E-discovery
E-discovery is een algemene term voor technieken en software waarmee men informatie wil ontdekken in grote hoeveelheden heterogene documenten. “Document” mag daarbij breed geïnterpreteerd worden als eender welk bestand met machineleesbare informatie (e-mails, spreadsheets, presentaties, foto’s, …). Wat e-discovery onderscheidt van gewone data exploratie is dat men niet zozeer tracht een globaal overzicht te krijgen van de gegevens, maar vooral een specifieke vraag wil beantwoorden. Typische contexten waarin e-discovery wordt toegepast zijn gerechtelijke onderzoeken, onderzoeksjournalistiek, audits, of aanvragen in het kader van wetten op openbaarheid van bestuur.
Neem fraudebestrijding: op een reeks in beslag genomen harde schijven moeten bewijzen gevonden worden van, bijvoorbeeld, fraude met onkostennota’s. De inspecteur van dienst wordt geconfronteerd met veel te veel bestanden of emails om allemaal manueel te gaan uitpluizen, en onkosten kunnen gaan over vanalles en nog wat. Om geen bergen irrelevante info te moeten doorploegen zal men bijvoorbeeld eerst alle documenten willen groeperen waarin het woord “kost” of “rekening” in eender welke woordsamenstelling voorkomt. In een ander geval kan het dan weer nuttig zijn om alle emailconversaties tussen betrokken personen over een bepaald thema te kunnen afsplitsen van de rest. Nog een andere: alle documenten selecteren met het woord “factuur” in eender welke taal.
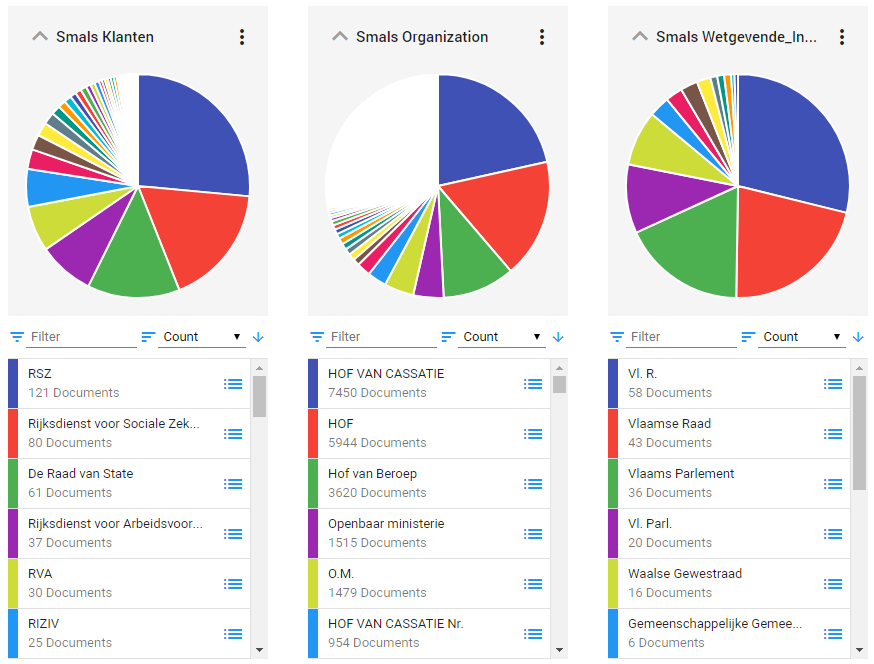
Segmentatie van datasets op basis van entiteiten herkend in de documentinhoud - visualisatie uit het e-discovery platform Zylab
In de juridische sector kan e-discovery worden ingezet om grote hoeveelheden jurisprudentie te doorzoeken naar eerdere zaken of naar wetgeving gerelateerd aan wat voorligt, om zo sneller een overzicht te krijgen van mogelijke argumenten.
In Nederland krijgt de overheid jaarlijks zo'n 1400 verzoeken tot openbaarmaking van documenten vanwege journalisten, actiecomités of burgers. Dat vereist telkens dat bij vele verschillende instanties mogelijk duizenden documenten moeten worden opgevraagd, gebundeld, en actief geanonimiseerd voor publicatie (nodig om de privacy van betrokken personen te beschermen, en zo GDPR-compliant te zijn). In België is het "wobben" vooralsnog niet zo populair [1, 2, 3, 4]. Vast staat wel dat de administratie die geconfronteerd wordt met de verplichting een groot intern dossier te publiceren, handenvol werk te wachten staat.

