Graphtechnologieën, de toepassingen ervan en tools: een overzicht (deel 2)
Deze blogpost volgt op deel 1, die de grondbeginselen van graphtechnologieën, hun algoritmes en toepassingen toelicht. Dit tweede deel is gewijd aan graph databases en aan knowledge graphs, hun verschillen en tools.
Graph databases
Zoals bij een relationele database is ook bij een graph database het doel om gegevens op een persistente manier op te slaan en te beheren en om complexe query’s uit te voeren. Het verschil is dat de gegevens worden opgeslagen in de vorm van een graph, d.w.z. een verzameling nodes die onderling verbonden zijn door bogen.
Graph databases hebben een aantal voordelen ten opzichte van traditionele relationele databases, omdat het graph model eenvoudige, geoptimaliseerde doorloop van gegevens via bogen mogelijk maakt, terwijl het verkennen van relaties in een relationele database een groot aantal joints kan vereisen. Meer details over de voordelen van graph databases en de situaties waarin ze gebruikt kunnen worden, zijn te vinden in de blogposts [1] en [2].
De drie componenten van een graph database zijn nodes, bogen en properties. Deze eigenschappen kunnen ofwel op de nodes, ofwel op de bogen, ofwel op beide worden geplaatst. Laten we eens kijken naar het voorbeeld in Figuur 1, de node “Paul” kan bijvoorbeeld gelinkt worden met eigenschappen zoals zijn geboortedatum en adres, voor de nodes die films voorstellen kunnen we eigenschappen associëren zoals het jaar van uitgave, het budget en de IMDb identifier, en op de “RATED” relaties tussen een gebruiker en een film kunnen we eigenschappen associëren zoals de kijkdatum en de waardering (op 5) die de gebruiker aan de film geeft.
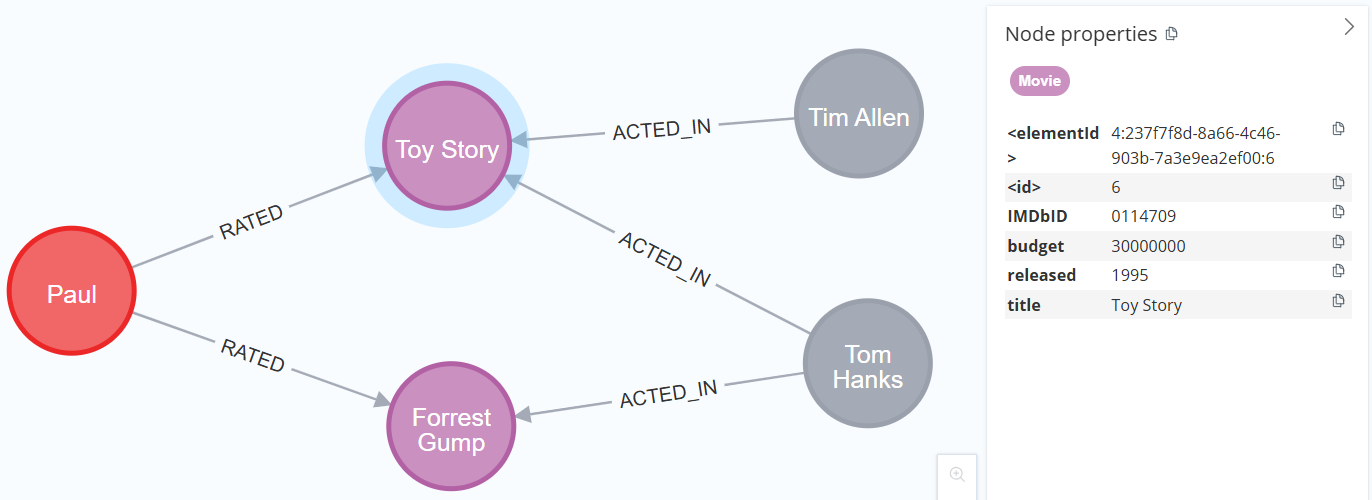
Merk op dat de graph algoritmes die we in deel 1 hebben gepresenteerd vaak niet zijn geïmplementeerd in graph database software, met een paar uitzonderingen (Neo4j en TigerGraph hebben een “Graph Data Science (GDS)” library die verschillende algoritmes bevat). Over het algemeen is het daarom nodig om de graph (of een deel ervan) te exporteren naar een analysetool.
Tools voor graph databases
Laten we eens snel kijken naar enkele van de bekendste tools. Merk op dat alle hieronder genoemde tools compatibel zijn met ACID-eigenschappen. Er bestaan een groot aantal tools voor het beheren van graph databases, en deze post noemt er maar een paar. Bekijk hier gerust een uitgebreidere lijst.
