Graphtechnologieën, de toepassingen ervan en tools: een overzicht (deel 1)
Dankzij hun vermogen om complexe relaties tussen gegevens te begrijpen en te benutten, worden graphtechnologieën steeds populairder op veel gebieden van kunstmatige intelligentie en gegevensbeheer. Deze blog heeft al meerdere artikels gepubliceerd over verschillende graphtechnologieën, waaronder graph databases [1, 2, 3] en knowledge graphs [4, 5, 6].
Maar wat betekent de term ‘graph’ eigenlijk? Tussen de wiskundige modellen die als basis dienen, graph databases en knowledge graphs, kan het moeilijk zijn om je weg te vinden en de tools te identificeren die het best passen bij je behoeften. Hierbij komt nog het feit dat werken met graph data op het eerste gezicht complex kan lijken en dat het gebruik van graphalgoritmes niet tot de kernvaardigheden van de meeste data engineers en data scientists behoort. Dit alles kan het creëren en exploiteren van graph data en modellen tot een ontmoedigend vooruitzicht maken.
Dit artikel geeft daarom een overzicht van graphtechnologieën, waarbij de drie bovengenoemde aspecten worden verkend:
- Graphs vanuit een theoretisch oogpunt, hun eigenschappen en hun belangrijkste toepassingen;
- Graph databases, gespecialiseerd in de opslag en exploitatie van gekoppelde gegevens;
- Knowledge graphs, die kennis semantisch structureren.
Daarom is het de bedoeling om deze concepten en de – soms vage – grenzen ertussen te presenteren, en hun toepassingen en de bijbehorende tools en software te belichten.
Dit artikel is opgesplitst in twee delen. Het eerste deel richt zich op graphs in hun fundamentele wiskundige vorm, hoe ze kunnen worden gecodeerd en geëxploiteerd, en de belangrijkste algoritmes en de toepassingen ervan. Het tweede deel richt zich op graph databases en knowledge graphs, en de bijbehorende tools.
Back to basics: graphs als wiskundige structuur
Laten we eerst definiëren wat een graph is. Deze theoretische basis is cruciaal aangezien de concepten van graph databases en knowledge graphs op deze basis zijn gebouwd. Deze meer geavanceerde concepten kunnen op elk moment worden teruggebracht tot hun onderliggende wiskundige vorm en bij uitbreiding zijn alle modellen en algoritmes die hieronder worden gepresenteerd toepasbaar op graph databases en knowledge graphs.
In zijn meest basale vorm is een graph een wiskundige structuur die bestaat uit een verzameling nodes en arcs die de nodes paarsgewijs verbinden. Nodes stellen meestal objecten of mensen voor en bogen stellen links tussen deze objecten of mensen voor. In het geval van een sociaal netwerk kan een boog bijvoorbeeld een vriendschapsband tussen twee gebruikers voorstellen.
De graph kan zowel gericht als ongericht zijn. In het geval van een ongerichte graph zijn de relaties tussen nodes altijd wederkerig (bijvoorbeeld een vriendschapslink op Facebook), terwijl in een gerichte graph een boog die van node i naar node j gaat, niet noodzakelijk een boog in de tegenovergestelde richting impliceert (bijvoorbeeld een website A die een link heeft naar een website B).
Afhankelijk van de situatie of toepassing kan een graph al dan niet gewogen zijn. Een graph is als gewogen omschreven als er aan elke boog een gewicht wordt toegekend dat varieert van boog tot boog en dat het mogelijk maakt om bepaalde bogen een grotere “kracht” te geven. De interpretatie van deze gewichten hangt af van de context; ze kunnen bijvoorbeeld een mate van verwantschap, gelijkenis, afhankelijkheid, enz. weergeven.