Documenten correct anonymiseren is een tijdrovend karwei zonder automatisering.
Dat soort grootschalige vragen beantwoord je niet in 1 keer. Veelal bekom je het antwoord pas na een iteratief proces van selecties en verfijningen. Gegeven de heterogeniteit en variabiliteit in de data, is het een kunst om zo snel mogelijk alle relevante documenten te groeperen, zonder enerzijds teveel irrelevante documenten te behouden of anderzijds relevante documenten over het hoofd te zien (dat selectieproces heet culling in het jargon). Om dat te faciliteren kunnen goede e-discovery tools ook machine learning inzetten, die de gebruiker toelaat classifiers te trainen die, naarmate er meer documenten zijn behandeld, steeds accurater zelf relevante documenten zullen kunnen identificeren, en/of daarin kunnen markeren wat eventueel nagekeken of geredigeerd moet worden voor publicatie. Het globale proces kan worden samengevat in het e-discovery reference model (EDRM):
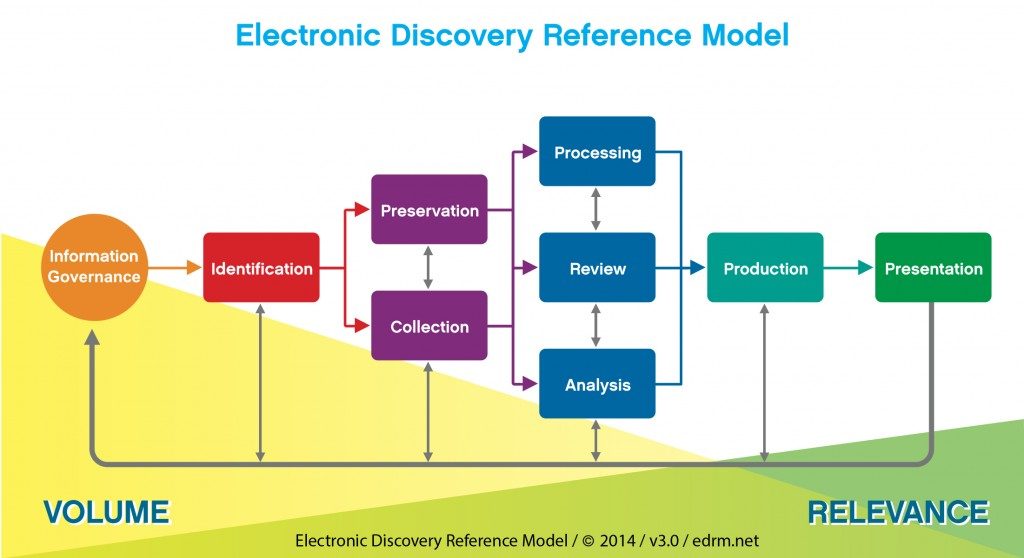
In een typisch e-discovery proces worden gegevens uit verschillende bronnen eerst verzameld in een soort “data lake”. Daarna wordt een breed spectrum van tools voor analyse op deze gegevens losgelaten die zoveel mogelijk nuttige metadata uit de gegevens extraheert en opslaat. Een geavanceerde zoekinterface laat toe om het geheel verder te organiseren en in de diepte en "fuzzy" te doorzoeken. Vaak zijn er mogelijkheden om zelf concepten te definiëren die men belangrijk vindt en wil extraheren - gaande van eenvoudige reguliere expressies, over allerlei vormen van named entity recognition, tot methodes van machine learning om moeilijker te vatten gecontextualiseerde informatie te kunnen capteren.
In de voorvermelde usecases wil men veelal binnen de inhoud van de documenten op zoek naar informatie waarvan men bovendien niet exact weet hoe die erin tot uiting komt. E-discovery tools trachten daarom vaak een vorm van “semantic search” aan te bieden en steunen daarvoor op allerlei technogieën die verder gaan dan enkel een full-tekst indexering van de gegevens: topic detection, clustering, classificatie, natural language processing, near-duplicate detection, zelfs sentiment analysis, kunnen allemaal nuttige indicatoren leveren die het zoekproces verfijnen. Tot slot zal een goed e-discovery platform, door het faciliteren van het iteratieve karakter van het zoekproces (extraheer - review - analyseer - extraheer - ...), aangevuld met batch editing en processing functionaliteit (denk aan het anonymiseren van vele documenten tegelijk), het verschil maken met een gewone zoekmotor op een database.
