Hergebruik: Enkele Do's en Don'ts...
Hergebruik: het gebruiken van een bestaand stuk software voor een nieuwe toepassing.
Het lijkt een eenvoudig principe, maar er komt meer bij kijken dan je zou denken. Vooral wanneer je effectief een software artefact probeert te hergebruiken, creëer je al snel problemen. In deze blog gaan we wat dieper in op dit ogenschijnlijk simpele productiviteitsprincipe.
In mijn blog over Microservices van eind 2017 had ik het reeds kort over "re-use" als een antipatroon: dit ging vooral over hergebruik van code versus hergebruik van grotere componenten, zoals b.v. een API met een daarachterliggende microservice. Dit is een belangrijk voorbeeld van een breder principe: men moet goed weten op welk niveau van modulariteit men hergebruik wenst toe te passen.

Verderop in deze blog gaan we dieper in op drie assen volgens welke we afwegingen zullen moeten maken om te besluiten in welke mate we hergebruik zullen nastreven en toepassen: Het niveau van granulariteit, het niveau van abstractie, en het niveau van functionaliteit.
Daarnaast is het ook zo dat hergebruik maar kan op 2 voorwaarden:
- Er bestaat een dienst, module, bibliotheek, ... kortweg, een software artefact, dat herbruikbaar is.
- We gebruiken een methodologie van software ontwikkeling die ons toelaat zaken te hergebruiken. Dit wil zeggen dat we enerzijds in staat zijn om de herbruikbare component te vinden en dat we er toegang toe hebben (en dat deze voldoende is gedocumenteerd), en we anderzijds een architectuur toepassen in de doeltoepassing die toelaat het bestaande artefact ook daadwerkelijk in te zetten.
In deze blog zullen we ons focussen op principes rond het bouwen van herbruikbare artefacten, en dus niet op het tweede aspect: het beheren en gebruiken van een patrimonium van herbruikbare software componenten. Verder gaan we ook niet dieper in op zaken die gerelateerd zijn aan hergebruik, zoals bv. het gebruiken van een gedeelde infrastructuur of het vinden van allerlei synergieën op ándere vlakken.
Spanningsvelden bij het Beschouwen van Hergebruik
Zoals reeds aangehaald, zal mogelijk hergebruik van een software artefact afhangen van een aantal verschillende factoren. Telkens zal er een zeker spanningsveld heersen en zal er een middenweg moeten worden gevonden, die van project tot project of van artefact tot artefact kan verschillen.
Niveau van Granulariteit
De grootte van het software artefact dat we willen hergebruiken, heeft een grote invloed op de mogelijke impact van het hergebruik: het is uiteraard voordeliger als we ineens een volledige, kant-en-klare service kunnen hergebruiken, die duizenden lijnen code encapsuleert, dan wanneer we enkel en alleen, op het niveau van de code, een bepaalde functie van een paar regels code kunnen hergebruiken. Nochtans hebben ze elk hun eigen kracht. Alle artefacten die we gebruiken moeten worden onderhouden; doorgaans is de kost die hiermee gepaard gaat evenredig met de grootte. Daarnaast is het zo, dat men een kleiner bouwblok, indien goed gekozen, vaker zal kunnen hergebruiken dan een groter.
Het spreekt voor zich dat, hoe meer zaken men in één component verpakt, op hoe meer manieren deze component kan hergebruikt worden, maar tegelijk hoe omslachtiger het wordt om dit ook effectief te doen, omdat je teveel bagage meesleept. Beter is het om componenten zo klein mogelijk te houden, zodat ze één functionaliteit aanbieden, en deze kleine componenten dan op zoveel mogelijk plaatsen te gaan inzetten. Hier is echter weeral een spanningsveld: hoe meer componenten er bestaan, des te moeilijker wordt het om te weten dat ze bestaan (en om ze terug te vinden, dus). Kleine componenten bieden daarnaast echter nog vele andere voordelen (bv. microservices en agility, zoals beschreven in de blog daaromtrent).
Maar ook de context van het hergebruik speelt een rol bij overwegingen betreffende de grootte van de component: de functie van een paar regels code: zullen we deze enkel hergebruiken binnen eenzelfde project? Of als deel van een bibliotheek of raamwerk dat nog door vele andere projecten kan worden gebruikt? Hier zat de essentie van het verhaal bij microservices: men moet goed waken over de onfhankelijkheid van deze wonderen van de moderne architectuur: wanneer twee microservices gebruik maken van eenzelfde stuk code, heeft men in principe een afhankelijkheid gecreëerd tussen de beide.
