Croisement des données personnelles avec le service de pseudonymisation à l’aveugle d’eHealth
Le nouveau service de pseudonymisation d’eHealth offre des garanties de sécurité élevées. Il est actuellement utilisé pour protéger la vie privée des citoyens, notamment lors du stockage et du traitement des ordonnances électroniques. Ce service se prête en outre particulièrement bien au croisement et à la pseudonymisation de données à caractère personnel dans le cadre de projets de recherche. Le présent article expose la manière dont cela serait possible d’un point de vue conceptuel.
Le service de pseudonymisation à l’aveugle d’eHealth
Le service de pseudonymisation à l’aveugle d’eHealth a déjà été décrit en détail dans un article précédent. Nous reprenons ici le scénario où un médecin (client) demande au service interne de prescription (owner) d’enregistrer une prescription électronique.
L’illustration 1 expose le flux de base: le médecin demande au service de pseudonymisation de convertir un identifiant en pseudonyme. Le médecin envoie ensuite le pseudonyme avec les données de l’ordonnance au service internet de prescription, qui stocke les données de la prescription sous ce pseudonyme.
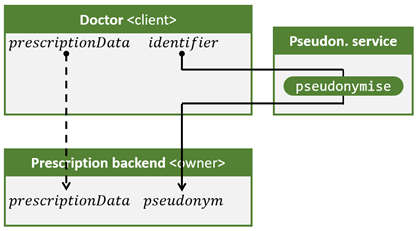
Illustration 1. Flux de base pour le scénario où un médecin (client) demande au service de prescription (owner) d’enregistrer une prescription électronique.
Afin d’atteindre un niveau de sécurité élevé, les dispositifs de sécurité suivants sont essentiels :
- Le client est hypermétrope: il ne voit que les identifiants globaux (numéros de registre national).
- Le owner (propriétaire) est myope: il ne voit que les identifiants locaux (pseudonymes).
- Le service de pseudonymisation est aveugle: il ne voit ni les identifiants ni les pseudonymes.
L’illustration 2 présente comment cela est possible en ajoutant un certain nombre d’étapes au flux de l’illustration 1.
- La caractéristique de sécurité service de pseudonymisation aveugle (3) est réalisée à l’aide des opérations blind et unblind (indiqué en violet). Le numéro de registre national du patient est masqué, ce qui correspond à un chiffrement de courte durée avec une clé qui n’est utilisée qu’une seule fois. Le service de pseudonymisation convertit le numéro de registre national masqué en un pseudonyme masqué, sans voir ni le numéro de registre national d’origine ni le pseudonyme résultant (oubliez les opérations indiquées en bleu et orange pour le moment ; nous y reviendrons plus tard). Seul le client peut lever l’occultation effectuée par blind à l’aide de l’opération unblind.
- Dans le flux de base de l’illustration 1, le owner ne connaît aucun numéro de registre national, de sorte que la caractéristique de sécurité owner myope (2) est déjà réalisée.
- Enfin, grâce aux opérations encrypt et decrypt (indiquées en orange), la caractéristique de sécurité client hypermétrope (1) est réalisée: le service de pseudonymisation chiffre le pseudonyme occulté de sorte que seul le owner puisse le déchiffrer.
Enfin, la réutilisation non autorisée des pseudonymes chiffrés – que le client obtient après l’opération unblind – est évitée parce que le service de pseudonymisation utilise l’opération add context (en bleu) pour ajouter des informations contextuelles au pseudonyme chiffré, telles que l’heure de création. Le owner vérifiera ces informations à l’aide de l’opération verify context (en bleu) et n’acceptera que les pseudonymes chiffrés reçus qui ont été créés récemment.
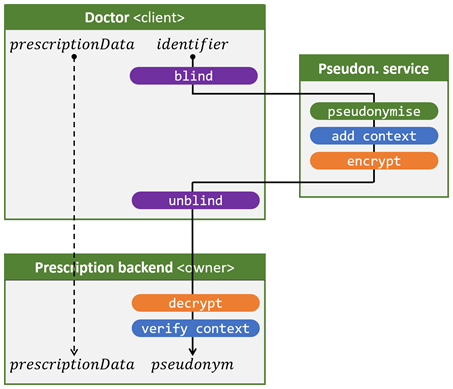
Illustration 2. Flux High security pour le scénario où un médecin (client) demande au service de prescription (owner) d’enregistrer une prescription électronique.
