Introduction aux systèmes de recommandation
Recommended for you …
Customers who bought this item also bought …
You may also like …
Nous retrouvons fréquemment ces messages lors de nos achats en ligne, quand nous consultons un article sur un site internet, quand nous écoutons de la musique ou que nous regardons un film sur des plateformes de streaming. Les systèmes de recommandations font partie de notre quotidien mais leur utilisation ne se limite pas nécessairement au commerce en ligne.
Quand peut-on utiliser un système de recommandation ?
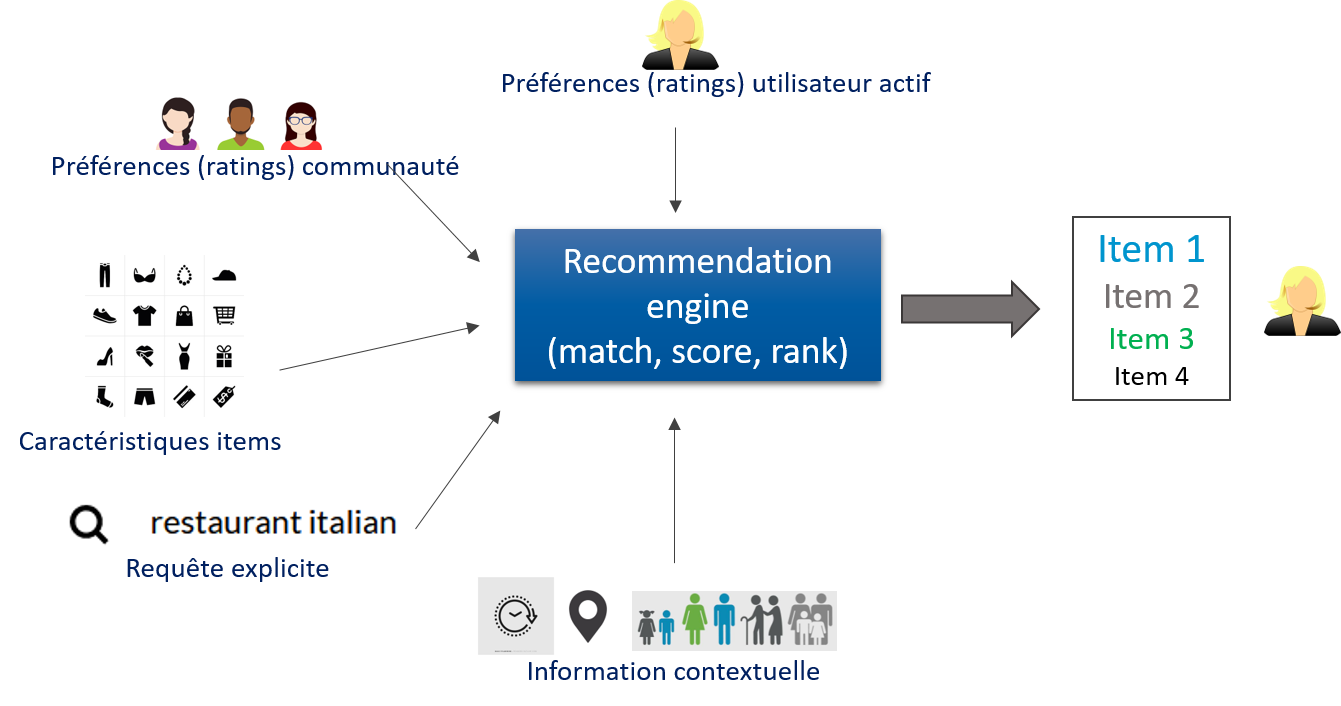
Globalement, un système de recommandation est un système de filtrage qu’on applique dans un contexte où il y a trop d’information pour l’utilisateur. Celui-ci passerait beaucoup de temps à retrouver l’information ou l’item qui l’intéresse ce qui pourrait causer une certaine frustration . C’est aussi un moyen de proposer des produits inconnus de l’utilisateur mais susceptibles de l’intéresser.
Le principe du système de recommandation est de faire correspondre à l’utilisateur des items ou des contenus en se basant sur ses interactions précédentes avec le système et en tenant compte de ses préférences. Toutes sortes d’items peut-être recommandées : vidéo, musique, vêtement, application, document, article, …. Le but est entre autres d’accroître la satisfaction de l’utilisateur en personnalisant son expérience sur le site ou en lui envoyant des messages ciblés via des canaux tels que les emails, les newsletters, ….