Een graph wordt over het algemeen voorgesteld door een vierkante matrix van dimensie (n × n), waarbij n het aantal nodes in de graph voorstelt, genaamd een adjacency matrix (aangeduid als A). Het element op positie (i, j) in de matrix is het gewicht van de boog van node i naar node j als deze bestaat, en anders 0 (zie figuur 1). De adjacency matrix is gewoon een binaire matrix als de graph ongewogen is.
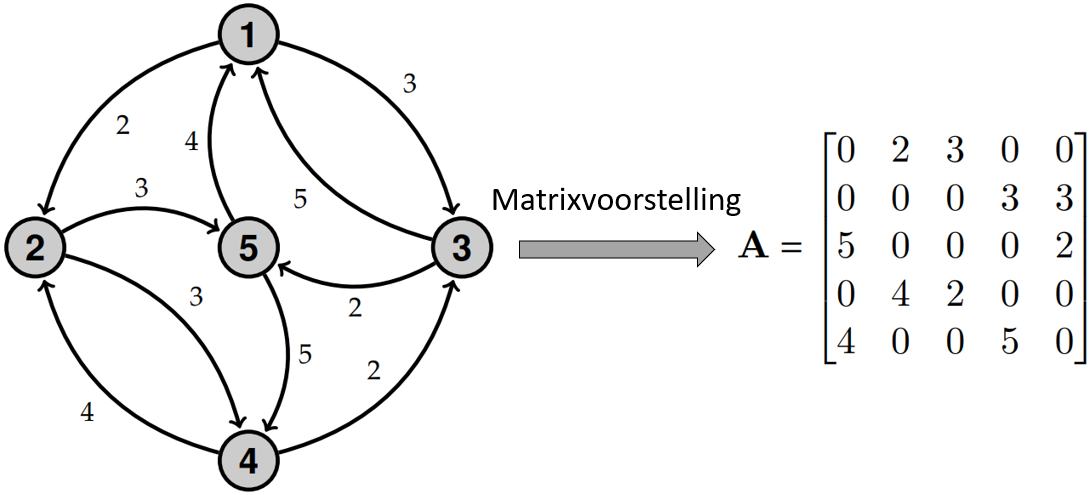
Hier gaat een boog van gewicht 3 van node 1 naar node 3 en een boog van gewicht 5 in de tegenovergestelde richting. De matrix A bevat daarom de waarde 3 op positie (1,3) en de waarde 5 op positie (3,1).
Merk op dat adjacency matrices vaak grotendeels nullen bevatten en daarom over het algemeen worden gecodeerd met behulp van sparse matrices om het geheugen te optimaliseren.
Deze voorstelling van een graph in matrixvorm maakt het veel eenvoudiger om algoritmes op de graph te gebruiken, aangezien veel graphalgoritmes, die soms complex zijn in de vorm van vergelijkingen, vaak gereduceerd kunnen worden tot een reeks elementaire matrixbewerkingen. Dit maakt hun uitvoering zeer efficiënt in wetenschappelijke programmeertalen die geoptimaliseerd zijn voor matrixberekeningen, zoals R, MATLAB, Julia of Python (numpy, scipy).
Gebruiken van graphalgoritmes en praktische toepassingen
Om het nut van een graph beter te begrijpen, kijken we eerst naar de hoofdcategorieën van graphalgoritmes, met voor elke categorie een paar voorbeelden van het praktische gebruik ervan.
- Het optimale pad bepalen om een paar nodes te verbinden.
Hierbij kan het gaan om het minimaliseren van het aantal overgangen dat nodig is om van de ene node naar de andere te gaan of, als er kosten zijn verbonden aan elke boog, het vinden van het pad met de laagste kosten. De kosten kunnen gedefinieerd worden als het gewicht van een boog, of gecodeerd worden in een tweede matrix (kostenmatrix, onafhankelijk van de adjacency matrix). De manier waarop de kosten van een boog worden bepaald hangt af van de toepassing, afhankelijk van wat je wilt minimaliseren. Dit kan bijvoorbeeld een maat voor de lengte van de boog zijn (de lengte van een weg), een maat voor de tijd (de tijd die nodig is om de boog over te steken) of financiële kosten. Dit type algoritme kan worden gebruikt in de logistiek om transport te optimaliseren. De bekendste algoritmes zijn de algoritmes Dijkstra, A* en Bellman-Ford.