L’opération convert
Dans la section précédente, le service de pseudonymisation a appliqué spécifiquement l’opération pseudonymise pour convertir les numéros de registre national en pseudonymes. Dans certains scénarios, l’opération inverse est également nécessaire, à savoir l’opération d’identification, où un pseudonyme connu du owner est reconverti en numéro de registre national d’origine du côté d’un client.
Les systèmes (owner) communiquent également les uns avec les autres. Un service sur la plateforme eHealth pourrait demander au service TherLink si un patient a une relation thérapeutique avec un médecin en particulier. Si TherLink utilise également des pseudonymes, le pseudonyme d’un service/owner devra être converti en pseudonyme de l’autre service/owner. Cela s’effectue à l’aide de l’opération convert. En effet, afin de minimiser le risque d’identification, il convient de ne pas réutiliser les pseudonymes dans plusieurs services.
Ainsi, les trois opérations que le service de pseudonymisation doit prendre en charge sont pseudonymise, identify et convert. Nous verrons que les opérations pseudonymise et convert sont toutes deux utiles pour croiser et pseudonymiser des données à caractère personnel. À l’inverse, l’opération identify nous permet de procéder à l’identification contrôlée des citoyens. Cela peut être souhaitable dans certaines situations, par exemple lorsque des chercheurs découvrent que certains citoyens courent un risque très élevé de souffrir de certaines maladies, ou qu’ils en sont déjà atteints sans le savoir.
Croisement des données à caractère personnel – l’approche actuelle
Pour les besoins de la recherche, les données à caractère personnel provenant de différentes sources sont régulièrement croisées et pseudonymisées. Cette dernière mesure est nécessaire pour empêcher le chercheur d’établir un lien entre les données à caractère personnel et les personnes physiques.
Prenons comme exemple concret la délibération 13/093 du 22 octobre 2013, qui donne à Sciensano l’accès à des données médicales provenant de différents hôpitaux, dans le but d’obtenir des informations sur l’épidémiologie des patients atteints de diabète. Ce faisant, Sciensano ne découvre pas de numéro de registre national, mais uniquement des pseudonymes.
L’illustration 3 montre – de manière quelque peu abstraite – comment cela est fait à ce jour en utilisant eHealth Batch Codage, un service de pseudonymisation qui existe depuis un peu plus longtemps que notre service de pseudonymisation à l’aveugle. dataAid est la donnée relative au citoyen avec le numéro de registre national id fourni par l’hôpital A.
Pour chaque citoyen concerné, les hôpitaux envoient les données demandées directement à Sciensano et le numéro de registre national à eHealth Batch Codage. Ce dernier convertit le numéro de registre national en un pseudonyme spécifique au projet, le pseudonymlinkid, et envoie ce pseudonyme à Sciensano. Sciensano reçoit donc les données provenant d’un hôpital par un canal et les pseudonymes provenant de Batch Codage par un autre canal. Grâce à un pseudonyme de transit temporaire (par exemple nymAid), qui est caché à Batch Codage, Sciensano est en mesure de relier les données aux pseudonymes spécifiques au projet. Enfin, grâce à ces pseudonymes spécifiques au projet, Sciensano peut relier des données concernant le même citoyen mais provenant de sources différentes.