Les systèmes de recommandation peuvent être classés en quatre grandes catégories, chaque approche ayant ses avantages et ses inconvénients:
- L’approche collaborative filtering: les recommandations sont basées sur les préférences (ratings, actions) de l’utilisateur et de ses pairs
- L’approche content-based filtering: les recommandations sont basées sur les préférences/le profil de l’utilisateur et les caractéristiques de l’objet recommandé
- L’approche knowledge-based: les recommandations sont basées sur les spécifications de l’utilisateur et les caractéristiques de l’objet recommandé
- L’approche hybride qui consiste à combiner les précédentes
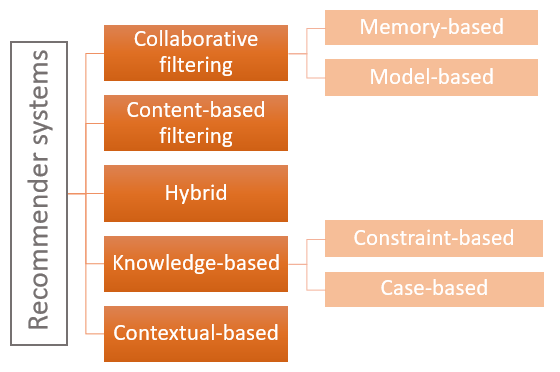
L’approche knowledge-based est la moins utilisée et ne sera pas abordée dans ce blog.
Collaborative filtering
La technique de collaborative filtering utilise la connaissance des préférences de l’utilisateur actif (l’utilisateur à qui on veut faire une recommandation) c.à.d. les items qu’il a le plus consultés dans le passé ainsi que les préférences d’une large communauté d’utilisateurs. Le collaborative filtering s’appuie sur deux paradigmes :
- Des utilisateurs similaires expriment des préférences similaires et donnent des notes similaires (approche user-based). On prédit la préférence d’un utilisateur A pour un item X sur base des ratings donnés dans le passé par des utilisateurs ayant les mêmes intérêts que A à l’item X.
- Des items similaires reçoivent des ratings similaires. Pour prédire le rating que donnerait l’utilisateur A à l’item X, on se base sur les ratings donnés par cet utilisateur à des items similaires à X (approche item-based).
Quels types de données?
Les données nécessaires pour l’implémentation d’un tel système sont les interactions entre utilisateurs et items (produits, contenus, …). Ces données se présentent sous forme de matrice utilisateurs-items dont chaque élément ui donne une indication de la préférence de l’utilisateur u pour l’item i. Cette matrice est dite creuse car il n’y pas de valeurs pour beaucoup de ses éléments. Le but de l’algorithme est donc de prédire les cellules vides, afin de connaître le degré d’intérêt d’un utilisateur pour un item. Les valeurs composant la matrice sont typiquement des ratings (notes) et celles-ci peuvent être de plusieurs types :
- Les ratings explicites. L’utilisateur est invité à donner une note à un item (une notation allant de 1 à 5 étoiles est couramment utilisée). Ces ratings explicites sont particulièrement difficiles à obtenir.
- Les ratings implicites. L’utilisateur ne donne pas de note aux items mais celle-ci est calculée à partir de certaines observations telles que le nombre de cliques, le temps de consultation de la page, etc. Dans ce cas, la note calculée est une mesure approximative de l’intérêt de l’utilisateur pour un item.
- Les ratings binaires. La préférence positive ou négative est clairement exprimée. Ex : j’aime/je n’aime pas
- Les ratings unaires. Seule la préférence positive est exprimée. Ex : achat d’un livre {Oui, Non}.
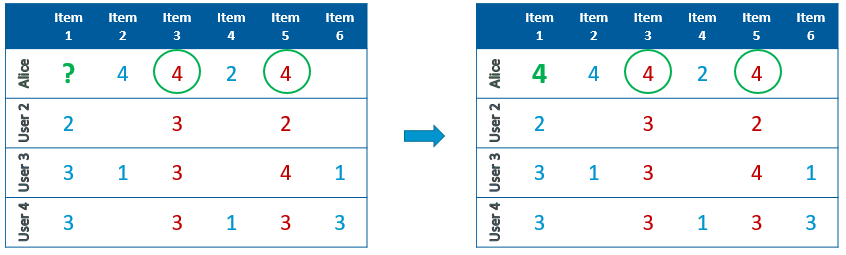
Exemple de matrice utilisateurs-items avec des ratings explicites
Pour connaître la préférence de l’utilisateur Alice pour l’item 1, on retrouve les items similaires à l’item 1 et pour lesquelles Alice a donné un rating. On utilise les ratings donnés par Alice aux items 3 et 5 pour prédire le rating de l’item 1.