Goede e-discovery tools kunnen de fase van data verzamelen, organiseren, schoonmaken en prepareren, die anders al snel 80% van een data-analyseproject uitmaakt, optimaal stroomlijnen. De gebruikers van e-discovery tools zijn typisch geen IT-ers maar juristen, inspecteurs of journalisten. Een associatie zoals ACEDS verenigt gebruikers van e-discovery tools en organiseert opleidingen, certifiëringen of evenementen waarop best practices worden gedeeld.
Enkele van de grote aanbieders van e-discovery platformen op de markt zijn RelativityOne, OpenText EnCase, nuix, IBM, AccessData, LogikCull, nextpoint, Zylab. Sommige van deze spelers richten zich specifiek tot juridische wereld of het overheidswezen. Open source tools voor bovenvermelde usecases beperken zich op het moment van schrijven vooral tot de domeinen van cybersecurity en low-level computer forensics (bvb. Sleuthkit). Voor algemene e-discovery is FreeEed zo goed als het enige bestaande open source project.
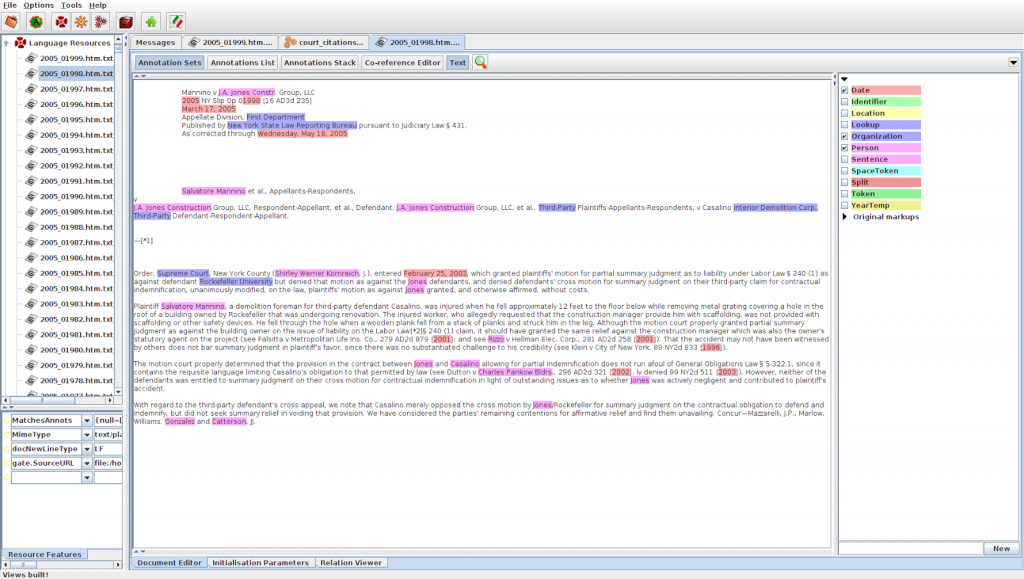
Screenshot van de open-source FreeEed e-discovery software met weergave van entity recognition.
Alles samengevat zijn gespecialiseerde e-discovery tools met name interessant wanneer je te maken krijgt met onoverzichtelijk grote datasets met een hele waaier aan documentformaten, waarin je gericht naar iets bepaalds op zoek bent, maar je hebt geen documentatie van de dataset of je kan niet rekenen op hulp van de eigenaar ervan - dus je zou niet weten waar te beginnen. Binnen de overheid kan dit vooral voor inspecteurs en auditeurs een hulp zijn, al kan vrijwel iedere overheidsdienst wel eens met een WOB-verzoek geconfronteerd worden waarvoor de archieven opengebroken moeten worden...
______________________
Dit is een ingezonden bijdrage van Joachim Ganseman, IT consultant bij Smals Research. Dit artikel werd geschreven in eigen naam en neemt geen standpunt in namens Smals.