Komt de AI-tolk eraan?
Snel een tekstje vertalen is de laatste jaren een makkie geworden, zeker als 100% accuraatheid niet hoeft - met dank aan Google/Bing Translate, Deepl, of de speciaal voor publieke administraties ontwikkelde eTranslation tool van de EU. Voor professionele vertalers verandert de snelle opkomst van zulke technologieën hun jobinhoud. Vertaalmotoren gebaseerd op neurale netwerken (zie ook een vorige blogpost) krijgen een plek in professionele CAT-omgevingen (Computer Assisted Translation), naast reeds bestaande hulpmiddelen zoals de Translation Memories, waarmee eerder gemaakte vertalingen hergebruikt kunnen worden. Zo verschuift de taak van de vertaler meer richting supervisie: nalezen en corrigeren waar nodig, en tussenkomen op vlakken waar vertaalmotoren problemen hebben: homoniemen, spreekwoorden, woordgrappen, of waken over het behoud van emotie, stijlkenmerken, culturele referenties enz. Het spreekt voor zich dat beëdigde vertalingen nog altijd onder eindverantwoordelijkheid van een mens moeten vallen.
Bij simultaanvertalers ligt dat nog anders. Zij werken onder hoge tijdsdruk: een vertaling moet bijna in real-time geproduceerd worden. Toekomstige context of verduidelijkingen kunnen nog ontbreken op het moment van vertalen. Tolken gebeurt, gegeven deze beperkingen, eerder op een “best effort” basis. De benodigde vaardigheden zijn dusdanig verschillend dat ook de opleidingen tot tolk of vertaler fundamenteel anders ingericht worden.
Simultaanvertaling is belangrijk: denk aan internationale vergaderingen, diplomatiek overleg, ondertiteling van live debatten op televisie, etc. Om daar een bestaande vertaalmotor voor te gebruiken, die enkel tekst naar tekst vertaalt, moet je eerst nog spraak correct kunnen omzetten naar tekst. Dat is het domein van de speech-to-text (STT) engines - maar die hebben hun eigen beperkingen, waar we vorige maand al over schreven.
Google gooide dan ook hoge ogen bij het voorstellen van de Interpreter modus van Google Translate, die ondertussen naadloos is ingewerkt in smart speakers en mobiele apps met Google Assistant. Microsoft volgde op de voet met hun Translator, die ook vergaderingen tussen meerdere personen kan begeleiden, waarbij iedereen in de eigen moedertaal toegesproken wordt. Niet van plan onder te doen, gooiden ze er gelijk plugins voor o.a. Powerpoint tegenaan, waarmee een presentatie live ondertiteld kan worden in een andere taal - gegeven dat de spreker duidelijk articuleert en standaarduitspraak hanteert. Ook moderne hardwarematige vertaalcomputers kregen al updates om spraakherkenning te integreren en gebruik te maken van cloud-based vertaalmotoren.
Een blik achter de schermen
Zo goed als alle van deze "tolk"-apps werken momenteel in dialoogvorm. Het systeem wacht totdat een zin volledig is uitgesproken voordat een vertaling begonnen wordt. Een belangrijke motivatie hiervoor is het verschil in woordvolgorde tussen talen: soms moet het einde van de zin afgewacht worden om het begin van de zin in een andere taal te kunnen vormen. Neem dit voorbeeld, vertaald met Deepl:
- Ik ben afgelopen zaterdag nog snel even naar Antwerpen gegaan
- Je me suis rendu rapidement à Anvers samedi dernier
Als men echt zo weinig mogelijk vertraging of latency wil bekomen, en nog voor de zin helemaal is uitgesproken al een aanzet van vertaling wil geven, dan moet men toelaten dat een vertaling achteraf nog aangepast kan worden. Na machine translation van een tekst is minimaal eenmalig een post-editing stap doen - eventueel ook deels automatisch - sowieso een goed idee. Wil men automatisch gaan simultaantolken dan is een trade-off te maken: hoe minder latency men toe wil laten, hoe groter het risico dat men meermaals de reeds vertaalde woorden zal moeten herwerken.
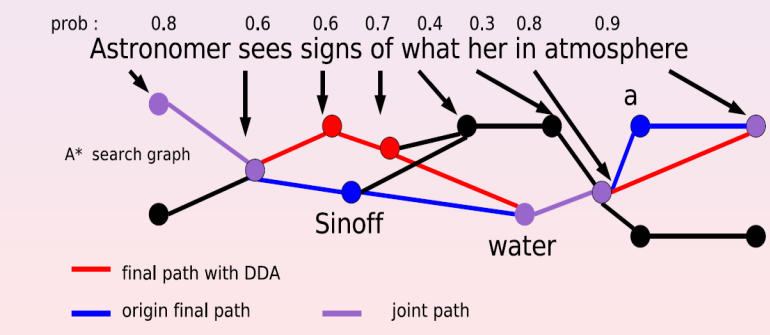
Herevaluatie in spraakherkenning: op basis van latere input worden de waarschijnlijkheden van eerdere mogelijkheden herzien. Afbeelding (c) B. Lecouteux et al. "Generalized driven decoding for speech recognition system combination", 2008
Achter de schermen doen Automatic Speech Recognition engines dat ook al bij de transcriptie van de audio: al naargelang er bijkomende fonemen worden herkend wordt telkens herberekend wat het meest waarschijnlijke woord is dat uitgesproken wordt. In het specifieke geval van ondertiteling zijn ook segmentatie en filtering (bvb "euh" en andere stopwoorden) problemen die in een editing-fase opgelost moeten geraken - zoals duidelijk te merken in deze demonstratie van BBC R&D.