Mate van Abstractie
De mate van abstractie van software kan sterk variëren. Men kan een stuk software bouwen, nauwelijks parametriseerbaar, specifiek voor één welbepaalde taak. Dit zal nauwelijks herbruikbaar zijn. Maar indien men te ver probeert te gaan in de mate van abstractie die een stuk software aanbiedt, krijgt men uiteindelijk iets dat onbruikbaar is voor het oorspronkelijk doeleinde, omdat het zo generisch is, dat er nog heel veel werk bij komt kijken om het als dusdanig te parametriseren aan het doel waarvoor het werd ontworpen. Bovendien is software met een hoge mate van abstractie vaak ook moeilijker te begrijpen voor ontwikkelaars. Hier komt het er dus op neer een gouden middenweg te vinden: voldoende abstractie, zodat er binnen het business domein, en zoniet op een technisch vlak, nog enige kans bestaat op later hergebruik, maar niet teveel, zodat het artefact nog voldoende snel en eenvoudig inzetbaar is voor het oorspronkelijke doel. Daar komt dan wel nog een tweede spanningsveld roet in het eten gooien: dat van kost versus mate van abstractie. Een stuk software op een meer generische manier ontwerpen, vraagt doorgaans meer resources en een langere ontwikkeltijd dan om iets te bouwen voor één welbepaald doel. Men kan dus niet tegelijkertijd van een team van ontwikkelaars verwachten om zoveel mogelijk kostenbesparend te werken en enorm veel functionaliteit op te leveren tegen strakke deadlines, en tegelijkertijd geweldig herbruikbare (en onderhoudbare, robuuste, stabiele, ... ) producten af te leveren.
Hoogte in de functionele stack
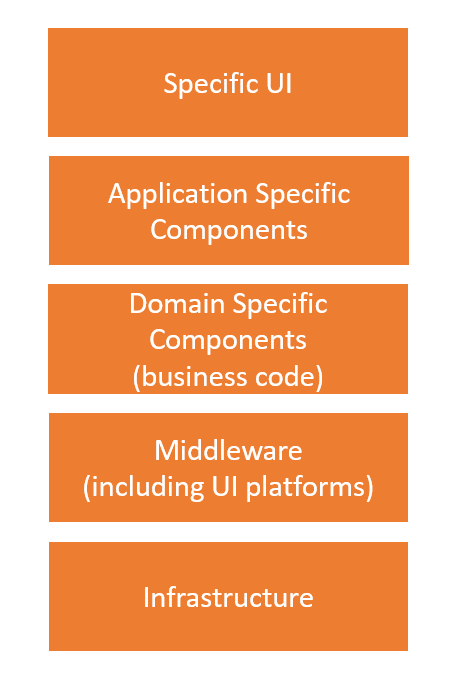
In grote lijnen de "Functionele Stack": hoger liggende componenten maken hier typisch enkel gebruik van lager liggende zaken. Hoe lager iets ligt, des te vaken het kandidaat is voor hergebruik.
Een afgewerkte software, gebouwd voor een specifiek doel, met een eigen UI, is ongeveer wat als het hoogste in de "functionele stack" beschouwd kan worden. Dit is nauwelijks herbruikbaar, want purpose-built (met een grote uitzondering voor SaaS-software). Lager in deze stack vindt men business-domein-specifieke bibliotheken en APIs. Deze zijn, binnen een bepaalde context, al een stuk herbruikbaarder (maar niet onmiddellijk functioneel inzetbaar zonder er iets vóór of rond te bouwen). Nog lager in de stack vindt men zaken die over domeinen heen herbruikbaar zijn: database software, cloud platformen, algemene software libraries en raamwerken. De laagste elementen in de stack, daar denken we zelfs al niet meer bij na wanneer we ze hergebruiken: het gaat om constructies die in bijna alle programmeertalen voorkomen (gegevensstructuren zoals arrays, ondersteuning voor reguliere expressies, etc.).
Bedrijven die een sprong maken naar een Cloud Platform, maken typisch ook een sprong in herbruikbaarheid wat betreft het niveau in de functionele stack. Het gebruik van zaken als virtualisatie zorgt er bv. voor dat het veel sneller gaat om infrastructuur te koppelen aan een applicatie en dat deze koppeling ook bruikbaar is voor gelijkaardige applicaties (door de configuratie van zo'n machine te hergebruiken). Hogerop in de stack laat een platform als Kubernetes en het gebruik van containers toe dat men software images van over de hele wereld, en bovendien ook de eigen images, kan hergebruiken.