- Maatstaven bepalen voor gelijkenis of afstand tussen nodes in een graph.
Afhankelijk van de context kan het nuttig zijn om een similariteitsmaat te bepalen tussen twee nodes in een graph om te bepalen hoe dicht ze bij elkaar liggen. Similariteitsmaten worden vaak gebruikt in aanbevelingstoepassingen. Door een consumptiegraph te ontwerpen die gebruikers koppelt aan de producten die ze hebben geconsumeerd, maakt het meten van de similariteit tussen nodes het voor een bepaalde gebruiker mogelijk om gebruikers met een gelijkaardig consumptieprofiel te identificeren, gebaseerd op hun connecties met de producten. Een product wordt meestal aanbevolen aan een gebruiker omdat het door veel vergelijkbare gebruikers is geconsumeerd (user-based recommendation) of omdat het product vergelijkbaar is met producten die de gebruiker al heeft geconsumeerd (item-based recommendation). De bekendste similariteitsmaten zijn over het algemeen gebaseerd op common-neighbour maten (het aantal buren dat twee nodes gemeen hebben), zoals de Jaccard-index of cosinus-similariteit, maar andere methoden houden ook rekening met indirecte buren, zoals de Katz-kernel [12] (ook bekend als de “von Neumann kernel”). Zie [13] voor enkele klassieke similariteitsmaten en het gebruik ervan in aanbevelingen.
Het tegenovergestelde van een similariteitsmaat is een dissimilariteitsmaat, die toeneemt naarmate twee nodes verder van elkaar verwijderd zijn. Een afstandsmaat is per definitie een dissimilariteit, omdat deze toeneemt naarmate twee nodes verder van elkaar verwijderd zijn. De bekendste en meest intuïtieve maat voor dissimilariteit tussen twee nodes is de lengte van het kortste pad tussen hen.
- De centraliteit meten.
Een maat voor de centraliteit van een node of boog, soms ook een prestige measure genoemd, wordt gebruikt om te kwantificeren hoe belangrijk een node of boog is binnen een graph. De bekendste maat voor centraliteit is de score die wordt berekend door het algoritme PageRank [14]. PageRank werd oorspronkelijk ontwikkeld en gebruikt door de zoekmachine Google om webpagina’s te rangschikken. Het is gebaseerd op een willekeurige beweging in een graph waarin elke node een webpagina voorstelt en elke gerichte boog een hyperlink tussen twee pagina’s voorstelt. Het PageRank-algoritme kent naast het rangschikken van webpagina’s heel wat andere toepassingen:
“Google’s PageRank method was developed to evaluate the importance of web-pages via their link structure. The mathematics of PageRank, however, are entirely general and apply to any graph or network in any domain. Thus, PageRank is now regularly used in bibliometrics, social and information network analysis, and for link prediction and recommendation. It’s even used for systems analysis of road networks, as well as biology, chemistry, neuroscience, and physics.” – Gleich (2014) [15]
Een ander bekend algoritme dat lijkt op PageRank is het HITS-algoritme (Hyperlink-Induced Topic Search) [16].
Als we het over centraliteit hebben, is PageRank vaak het algoritme dat wordt voorgesteld, maar centraliteit kan op verschillende manieren worden begrepen. Het kan bijvoorbeeld verwijzen naar een node of boog die een kritieke intermediair is voor communicatie en informatieoverdracht binnen het netwerk. Centrale nodes identificeren kan het bijvoorbeeld mogelijk maken om informatie optimaal te verspreiden in een netwerk of om nodes of bogen op te sporen die van vitaal belang zijn voor de graph (waarvan de verdwijning de informatieoverdracht in de graph ernstig zou belemmeren). Veel voorkomende maatstaven voor node- of boog-centraliteit op basis van dit principe gebruiken over het algemeen tussen-maatstaven (betweenness centrality).