- Neo4j
Neo4j biedt het voordeel van een native graphformaat, wat het doorlopen van de graph zeer efficiënt maakt (en dus ook de query’s) De query’s gebeuren via Cypher, een taal die gemakkelijk te leren is, Neo4J is bovendien goed gedocumenteerd en beschikt over een grote community. Neo4J is in zijn “community”-versie gratis, maar een betalende versie bestaat ook (Neo4J Enterprise), de gratis versie kan een aantal schaalbaarheidsproblemen opleveren bij zeer grote hoeveelheden data.
- ArangoDB
ArangoDB biedt een flexibel datamodel (multimodel), met een graphmodel, een documentmodel (gebaseerd op JSON-objecten) en een key-value model. Het heeft zijn eigen querytaal, AQL (Arango Query Language), die ingewikkelder kan zijn om te leren dan Cypher vanwege het multimodel dat aan de grondslag ligt van ArangoDB. Het programma is betalend, hoewel er ook een opensourceversie bestaat (community edition), maar die is (uiteraard) beperkter dan de betalende versie.
- TigerGraph
TigerGraph is een betalende tool, die geoptimaliseerd is voor gebruik op zeer grote databases. De query’s gebeuren via de taal GSQL, die het mogelijk maakt om verschillende taken uit te voeren, maar die ingewikkelder is dan Cypher. TigerGraph beschikt over verschillende algoritmes die geïmplementeerd zijn via de GDS library.
- Memgraph
Memgraph is een speciale tool in die zin dat hij gegevens direct in het geheugen bewaart (in RAM). Dit levert zeer hoge prestaties op voor query’s, maar maakt het aan de andere kant moeilijk te gebruiken, of op zijn minst kostbaar in termen van infrastructuur, als de graph groot is, omdat je genoeg RAM moet hebben om de gegevens op te slaan. Memgraph wordt daarom over het algemeen gebruikt als prestaties de hoogste prioriteit hebben. Query’s worden gedaan in Cypher.
- GraphDB
GraphDB gebruikt een zeer specifiek graphmodel dat het Resource Description Framework (RDF) wordt genoemd. Dit framework, dat meer in detail zal worden besproken in de sectie Knowledge graphs, heeft zijn eigen querytaal die SPARQL heet. Er bestaat een gratis opensourceversie (graphDB Free) en een betalende enterpriseversie (graphDB Enterprise).
- Apache TinkerPop en de implementaties ervan
Het gaat om een opensource framework voor het definiëren van een graph database en een querytaal die “Gremlin” heet. Het wordt gebruikt in veel graph database management software, zoals JanusGraph (opensource software), Amazon Neptune dat andere modellen biedt dan die van TinkerPop zoals RDF, of nog andere tools voor databasebeheer die niet gespecialiseerd zijn in graphs, zoals Azure Cosmos DB.
Knowledge graphs
Laten we, voordat we naar werkwijzen en tools kijken, eerst definiëren wat een knowledge graph is en hoe deze verschilt van een graph database. Het is een graph die zich richt op semantiek en inferentie. Elke node vertegenwoordigt een concept en elke boog een relatie. Zoals we al hebben gezien in de blogposts [3, 4], wordt een knowledge graph gedefinieerd als een graph die aan drie voorwaarden voldoet [5]:
- De integratie van informatie uit verschillende heterogene bronnen.
Een knowledge graph verzamelt en combineert gegevens uit verschillende (on)gestructureerde bronnen op een coherente manier.
- Het gebruik van een ontologie.
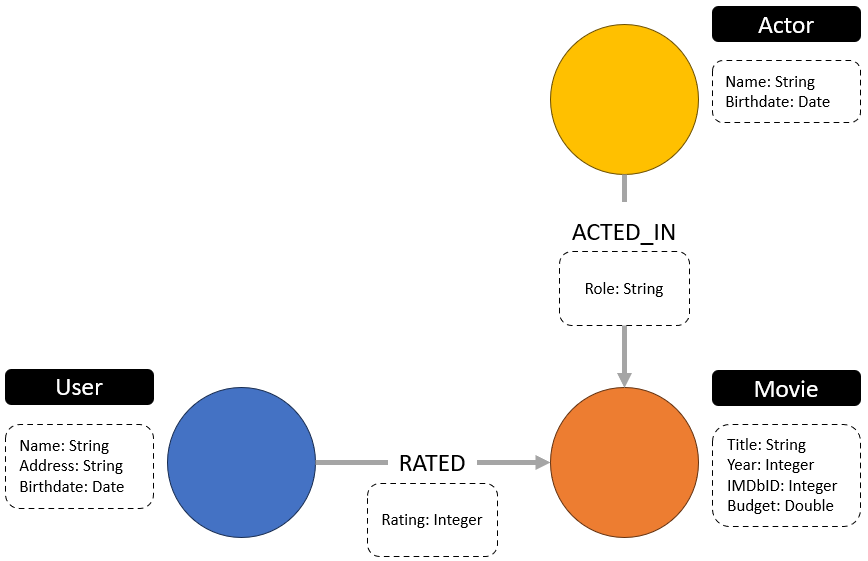
Een ontologie beschrijft formeel de concepten en relaties die aanwezig zijn in de graph, evenals eventuele beperkingen en regels. Het is dus een gestructureerd model dat de semantische basis biedt voor logische bewerkingen en coherentietesten. Een ontologieschema (zie Figuur 2), ook bekend als een ‘ontology graph’, biedt bijvoorbeeld een representatie van de entiteittypes en relaties van een knowledge graph, en biedt zo een conceptuele structuur zonder specifieke gegevens te bevatten.