Wat kan ons Helpen?
Kunnen we nu doorheen de anaylse van deze verschillende dimensies van hergebruik een rode draad trekken? Op welke manier zullen we het vaakst "de gulden middenweg" kunnen exploiteren? Hier speelt de gebruikte methodologie van software ontwikkeling een rol, en zeker ook de architectuur van zowel het mogelijks herbruikbare artefact en van de doeltoepassing. Moderne architecturale principes hebben hier vrijwel altijd een streepje voor, en de software industrie blijft hierin innoveren. Modulariteit is één van de sterkste drijvende krachten (ik verwijs opnieuw naar microservices, en nu misschien ook al naar FPaaS).
Over MicroServices en APIs
Ik heb nu reeds tweemaal modulariteit en microservices aangehaald, maar daar moet wel een serieuze kanttekening bij worden gemaakt.
Microservices zijn OP ZICH NIET herbruikbaar. Het zijn de APIs die men rond diensten bouwt, die herbruikbaar zijn door andere zaken.
Van cruciaal belang is dus het ontwerp van deze APIs, rigoureus volgens standaarden (REST) die nog eens zijn versterkt door een weldoordachte huisstijl (of beter nog, "sector-stijl"). Daarnaast moet men bij het ontwerpen van deze APIs goed rekening houden met de hierboven beschreven mate van abstractie en hoogte in de functionele stack. Bovendien moeten de APIs ook bekend zijn, en toegankelijk zijn. Het laatste vergt goed API management en sterke documentatie (en "kruisbestuifmensen" die kunnen fungeren als katalysatoren, overheen projecten), en ook een vlot proces van het ter beschikking stellen van APIs. Bij dit laatste spelen zaken zoals GDPR uiteraard een rol, maar spijtig genoeg ook af en toe politieke redenen (men wil soms te hard zijn "eigenaarschap" over bepaalde diensten of data behouden, en men belemmert om deze reden het hergebruik; of nog vindt men van zijn eigen systemen dat deze "te uniek" zouden zijn om in een hergebruik-kader te functioneren). Ten slotte is het ook van belang dat de systemen die schuilgaan achter de APIs, voldoende schaalbaar zijn, zodat ze bij toenemend gebruik nog kunnen volgen.
APIs: de herbruikbare interface waar zoveel zaken achter kunnen liggen. Hergebruik van werkende systemen dient zoveel mogelijk via RESTful APIs te gebeuren.
Wanneer we over APIs spreken, spreken we hier dus over het hergebruik van (werkende) diensten. Dit is de belangrijkste vorm wat betreft zelfgemaakte software artefacten. Het hergebruik van (eigen) code is iets totaal anders. Dit kan zelfs contraproductief zijn: één van de krachtigste eigenschappen van microservices binnen een moderne architectuur, is hun onderlinge onafhankelijkheid: een microservice moet volledig op eigen benen kunnen staan (eigen werking, eigen logica, eigen data(-base), eigen (deeltje van de) infrastructuur, … De enige connectie met de buitenwereld is via Events (zie verder) en een API ! ). Daarnaast maakt men ze zo klein mogelijk. Dit maakt ze enorm flexibel ("agile"): men kan ze apart van andere zaken onderhouden, aanpassen, vervangen (vandaar ook dat ze klein moeten zijn, "rip-and-replace" mag niet teveel kosten). Deze flexibiliteit maakt het mogelijk voor een softwarebedrijf om enorm snel op veranderende behoeften van de business in te spelen, doordat het geheel aan microservices continu en heel snel kan evolueren zonder volledig offline te gaan of langdurige aanpassingsprojecten en redeployments te moeten ondergaan. Welnu, vermits microserives zo onafhankelijk mogelijk van elkaar moeten zijn, kan het soms contraproductief zijn om zaken (niet alleen code maar bv. ook een bepaalde database) te gaan hergebruiken tussen meerdere microservices. Dergelijk hergebruik creëert afhankelijkheden en verplichtingen die de wendbaarheid van een microservice doen afnemen! Enkel zeer algemeen inzetbare bibliotheken (typisch 3rd party, vaak open source) vormen goede kandidaten om binnen een microservice herbruikt te worden; deze zitten typisch iets lager op de functionale stack dan het (business) domein waar de microservice rond is opgebouwd.
