compliance met GDPR en andere wetgeving te bevorderen.
De achterliggende technologie is “klassiek”, in de zin dat NER en beeldherkenning al lang bestaan en ondertussen goed ontwikkeld zijn. Vandaag profiteren ze mee van de aandacht voor artificiële intelligentie, en allerlei benchmarks laten toe om de state-of-the-art op te volgen. In de praktijk merken we wel dat de resulterende geanonymiseerde tekst soms wat bevreemdend kan overkomen, omdat enkele al even klassieke problemen waar NER typisch mee kampt, nog altijd niet helemaal van de baan zijn.
______________________
Dit is een ingezonden bijdrage van Joachim Ganseman, IT consultant bij Smals Research. Dit artikel werd geschreven in eigen naam en neemt geen standpunt in namens Smals.