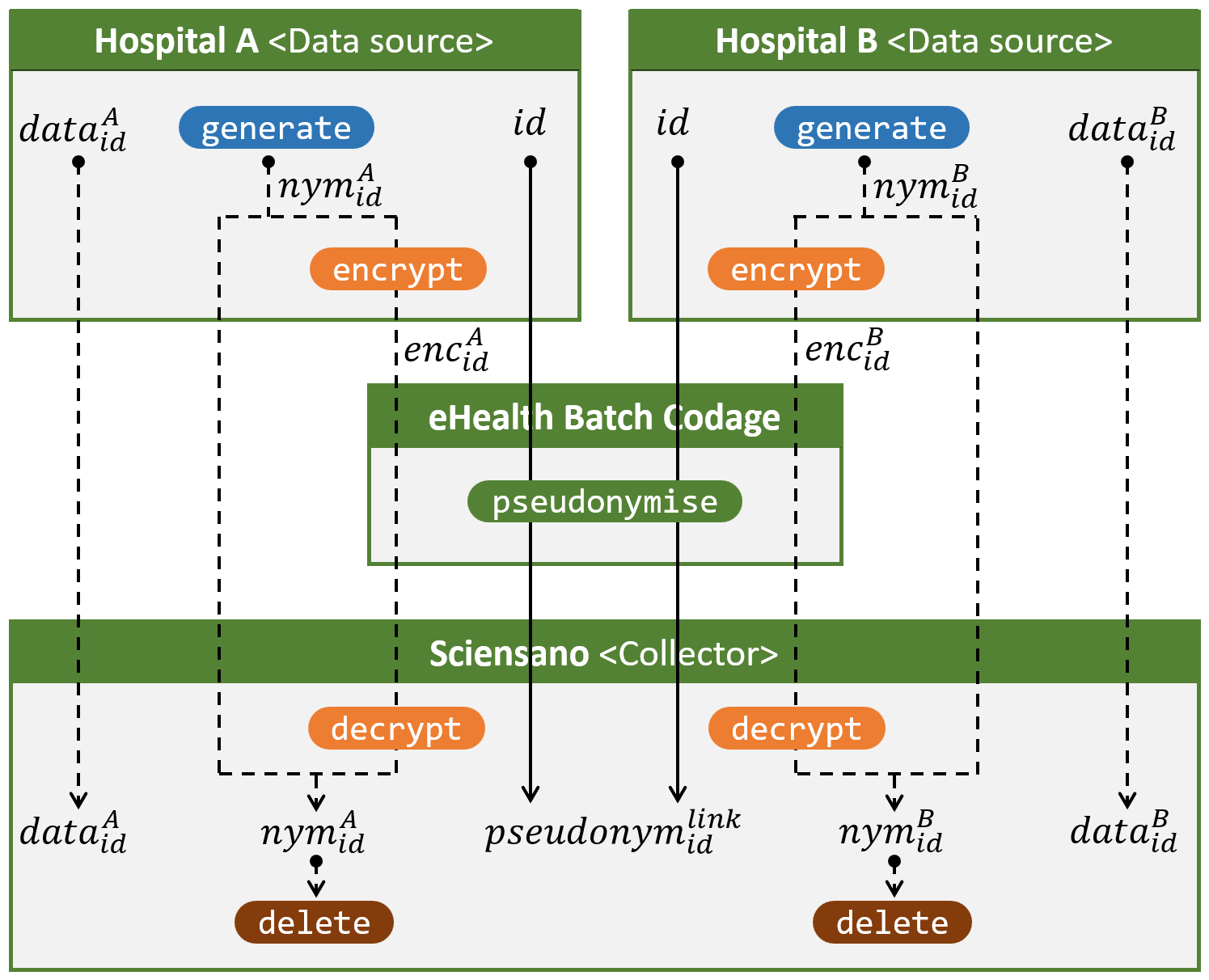
Illustration 3. Croiser et pseudonymiser les données à caractère personnel provenant de plusieurs hôpitaux et destinées à Sciensano, comme décrit dans la délibération 13/093.
Cette approche présente un certain nombre d’inconvénients :
- Le Batch Codage doit être fiable. Il s’agit d’un tiers de confiance (Trusted Third Party TTP) ; il voit à la fois les numéros de registre national entrants et les pseudonymes sortants. Il sait à quel projet de croisement il collabore et peut donc théoriquement établir des profils pour chaque citoyen ; par exemple, après deux projets, il sait quels citoyens ont participé à la fois à la recherche sur le diabète et sur la sclérose en plaques. Ces profils pourraient éventuellement contenir un grand nombre d’informations sensibles.