Centraliteit kan ook worden beschouwd als een maat voor de representativiteit van een node binnen een gemeenschap (in termen van nabijheid tot de andere nodes in de graph), in dit geval gemeten door middel van een maat van nabijheid (closeness centrality). Merk op dat we het gebruik van verschillende centraliteitsalgoritmes in een fraudedetectiecontext al hebben vermeld in eerdere blogposts, met name PageRank (in de vorm van een verspreidingsalgoritme) [7] en betweenness centrality [8].
- De graph partitioneren.
Beter bekend als “clustering”, bestaat graph partitioning uit het groeperen van nodes in communities (clusters) zodat nodes binnen een community “similair” zijn en twee nodes die tot verschillende communities behoren “dissimilair” zijn. Dit partitioneren kan op verschillende manieren gebeuren. Door bijvoorbeeld een maat voor similariteit of dissimilariteit tussen de nodes in de graph te gebruiken en vervolgens een clusteralgoritme zoals k-medoids uit te voeren op basis van deze (dis)similariteiten.
Een andere manier is om direct op de graph te werken en te proberen dichte gebieden binnen de graph te detecteren. Dit kan worden gedaan met behulp van labelpropagatie [17], of door het optimaliseren van een objectieve functie die de kwaliteit van de partitionering meet, zoals modulariteit. Het bekendste algoritme voor modulariteitsoptimalisatie is de Louvain-methode [18].
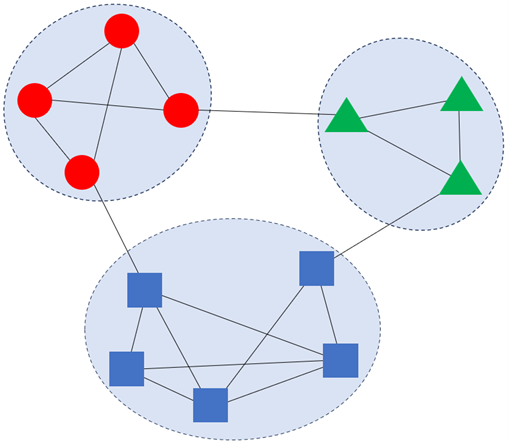
We hebben het gebruik van ‘graph partitioning’-methodes al genoemd in verschillende blogposts [9, 10]. Deze algoritmes worden met name gebruikt in communicatie en marketing om gerichte advertenties te produceren.
- Kenmerken of representaties extraheren.
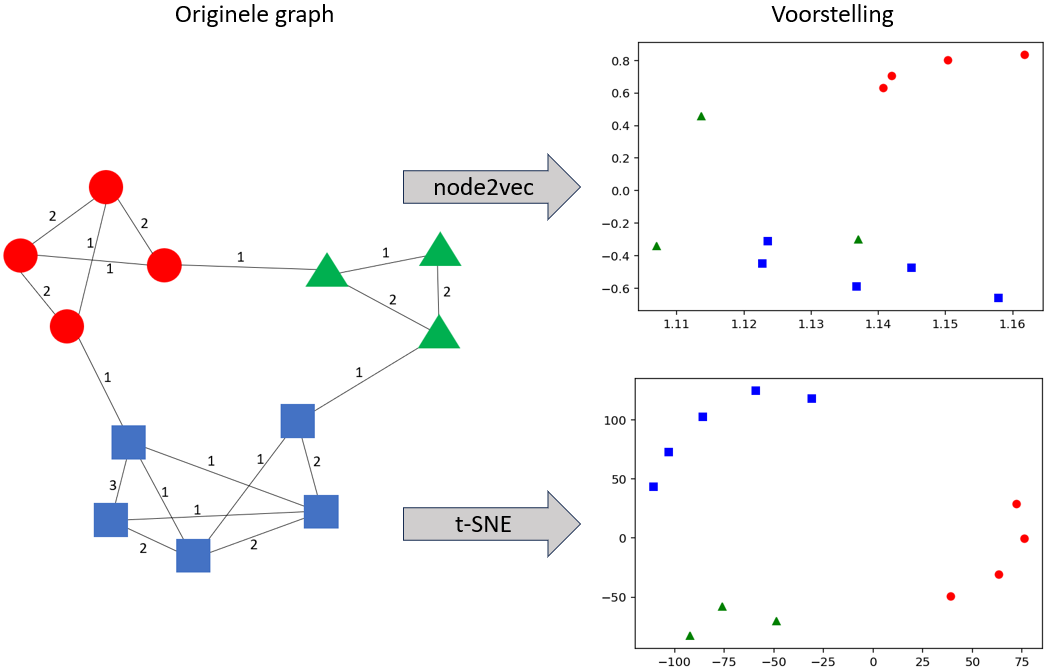
De traditionele modellen voor machine learning hebben als limiet dat ze alleen rekening houden met de gegevens (continue en categorische variabelen) die betrekking hebben op de waarnemingen, en de informatie negeren die kan worden afgeleid uit de relaties tussen de waarnemingen. Indien er relaties bestaan tussen deze gegevens, kan er een graph worden geconstrueerd en kunnen de machine learning modellen worden verrijkt door nieuwe variabelen uit de graph toe te voegen (er is ook een blogpost over dit onderwerp [11]). Deze nieuwe variabelen kunnen bijvoorbeeld een maat voor centraliteit zijn (continue variabele) of het resultaat van partitionering (categorische variabele), of ze kunnen worden verkregen met behulp van ‘graph embedding’-methoden (continue variabelen). Graph embedding moet leiden tot een representatie van de nodes in een multidimensionale ruimte. Deze ruimte wordt zo berekend dat als twee nodes dicht bij elkaar liggen in de graph, ze ook dicht bij elkaar liggen in deze ruimte. Zo’n ruimte kan worden verkregen met methoden die direct op de graph werken (node2vec [19], fastRP [20]) of door te werken op basis van bijvoorbeeld similariteiten (kernelPCA [21]) of afstanden (t-SNE [22]). Zie figuur 3 voor een voorbeeld van een tweedimensionale weergave van een eenvoudige gewogen graph.
- Links voorspellen.
Het concept van linkvoorspelling is relatief eenvoudig: het gaat om het inschatten van de waarschijnlijkheid dat er een link bestaat tussen twee nodes. Dit maakt het mogelijk om potentieel ontbrekende bogen (incomplete graph) te detecteren, of om het verschijnen van nieuwe bogen te voorspellen. Aanbevelingsalgoritmes zijn een veelvoorkomend voorbeeld van het voorspellen van links tussen gebruikers en producten, maar deze algoritmes kunnen ook worden gebruikt om potentiële, nog onbekende interacties binnen biologische netwerken te detecteren. Dit type voorspelling wordt vaak verricht met behulp van methoden gebaseerd op overeenkomsten tussen nodes, matrixfactorisatie, probabilistische modellen of kunstmatige neurale netwerken [23].
Welke hulpmiddelen?
Zoals hierboven vermeld betekent de weergave van graphs in matrixvorm dat ze efficiënt gebruikt kunnen worden in wetenschappelijke programmeertalen. Er bestaan echter ook library’s of softwares die gebruikt kunnen worden om graphs te creëren en te exploiteren.
Enkele voorbeelden van library’s voor het werken met graphs. Deze library’s kunnen worden gebruikt om een graph object te maken dat op verschillende manieren kan worden opgebouwd. Het kan leeg worden opgebouwd, voordat handmatig nodes en bogen worden toegevoegd, of vanuit een adjacency matrix of een lijst van bogen, of rechtstreeks vanuit bestanden die een beschrijving van de graph bevatten in de vorm van een lijst van nodes en bogen. Voorbeelden van graph-georiënteerde library’s zijn igraph, NetworkX, graph-tool of NetworKit voor Python, igraph voor R en Graphs voor Julia.