Comment collecter ces données ?
Deux cas de figure peuvent se présenter:
- L’utilisateur est connecté avec son compte. Il est alors aisé de lier les observations collectées lors de l’utilisation du site internet à son compte et de créer un profil utilisateur
- L’utilisateur n’est pas connecté avec son compte. Les cookies peuvent être utilisés pour indirectement identifier l’utilisateur et le rattacher à son compte ou pour créer un profil anonyme qui suit l’utilisateur lors de ces interactions suivantes. Cependant, ces données ne sont pas tout à fait fiables : l’appareil utilisé peut être commun à plusieurs personnes, l’utilisateur se connecte avec plusieurs appareils, l’utilisateur se connecte avec un VPN, sans parler des problèmes de respect du RGPD que de telles pratiques peuvent soulever.
Comment se fait la recommandation ?
Pour faire une recommandation d’items à un utilisateur actif (à qui on veut faire la recommandation), il faut au préalable prédire son degré d’intérêt pour les items pour lesquels il n’a pas donné de ratings. Les items obtenant les scores les plus élevés sont proposés à l’utilisateur. Il y a pour cela deux façons de procéder :
- L’approche basée sur les voisins. On trouve des utilisateurs ayant des préférences similaires à celle de l’utilisateur actif c.-à-d. partageant un historique commun. On calcule ensuite le rating manquant en faisant une moyenne pondérée des ratings attribués par les k utilisateurs les plus similaires (fonction de préférence). Cette méthode pose des problèmes de performances quand la matrice utilisateur-item est très large.
- L’approche basée sur l’apprentissage d’un modèle. Elle vise à pallier le problème de performance observé avec la technique des voisins. La méthode la plus couramment utilisée est la factorisation matricielle (SVD, facteurs latents) qui permet de représenter la matrice originale par deux matrices de plus petites tailles à partir desquelles on peut prédire les scores manquants.
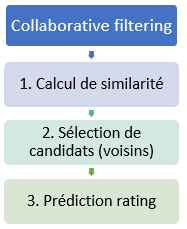
Étapes de recommandation pour un système collaboratif
Un exemple d’application pratique: cette technique est appliquée en combinaison avec d’autres pour la recommandation de vidéos sur Youtube. Pour un utilisateur donné A, on recommandera les vidéos que des utilisateurs B et C ayant quasi le même historique de visionnage ont regardé mais que A n’a pas encore regardé.
Avantages et inconvénients
Les systèmes de recommandation collaboratifs sont faciles à démarrer et nécessitent uniquement d’avoir un historique d’interactions entre utilisateurs et items ; plus l’historique est important, plus la recommandation sera pertinente. Néanmoins, cette méthode a un problème de démarrage à froid (voir ci-dessous) pour les nouveaux utilisateurs ou les nouveaux items.
Le problème de démarrage à froid
Quand un nouvel utilisateur rentre dans le système il n’a pas encore donné de score pour aucun item, on ne peut donc pas connaitre ses préférences. De même, lorsqu’un nouvel item est introduit, on ne dispose pas d’indication des préférences des utilisateurs par rapport à cet item.
Content-based filtering
Le principe des systèmes de recommandation basé sur le contenu diffère du système collaboratif dans le fait qu’on utilise uniquement les préférences de l’utilisateur actif pour faire les recommandations. L’objectif est de retrouver des items similaires à ceux pour lesquels l’utilisateur a exprimé une préférence dans le passé. Chaque item possède des attributs (content) qui sont exploités pour faire la recommandation. Ces attributs constituent un descriptif de l’item qui se présente sous forme nominale (ex. : genre et auteur d’un livre) ou sous forme de texte libre.
Quels types de données?
Les ratings de l’utilisateur actif et les descriptifs des items sont utilisés. Les interactions historiques entre l’utilisateur et les items sont utilisées pour construire un profil.
Comment se fait la recommendation ?
Pour chaque utilisateur on définit un profil qui exprime les préférences de l’utilisateur. La méthode la plus simple est de construire le profil à partir d’attributs semblables à ceux des items. Le profil utilisateur est alors comparé aux attributs des items et les items les plus similaires sont recommandés à l’utilisateur. Pour faire le match entre le profil utilisateur et les items, on utilise des mesures de similarité telles que la similarité cosinus.