Event Driven Architecture
In deze context komen we best ook terug op Event Driven Architecture. Events zijn één van de datastructuren die men het dichtst bij de werkelijkheid kan doen aanleunen. Het gaat om een opdracht of aangifte of aanvraag die binnenkomt, een gebeurtenis uit de echte wereld die men modeleert, een bepaald gegeven dat beschikbaar wordt, een verandering van een reeds gekend gegeven, …
Deze zaken kunnen allemaal veel letterlijker gemapt worden op de werkelijkheid, dan wanneer ze eerst reeds binnen een bepaalde context (meestal de toepassing via dewelke ze het eerst worden ingevoerd) worden verwerkt. Hoe dichter deze informatie aanleunt bij de werkelijke wereld, hoe herbruikbaarder ze is voor andere zaken. Hetzij andere toepassingen die reeds bestaan en anders moeten wachten tot de data (soms in batch) wordt doorgestuurd of kan worden opgehaald via API, hetzij toepassingen die men pas zal bedenken doordat de events al bestaan (het zogenaamde kruisbestuiven binnen een applicatie ecosysteem).
Zaak is dus van events heel goed te ontwerpen, vooral op het niveau van business events, en van deze meer en meer te gaan (her-)gebruiken. Naast mogelijk hergebruik heeft dit ook een mooie standaardisatie tot gevolg in de manier waarop applicaties (asynchroon) communiceren en data geprolifereerd wordt binnen een netwerk van toepassingen, en bovendien krijgt men de data op die manier veel sneller op alle plaatsen waar men ze nodig heeft, waardoor men op business niveau veel sneller kan reageren en flexibeler kan zijn. Goede documentatie van de events die men reeds heeft gedefiniëerd is dan uiteraard heel belangrijk. Ten slotte heeft men via events automatisch de volledige geschiedenis van de gegevens en niet alleen van de huidige toestand. Deze geschiedenis kan eveneens hergebruikt worden bij o.a. het aanpassen en testen van toepassingen, het ontwikkelen van nieuwe zaken, en verregaande analyse (evt. ook voor het trainen van een AI)
Besluit
Wanneer men praat over herbruikbaarheid, is het belangrijk te verduidelijken of men het nu over code, dan wel APIs, diensten, componenten, infrastructuur of volledige software-pakketten gaat hebben. Samenvattend komt dit neer op het definiëren van de modulariteit, de mate van abstractie en de hoogte in de functionele stack van hetgeen men zou willen hergebruiken. Daarenboven moet men de afweging maken tussen de herbruikbaarheid van een artefact en de kostprijs om het te bouwen en onderhouden.
Indien men met al deze aspecten rekening houdt, kan men besluiten dat hergebruik niet altijd alleszaligmakend is en dat het soms zelfs contraproductief kan zijn. Het belangrijkste hergebruik zal zich vaak ook niet op het niveau van de code bevinden.
Wat applicatie architectuur in het algemeen betreft, maar dan nu specifiek toegepast op herbruikbaarheid, kunnen we daarnaast besluiten dat APIs (ondersteund door microservices, uitgerold op containers) en Event Driven Architecture een grote meerwaarde kunnen bieden.
Verdere resources:
- Een boek over het hergebruik van software: https://vijaynarayanan.gitbooks.io/art-of-software-reuse/content/
- Over de val van genericiteit en 'super'-libraries, en de voordelen van modulariteit: http://josdejong.com/blog/2015/01/06/code-reuse/
- Over de valstrikken van "code reuse" en hoe management dit echter meestal ziet: https://blog.ndepend.com/code-reuse-not-good-goal/
- Over de kost van hergebruik: https://dzone.com/articles/economics-reuse
- Bedenkingen bij extreme programming, een methodologie dewelke "design for reuse" eigenlijk afraadt: https://www.infoq.com/news/2009/04/agile-code-reuse
- Talk van Rob Pike, met de quote "A little copying is better than a little dependency" (code reuse zorgt voor dependencies!): https://www.youtube.com/watch?v=PAAkCSZUG1c&t=9m28s
- Martin Fowler over, o.a. , reuse: https://martinfowler.com/bliki/Seedwork.html
- Methodologische tips voor hergebruik: https://www.infoq.com/articles/vijay-narayanan-software-reuse
- Hoe reuse aanpakken op bedrijfsniveau: http://www.cs.cmu.edu/afs/cs/usr/ppinto/www/reuse.html
_________________________
Dit is een ingezonden bijdrage van Koen Vanderkimpen, IT consultant bij Smals Research. Dit artikel werd geschreven in eigen naam en neemt geen standpunt in namens Smals.