Les technologies graphes, leurs applications et leurs outils: un tour d’horizon (Partie 2)
Cet article fait suite à la Partie 1, qui présente les fondamentaux des technologies graphes, algorithmes et applications. Cette seconde partie est consacrée aux bases de données orientées graphe et aux graphes de connaissances, leurs différences et leurs outils.
Les bases de données orientées graphe
A l’instar d’une base de données relationnelle, l’objectif d’une base de données orientée graphe est de pouvoir stocker et gérer des données de manière persistante et d’effectuer des requêtes complexes. La différence étant que les données sont stockées sous la forme d’un graphe, à savoir un ensemble de nœuds interconnectés par le biais d’arcs.
Les bases de données orientées graphe ont plusieurs avantages par rapport aux bases de données relationnelles classiques, car le modèle de graphe permet une traversée simple et optimisée des données via les arcs, là où l’exploration de relations dans une base de données relationnelle peut demander un nombre important de jointures. Plus de détails sur les avantages des bases de données orientées graphe, ainsi que les cas de figure où les utiliser, se trouvent dans les articles de blog [1] et [2].
Les trois composants de toute base de données orientée graphe sont : nœuds, arcs et propriétés. Ces propriétés peuvent être placées soit sur les nœuds, soit sur les arcs, ou sur les deux. Si nous considérons le petit exemple illustratif dans la Figure 1, le nœud « Paul » peut par exemple être associé à des propriétés telles que sa date de naissance et son adresse, pour les nœuds représentant des films on peut y associer les propriétés telles que l’année de sortie, le budget et son identifiant IMDb, et sur les relations « A_VU » entre un utilisateur et un film, on pourrait associer des propriétés telles que la date de visionnage et la note (sur 5) que l’utilisateur donne au film.
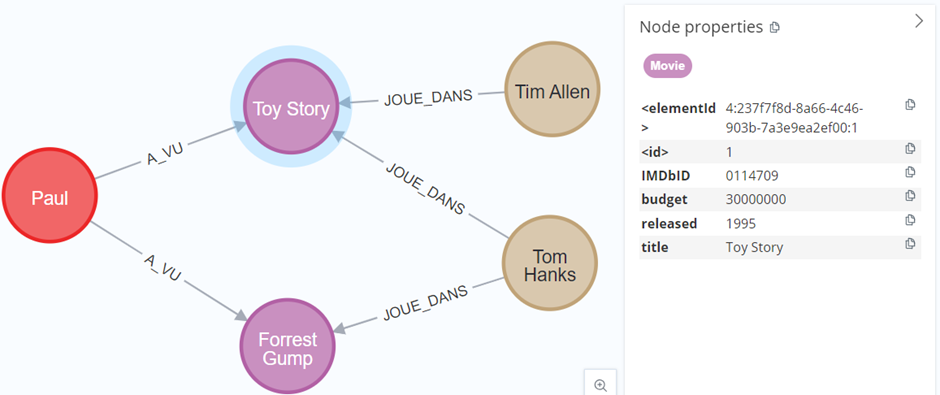
Il est à noter que les algorithmes de graphe que nous avons présentés dans la Partie 1 ne sont souvent que peu ou pas implémentés dans les logiciels de bases de données orientées graphe, à quelques exceptions près (Neo4j et TigerGraph disposent d’une libraire « Graph Data Science (GDS) » contenant plusieurs algorithmes). Il est donc généralement nécessaire d’exporter le graphe (ou une partie de celui-ci) vers un outil d’analyse.
Les outils pour bases de données orientées graphe
Passons rapidement en revue quelques-uns des outils les plus connus. Notez que tous les outils listés ci-après sont compatibles avec les propriétés ACID. Il existe un grand nombre d’outils pour la gestion de base de données graphe, cet article n’en mentionne qu’une partie. N’hésitez pas à aller jeter un coup d’œil à une liste plus détaillée trouvable ici.
- Neo4j
Neo4j offre l’avantage d’avoir un format de graphe natif, ce qui rend très efficace la traversée du graphe (et donc, les requêtes). Les requêtes se font en Cypher, un langage facile à prendre en main, et Neo4J est bien documenté et dispose d’une grande communauté. Neo4J dans sa version « community » est gratuit, mais une version payante existe (Neo4j Enterprise), et la version gratuite peut poser quelques soucis de scalabilité face à de très grandes quantités de données.