Une méthode plus élaborée consiste à transformer le problème de recommandation en un problème de classification. Pour chaque utilisateur, on entraine un modèle de recommandation (profil) qui prend en entrée les attributs d’un item et qui prédit l’intérêt de l’utilisateur pour cet item (like/dislike ou rating).
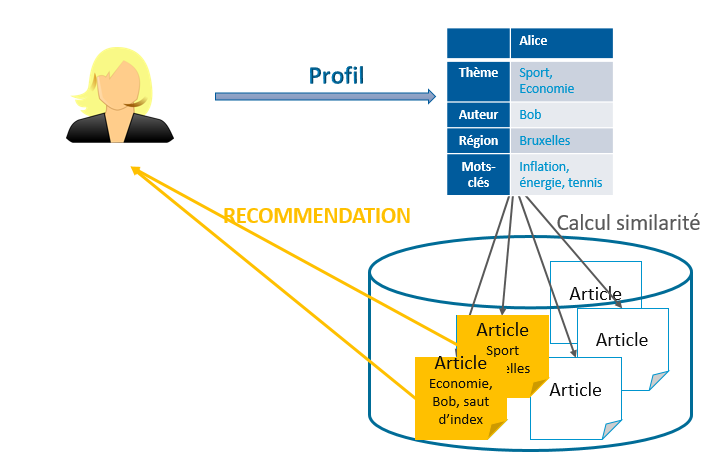
Recommandation de contenu
Exemple d’application pratique:
Recommandation de produits similaires à ceux achetés par le passé par l’utilisateur connecté.
Avantages et inconvénients
Seule l’historique de l’utilisateur actif est pris en considération, cette approche est efficace pour recommander des items peu populaires à un utilisateur ayant des goûts spécifiques. Elle résout en partie le problème de démarrage à froid car il est possible de calculer la préférence d’un utilisateur pour un nouvel item même si cet item n’a pas encore récolté de ratings : la prédiction se fait sur base des attributs de l’item. Par contre, il n’est pas possible de produire des recommandations pour un nouvel utilisateur. Une façon de contourner ce problème est de permettre à l’utilisateur de construire son profil en introduisant, par exemple, des mots-clés. Le fait de ne pas utiliser les données relatives à la communauté d’utilisateurs peut représenter un inconvénient car le modèle produit par l’approche content-based est spécifique à l’utilisateur, seuls les items ayant des attributs similaires à ceux déjà vu par l’utilisateur seront recommandés. L’utilisateur est alors renforcé dans ses goûts et perd en « découverte ». De plus, il est difficile d’établir un profil utilisateur c.-à-d. de trouver les attributs qui sont suffisamment pertinents pour faire correspondre les items à l’utilisateur d’autant plus que les goûts de l’utilisateur évoluent.
Système de recommandation hybride
Les méthodes collaboratives et les méthodes basées sur les contenus ont chacune leurs avantages et inconvénients. Dans la pratique, on implémente un système hybride de recommandation pour bénéficier des avantages de chacune de ces techniques tout en mitigeant les inconvénients. Un système hybride permet d’exploiter à la fois les descriptions des items (ou contenu) et les ratings de la communauté d’utilisateurs. Les moteurs de recommandation peuvent être combinés de plusieurs façons en fonction de problème:
- En mode monolithique : on implémente un moteur unique de recommandation qui combine des éléments des différentes techniques. Ex. : la similarité des items est calculée en utilisant les contenus, et la prédiction de la préférence de l’utilisateur par rapport à ces items se fait sur base des données des autres utilisateurs.
- En mode parallèle (ensembles) : plusieurs moteurs de recommandation tournent en parallèle et produisent chacun des résultats qui sont ensuite combinés et pondérés pour fournir la recommandation finale
- En mode séquentiel : les résultats d’un moteur de recommandation sont utilisés en entrée du moteur de recommandation suivant.
En conclusion, les systèmes de recommandation sont désormais incontournables pour fournir une expérience utilisateur personnalisée dans un contexte où il y a une multitude de choix possibles. Il faut pourtant prendre garde à ne pas construire des systèmes qui enferment l’utilisateur dans un groupe (méthode collaborative) ou dans ses goûts (méthode basée sur les contenus).
Dans ce blog, seules les deux méthodes les plus courantes ont été abordées mais il existe de nombreuses approches possibles et chaque problème de recommandation requiert une configuration propre.
_________________________
Ce post est une contribution individuelle de Katy Fokou, spécialisée en intelligence artificielle chez Smals Research. Cet article est écrit en son nom propre et n’impacte en rien le point de vue de Smals.