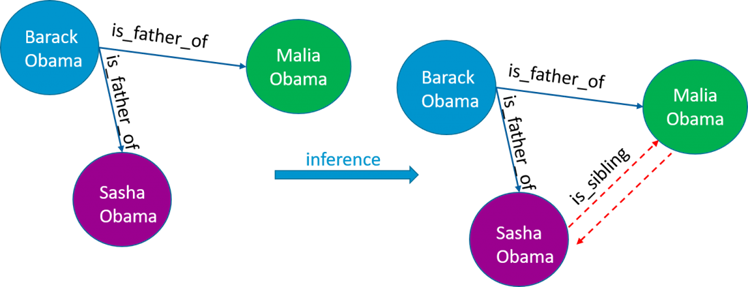
- Inferentie van impliciete informatie op basis van expliciete informatie.
Het is mogelijk om informatie te vinden die niet aanwezig was in de oorspronkelijke gegevens op basis van inferentieregels (zie Figuur 3).
Een overzicht van het RDF-model (Resource Description Framework)
Het RDF-model, oorspronkelijk ontworpen voor de formele beschrijving van web resources en de metadata ervan, wordt vaak gebruikt bij knowledge graphs omdat het robuust semantisch rederneren en een zeer hoge interoperabiliteit biedt.
Een RDF-document heeft de vorm van een set RDF-triples waarbij elk triple een associatie is: subject (te beschrijven bron), predicaat (eigenschap van de bron), object (gegevens of andere bron).
Bijvoorbeeld:
:Alice :knows :Bob .
:Alice :livesIn :Paris .
:Alice :age 30 .
Deze semantic triples vertegenwoordigen dus zowel relaties tussen nodes (bijvoorbeeld de relatie tussen Alice en Bob) als eigenschappen (de leeftijd van Alice).
Kenmerkend voor RDF is dat elk element van een triple (met uitzondering van het object als het een simpele waarde is, zoals de waarde 30 voor de leeftijd van Alice) door een URI (Uniform Resource Identifier) of IRI (Internationalized Resource Identifier) moet worden geïdentificeerd. Dit zorgt voor een hoge mate van interoperabiliteit, omdat het voorkomt dat er duplicaten ontstaan wanneer verschillende informatiebronnen worden gecombineerd. Als we teruggaan naar de eerder gebruikte triples, krijgen we het volgende fragment (in Turtle-taal):
<http://example.org/Alice> <http://example.org/knows> <http://example.org/Bob> .
<http://example.org/Alice> <http://example.org/livesIn> <http://example.org/Paris> .
<http://example.org/Alice> <http://example.org/age> "30"^^<http://www.w3.org/2001/XMLSchema#integer> .
Het gebruik van RDF impliceert daarom een URI om alle concepten (subjecten, predikaten en objecten) in de graph te kunnen identificeren op dezelfde manier als een primaire sleutel in relationele databases.
Bovendien bestaan er twee hulpmiddelen om semantische betekenis toe te voegen aan RDF-gegevens door relaties te beschrijven om redeneren mogelijk te maken, namelijk RDFS (RDF Schema) en OWL (Web Ontology Language). Zoals we al hebben gezien, vereist RDF dat elk concept wordt geïdentificeerd door een URI. RDFS en OWL bieden een voorgedefinieerde set URI’s voor veelgebruikte concepten waarnaar verwezen kan worden in RDF. Dit maakt het mogelijk om een gestandaardiseerd gemeenschappelijk vocabularium te hebben, wat de integratie met andere databanken vergemakkelijkt, en om inferentieregels op te stellen. Aangezien OWL en RDFS gestandaardiseerde concepten aanbieden, kunnen OWL-gebaseerde ‘reasoners’ (zoals FaCT++ of HermiT) op een systematische manier impliciete relaties afleiden of tegenstrijdigheden detecteren op basis van de ontologie.
Query’s op een RDF database worden gedaan via SPARQL.