- ArangoDB
ArangoDB propose un modèle de données flexible (multi-modèle), intégrant un modèle graphe, un modèle document (basé sur des objets JSON) et un modèle clé-valeur. Il dispose de son propre langage de requêtes AQL (Arango Query Language) qui peut être plus compliqué à prendre en main que Cypher en raison du multi-modèle sous-jacent à ArangoDB. C’est un logiciel payant, bien qu’une version open source existe (community edition), mais est (évidement) plus limitée que la version payante.
- TigerGraph
TigerGraph est un outil payant, optimisé pour pouvoir être utilisés sur de très grandes bases de données. Les requêtes se font via le langage GSQL, qui est un langage permettant d’effectuer de nombreuses tâches, mais plus compliqué à prendre en main que Cypher. TigerGraph dispose de nombreux algorithmes implémentés via la librairie GDS.
- Memgraph
Memgraph est un outil particulier en ce sens qu’il stocke les données directement en mémoire (dans la RAM). Cela lui permet d’avoir des très hautes performances pour le requêtage, mais en contrepartie cela rend son utilisation difficile, ou du moins coûteuse en termes d’infrastructure, lorsque le graphe est de grande taille, puisqu’il faut avoir suffisamment de RAM que pour stocker les données. Memgraph s’utilise donc généralement lorsque les performances sont la première priorité. Les requêtes se font en Cypher.
- GraphDB
GraphDB utilise un modèle de graphe bien spécifique appelé Resource Description Framework (RDF). Ce framework, qui sera discuté un peu plus en détails dans la section relative aux graphes de connaissances, a son langage de requête propre nommé SPARQL. Il existe en version gratuite open-source (graphDB Free) et en version entreprise payante (graphDB Enterprise).
- Apache TinkerPop et ses implémentations
Il s’agit d’un framework open-source qui vise à définir un modèle de base de données graphes, ainsi qu’un langage de requête nommé « Gremlin ». Il est utilisé dans de nombreux logiciels de gestion de base de données orientées graphe, tels que JanusGraph (un logiciel open-source), Amazon Neptune qui propose d’autres modèles que celui de TinkerPop tels que RDF, ou encore des outils de gestion de base de données non spécialisés en graphe, tels qu’Azure Cosmos DB.
Les graphes de connaissances
Avant de s’intéresser aux pratiques et outils, commençons dans un premier temps par définir ce qu’est un graphe de connaissances et ce qui le distingue d’une base de données orientée graphe. Il s’agit d’un graphe qui met l’accent sur la sémantique et sur l’inférence. Chaque nœud représente un concept et chaque arc une relation. Comme nous l’avons déjà vu dans les articles de blog [3, 4], un graphe de connaissances se définit comme un graphe remplissant trois conditions [5] :
- L’intégration d’informations en provenance de différentes sources hétérogènes.
Un graphe de connaissances rassemble et combine des données issues de diverses sources (structurées ou non) de manière cohérente.
- L’utilisation d’une ontologie.
Une ontologie décrit de façon formelle les concepts et les relations présentes dans le graphe, ainsi que les éventuelles contraintes et règles. Il s’agit donc d’un modèle structuré qui fournit les fondations sémantiques afin de permettre des opérations de raisonnement et des tests de cohérence. Par exemple, un schéma d’ontologie (voir Figure 2), également appelé graphe ontologique, fournit une représentation des types d’entités et des relations d’un graphe de connaissances, fournissant ainsi une structure conceptuelle sans contenir de données spécifiques.