Voor gebruikers die al een van deze talen kennen, hebben deze library’s het voordeel dat ze intuïtief en gemakkelijk te leren zijn en veel voorgeïmplementeerde graph algoritmes bevatten.
Conclusie
In het eerste deel van deze blogpost hebben we ons toegespitst op de verschillende graph tools, we hebben de graphtheorie kort ingeleid, alsook de voornaamste toepassingen en algoritmes voor graphs. Het tweede deel richt zich op graph databases en knowledge graphs, het verschil tussen deze concepten en de bijbehorende tools.
Referenties
Enkele blogposts van Smals Research over graphs:
[2] Sept (bonnes) raisons d’utiliser une Graph Database
[3] Een graph database verkennen
[4] Les graphes de connaissance, incontournable pour l’intelligence artificielle
[5] Les graphes de connaissance : quelques applications
[6] Smals KG Checklist: déterminer si un graphe de connaissances peut résoudre un problème concret
[7] Un fraudeur ne fraude jamais seul
[8] Un fraudeur ne fraude jamais seul, partie 2
[9] Ce qu’un réseau social peut nous apprendre
[10] Facebook : peut-on vraiment cacher sa liste d’amis ?
[11] Améliorer le Machine Learning avec des données graphes
Wetenschappelijke bronnen:
[12] Katz, L. (1953). A new status index derived from sociometric analysis. Psychometrika, 18(1), 39-43.
[13] Fouss, F., Pirotte, A., Renders, J. M., & Saerens, M. (2007). Random-walk computation of similarities between nodes of a graph with application to collaborative recommendation. IEEE Transactions on knowledge and data engineering, 19(3), 355-369.
[14] Page, L., Brin, S., Motwani, R., & Winograd, T. (1998). The pagerank citation ranking: Bringing order to the web. Technical report, Stanford Digital Libraries.
[15] Gleich, D. F. (2015). PageRank beyond the web. siam REVIEW, 57(3), 321-363.
[16] Kleinberg, J. M. (1999). Authoritative sources in a hyperlinked environment. Journal of the ACM (JACM), 46(5), 604-632.
[17] Raghavan, U. N., Albert, R., & Kumara, S. (2007). Near linear time algorithm to detect community structures in large-scale networks. Physical Review E—Statistical, Nonlinear, and Soft Matter Physics, 76(3), 036106.
[18] Blondel, V. D., Guillaume, J. L., Lambiotte, R., & Lefebvre, E. (2008). Fast unfolding of communities in large networks. Journal of statistical mechanics: theory and experiment, 2008(10), P10008.
[19] Grover, A., & Leskovec, J. (2016). node2vec: Scalable feature learning for networks. In Proceedings of the 22nd ACM SIGKDD international conference on Knowledge discovery and data mining (pp. 855-864).
[20] Chen, H., Sultan, S. F., Tian, Y., Chen, M., & Skiena, S. (2019, November). Fast and accurate network embeddings via very sparse random projection. In Proceedings of the 28th ACM international conference on information and knowledge management (pp. 399-408).
[21] Schölkopf, B., & Smola, A. J. (2002). Learning with kernels: support vector machines, regularization, optimization, and beyond.
[22] Van der Maaten, L., & Hinton, G. (2008). Visualizing data using t-SNE. Journal of machine learning research, 9(11).
[23] Lü, L., & Zhou, T. (2011). Link prediction in complex networks: A survey. Physica A: statistical mechanics and its applications, 390(6), 1150-1170.
Dit is een ingezonden bijdrage van Pierre Leleux, data scientist et network data analyst bij Smals Research. Dit artikel werd geschreven in eigen naam en neemt geen standpunt in namens Smals.