Het spreekt voor zich dat het geen evidentie is om al aan een vertaling te beginnen als je nog onzeker bent over de zin in de oorsponkelijke taal. Zelfs als je die zin in de oorspronkelijke taal correct hebt kunnen transcriberen uit de audio, volgen er meestal nog enkele tussenstappen vooraleer je aan de vertaling wil beginnen: het verwijderen van stopwoordjes, getwijfel, herhalingen, etc. Die zijn erg courant in natuurlijke spraak maar wil je niet zien in een transcriptie of vertaling. Microsoft vatte het samen in het volgende diagram van een speech-to-speech vertaalsysteem:
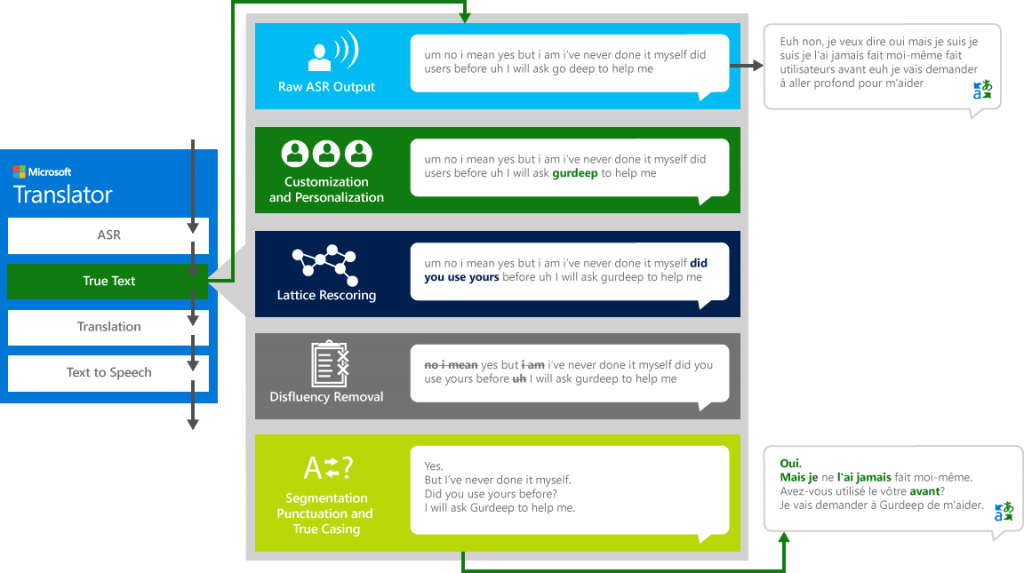
Tussen spraak begrijpen en vertalen zitten nog enkele tussenstappen om de tekst te "normaliseren". Afbeelding (c) Microsoft, bron: https://www.microsoft.com/en-us/translator/business/machine-translation/
Conclusie
Op dit moment zijn "cascade"-systemen, die stap voor stap en zin per zin de audio en tekst verwerken, de meest robuuste methodes voor speech-to-speech vertaling. Het probleem van de woordvolgorde is relatief fundamenteel. Er zal bijna altijd een vertraging van een zinslengte moeten toegestaan worden als men een robuuste automatische vertaling wilt maken die achteraf geen grote aanpassingen meer moet ondergaan. Ook in de nabije toekomst zullen tolkhulpmiddelen dus waarschijnlijk nog een tijdje turn-based blijven.
Wie zelf aan de slag wil met componenten voor spraakherkenning, postprocessing en machine translation, kan de zoektocht beginnen bij projecten zoals Mozilla Deepspeech, CMUSphinx of MarianNMT. Datasets om vertaalmotoren te trainen zijn te vinden op OpenSLR.org .
De auteur wenst Joan Van Poelvoorde, vertegenwoordiger RSZ bij de federale G-clouddienst Babelfed, en prof. dr. Bart Defrancq, hoofd van de tolkopleidingen van de UGent, te bedanken voor hun waardevolle input in de aanloop naar het schrijven van dit artikel.
______________________
Dit is een ingezonden bijdrage van Joachim Ganseman, IT consultant bij Smals Research. Dit artikel werd geschreven in eigen naam en neemt geen standpunt in namens Smals.