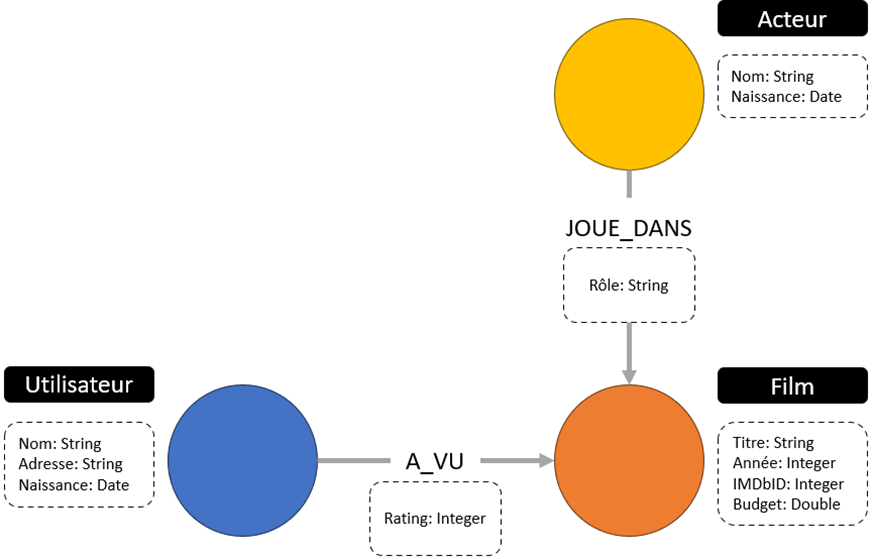
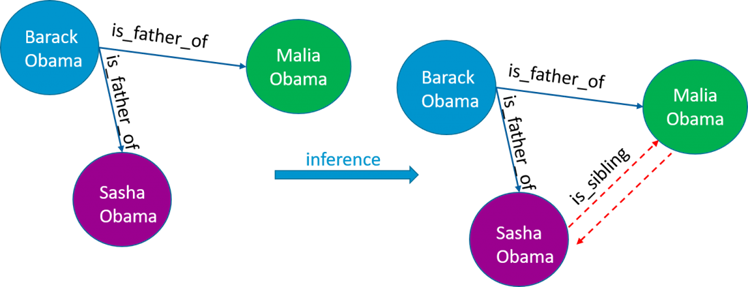
- L’inférence d’informations implicites sur base d’informations explicites.
Il est possible de trouver des informations qui n’étaient pas présentes dans les données initiales sur base de règles d’inférence (Voir Figure 3).
Un aperçu du modèle RDF (Resource Description Framework)
Initialement conçu pour la description formelle de ressources web et leurs métadonnées, le modèle RDF est fréquemment utilisé pour les graphes de connaissances car il permet un raisonnement sémantique robuste et une très grande interopérabilité.
Un document en RDF prend la forme d’un ensemble de triplets RDF, chaque triplet est une association : sujet (ressource à décrire), prédicat (propriété de la ressource), objet (donnée ou autre ressource).
Par exemple :
:Alice :knows :Bob .
:Alice :livesIn :Paris .
:Alice :age 30 .
Ces triplets représentent donc aussi bien des relations entre nœuds (par exemple : la relation entre Alice et Bob) que des propriétés (l’âge d’Alice).
Une spécificité de RDF est qu’il nécessite que chaque élément d’un triplet (à l’exception de l’objet s’il s’agit d’une valeur simple, tel que la valeur 30 pour l’âge d’Alice) soit identifié par un URI (Uniform Resource Identifier) ou IRI (Internationalized Resource Identifier). Cela permet une grande interopérabilité car cela évite la création de doublons lorsque plusieurs sources d’information sont combinées. Si nous reprenons les triplets utilisés précédemment, nous obtenons le fragment suivant (en langage turtle) :
<http://example.org/Alice> <http://example.org/knows> <http://example.org/Bob> .
<http://example.org/Alice> <http://example.org/livesIn> <http://example.org/Paris> .
<http://example.org/Alice> <http://example.org/age> "30"^^<http://www.w3.org/2001/XMLSchema#integer> .
L’utilisation de RDF implique donc d’avoir un URI afin de pouvoir identifier tous les concepts (sujets, prédicats et objets) du graphe à l’instar d’une clé primaire dans les bases de données relationnelles.
De plus, il existe deux outils permettant d’ajouter de la signification sémantique aux données RDF, en décrivant les relations afin de permettre le raisonnement, à savoir RDFS (RDF Schema) et OWL (Web Ontology Language). Comme nous l’avons vu, RDF impose que chaque concept soit identifié par un URI. RDFS et OWL fournissent un ensemble prédéfini d’URI pour des concepts fréquemment utilisés, auxquels on peut faire référence dans RDF. Ceci permet d’une part d’avoir un vocabulaire commun standardisé, ce qui facilite l’intégration d’autres bases de données, et d’autre part d’établir des règles d’inférence. En effet, puisque OWL et RDFS proposent des concepts standardisés, cela permet à des « raisonneurs » basés sur OWL (tels que FaCT++ ou HermiT) d’inférer les relations implicites de façon systématique ou de détecter des contradictions, sur base de l’ontologie.
Les requêtes sur une base de données RDF se font via SPARQL.