Alternatieven voor RDF en tools voor het werken met een knowledge graph
Natuurlijk is het voor een knowledge graph niet noodzakelijk om het RDF-model te gebruiken. Een graph wordt als een knowledge graph beschouwd als voldaan is aan de 3 voorwaarden die beschreven zijn aan het begin van het hoofdstuk over knowledge graphs. Het is dus perfect mogelijk om een knowledge graph te creëren in een klassieke graph databasemanagementtool, zolang de implementatie data uit verschillende bronnen combineert, voldoet aan een ontologie en gebruikt kan worden voor semantische inferentie.
De voornaamste kracht van het RDF-model is zijn hoge standaardisatieniveau. Enerzijds laat het een hoge mate van interoperabiliteit toe dankzij de URI-identificatievereiste en de gestandaardiseerde woordenschat en querytaal. Anderzijds bieden de RDFS- en OWL-uitbreidingen een schat aan semantische informatie voor automatisch redeneren. Omgekeerd beperkt de complexiteit het gebruik in zakelijke toepassingen waar deze semantische nauwkeurigheid niet noodzakelijk is en waar het gebruik van een eenvoudiger graphmodel (zoals Neo4j of TigerGraph) volstaat. Het gebruik van eenvoudigere modellen heeft het voordeel dat ze eenvoudiger en sneller op te zetten zijn en optimale query prestaties bieden, maar ten koste van het verlies van de semantische rijkdom die RDF biedt.
In deze sectie worden (niet-exhaustieve) tools met betrekking tot RDF voorgesteld, maar zoals vermeld blijven de tools die eerder werden vermeld voor graph databases geldig voor het creëren van een knowledge graphs zolang aan de voorwaarden wordt voldaan.
Hier is een lijst van enkele tools gerelateerd aan knowledge graphs in RDF:
- Ontwerp van ontologieën: de opensourcetool Protégé wordt vaak gebruikt om ontologieën te creëren. De website Schema.org biedt een groot aantal standaard schema’s en vocabulaires voor verschillende domeinen, maar wordt over het algemeen gebruikt voor knowledge graphs met betrekking tot webgegevens.
- Gegevens omzetten naar RDF: de tool R2RML kan gebruikt worden om relationele gegevens om te zetten in RDF. Ook het vermelden waard is D2RQ, dat toegang biedt tot een relationele database via een virtuele RDF knowledge graph.
- Dataopslag: naast de hierboven genoemde oplossingen (GraphDB en Amazon Neptune), kunnen we ook BlazeGraph en Apache Jena (opensource) vermelden, alsook Stardog en AllegroGraph (businessoplossingen).
- OWL reasoners: er bestaan veel OWL reasoners. Ze worden echter niet allemaal actief onderhouden of zijn niet altijd bruikbaar. De meest recente OWL reasoners lijst die we konden vinden dateert uit 2023 en is hier beschikbaar [6].
Tot slot willen we nog het RDF4J framework (Java framework) en rdflib (python library) vermelden voor interactie met RDF data.
Conclusie
Laten we afsluiten met een korte samenvatting van de belangrijkste concepten die een wiskundige graph onderscheiden van een graph database en een knowledge graph.
Een wiskundige graph is een verzameling van nodes en bogen die gemakkelijk kan worden voorgesteld in matrixvorm zodat er algoritmes op kunnen worden toegepast. Het is de onderliggende structuur van elke graph database of knowledge graph.
Een graph database bestaat uit een set van nodes, bogen en properties. De nadruk ligt op het opslaan van grote hoeveelheden gegevens binnen een graph structuur en het optimaliseren van query’s.
Een knowledge graph heeft als doel om kennis binnen een graph weer te geven met de nadruk op:
- Semantiek: de graph volgt een ontologie en relaties hebben betekenis.
- Integratie: verschillende databronnen zijn gekoppeld in een uniforme graph.
- Inferentie: het vermogen om kennis af te leiden door redeneren.
Daarom is het gericht op de integratie en de semantische verrijking van data.
Het spreekt voor zich dat deze post slechts een tipje van de sluier oplicht van de uitgebreide literatuur over graphs en de verschillende toepassingen ervan. Vele punten moeten nog verder uitgewerkt worden en zullen ongetwijfeld het onderwerp zijn van toekomstige blogposts.
Referenties
[2] Sept (bonnes) raisons d’utiliser une Graph Database
[3] Les graphes de connaissance, incontournable pour l’intelligence artificielle
[4] Smals KG Checklist: déterminer si un graphe de connaissances peut résoudre un problème concret
[5] Ehrlinger, L., & Wöß, W. (2016). Towards a definition of knowledge graphs. SEMANTiCS 2016, 48(1-4), 2.
[6] Abitch, K., (2023). “OWL Reasoners still useable in 2023”
Dit is een ingezonden bijdrage van Pierre Leleux, data scientist et network data analyst bij Smals Research. Dit artikel werd geschreven in eigen naam en neemt geen standpunt in namens Smals.