Les alternatives à RDF, et les outils pour travailler avec un graphe de connaissances
Bien évidemment, un graphe de connaissances ne nécessite pas forcément l’utilisation du modèle RDF. Un graphe sera considéré comme graphe de connaissances tant que les 3 conditions décrites en début de section sur les graphes de connaissances sont remplies. Il est donc parfaitement possible de créer un graphe de connaissances dans un outil classique de gestion de base de données orientée graphe, tant que l’implémentation combine des données de plusieurs sources, qu’elle est conforme à une ontologie et qu’elle peut être utilisée pour de l’inférence sémantique.
La principale force du modèle RDF est son niveau de standardisation élevé. D’une part, via son exigence d’identification par URI, ainsi que son vocabulaire et son langage de requête standardisés, elle permet une haute interopérabilité. D’autre part, les extension RDFS et OWL permettent d’offrir une richesse sémantique rendant possible un raisonnement automatique. En contrepartie, sa complexité limite son adoption dans des applications business où cette rigueur sémantique n’est pas forcément nécessaire et où l’utilisation d’un modèle de graphe plus simple (tel que Neo4j ou TigerGraph) suffit. L’utilisation de modèles plus simples offre l’avantage d’être plus facile et rapide à mettre en place et d’offrir des performances de requêtage optimisées, mais au prix de la perte de la richesse sémantique offerte par RDF.
Cette section présente des outils (de façon non exhaustive) relatifs à RDF mais, comme mentionné, les outils précédemment cités pour les bases de données orientées graphe restent valides pour créer un graphe de connaissances tant que les conditions sont remplies.
Voici une liste de quelques outils liés aux graphes de connaissances en RDF :
- La conception d’ontologies : l’outil open-source Protégé est fréquemment utilisé pour créer des ontologies. Le site schema.org fournit un grand nombre de schéma et vocabulaires standards pour différents domaines, mais est généralement plutôt utilisé pour des graphes de connaissances relatifs aux données web.
- La transformation de données vers RDF : l’outil R2RML permet de transformer des données relationnelles vers RDF. Nous pouvons aussi mentionner D2RQ, qui donne accès à une base de données relationnelle via un graphe de connaissances RDF virtuel.
- Le stockage de données : en plus des solutions mentionnées précédemment (GraphDB et Amazon Neptune), nous pouvons aussi mentionner BlazeGraph et Apache Jena (open-source) ou encore Stardog et AllegroGraph (solutions commerciales).
- Les raisonneurs OWL : il existe de nombreux raisonneurs OWL. Tous ne sont cependant pas forcément activement maintenus ou toujours utilisables. La liste de raisonneurs OWL la plus récente que nous ayons pu trouver date de 2023 et est accessible ici [6].
Terminons par mentionner le framework RDF4J (framework Java) et rdflib (libraire python) permettant d’interagir avec des données RDF.
Conclusion
Terminons par une rapide synthèse des concepts clés qui séparent un graphe mathématique d’une base de données orientée graphe et d’un graphe de connaissances.
Un graphe mathématique est un ensemble de nœuds et d’arcs facilement représentable sous forme matricielle afin d’y appliquer des algorithmes. C’est la structure sous-jacente de toute base de données orientée graphe ou graphe de connaissances.
Une base de données graphe comporte un ensemble de nœuds, d’arcs et de propriétés. L’accent est mis sur le stockage de grandes quantités de données au sein d’une structure graphe et sur l’optimisation du requêtage.
Un graphe de connaissances a pour but de représenter le savoir au sein d’un graphe mettant l’accent sur :
- La sémantique : Le graphe suit une ontologie et les relations ont une signification.
- L’intégration : Diverses sources de données sont liées dans un graphe unifié.
- L’inférence : La capacité à dériver des connaissances via un raisonnement.
Il est donc concentré sur l’intégration et l’enrichissement sémantique des données.
Il va sans dire que cet article ne fait qu’effleurer la surface de la vaste littérature des graphes et leurs applications diverses, et que nombreux points mériteraient un développement plus poussé et feront d’ailleurs sans doute l’objet de futurs articles.
Références
[2] Sept (bonnes) raisons d’utiliser une Graph Database
[3] Les graphes de connaissance, incontournable pour l’intelligence artificielle
[4] Smals KG Checklist: déterminer si un graphe de connaissances peut résoudre un problème concret
[5] Ehrlinger, L., & Wöß, W. (2016). Towards a definition of knowledge graphs. SEMANTiCS 2016, 48(1-4), 2.
[6] Abitch, K., (2023). “OWL Reasoners still useable in 2023”
Ce post est une contribution individuelle de Pierre Leleux, data scientist et network data analyst chez Smals Research. Cet article est écrit en son nom propre et n’impacte en rien le point de vue de Smals.