- Deux canaux de communication. Sciensano devrait être en mesure de relier les données reçues directement des hôpitaux aux pseudonymes reçus du Batch Codage. Bien qu’il existe une solution, il serait plus élégant que toutes les informations soient envoyées directement de l’hôpital à Sciensano par un seul canal.
- Mauvaise intégration lorsque les données sont pseudonymisées. Ce système ne peut pas traiter de manière élégante les situations où une ou plusieurs sources de données utilisent déjà le service de pseudonymisation à l’aveugle décrit plus haut et n’ont donc pas elles-mêmes de numéro de registre national.
Croiser des données personnelles avec le service de pseudonymisation à l’aveugle
Les trois inconvénients décrits dans le paragraphe précédent pourraient être résolus en utilisant dès à présent le service de pseudonymisation à l’aveugle.
Le scénario dans lequel toutes les sources de données conservent les données à caractère personnel sous le numéro de registre national est représenté dans l’illustration 4. Le flux entre un hôpital (data source) et Sciensano (collector) est exactement le même que celui de l’illustration 1, les trois propriétés de sécurité formulées précédemment étant évidemment maintenues :
- Les sources de données (data source, par exemple les hôpitaux) sont hypermétropes et ne voient donc que les numéros de registre national
- Le collector (par exemple Sciensano) est myope et ne voit donc que les pseudonymes spécifiques au projet
- Le service de pseudonymisation est aveugle et ne voit donc aucun des deux.
Si plusieurs sources de données fournissent des données sur le même citoyen, elles communiquent le même numéro de registre national au flux de pseudonymisation (ligne pleine), ce qui donne le même pseudonyme spécifique au projet du côté du collecteur. Cela permet au collecteur de relier les données sur le même citoyen provenant de différentes sources de données.
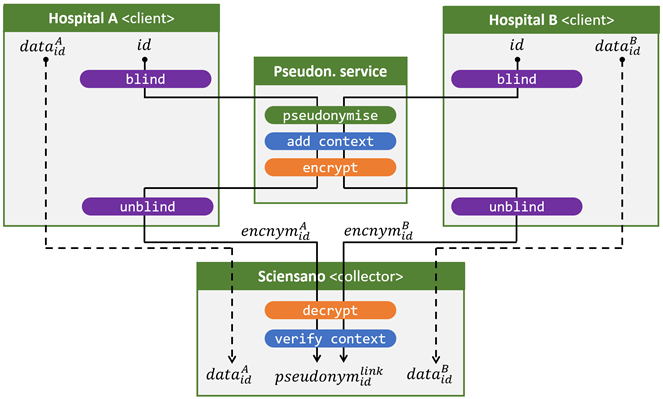
Illustration 4. Croisement et pseudonymisation de données provenant de différentes sources de données, qui stockent toutes des données à caractère personnel sous des numéros de registre national.
L’illustration 5 présente pour finir un scénario mixte, dans lequel au moins une source de données stocke des données à caractère personnel sous des numéros de registre nationaux et au moins une source de données stocke des données à caractère personnel sous des pseudonymes obtenus à l’aide du service de pseudonymisation à l’aveugle. Cette dernière source de données pourrait, par exemple, être le service interne de prescription de l’illustration 1.
Nous obtenons donc deux variantes du flux de pseudonymisation (ligne pleine) :
- Le service de pseudonymisation reçoit un pseudonyme en aveugle de la source de données A et effectue une opération convert (voir la section “L’opération convert“) pour obtenir un pseudonyme à l’aveugle spécifique au projet.
- Le service de pseudonymisation reçoit un numéro de registre national en aveugle de la source de données B et effectue une opération pseudonymise pour obtenir un pseudonyme à l’aveugle spécifique au projet.
Dans le cas où le pseudonyme que la source de données A a donné en entrée correspond au numéro de registre national que la source de données B a donné en entrée, il en résultera le même pseudonyme spécifique au projet chez Sciensano.
Dans le cas contraire, les deux flux sont identiques. Rien ne change ni pour les sources de données (par exemple, les institutions publiques) ni pour le collector (par exemple, Sciensano). Le collector n’a même pas besoin de savoir si une source de données utilise des pseudonymes ou non.
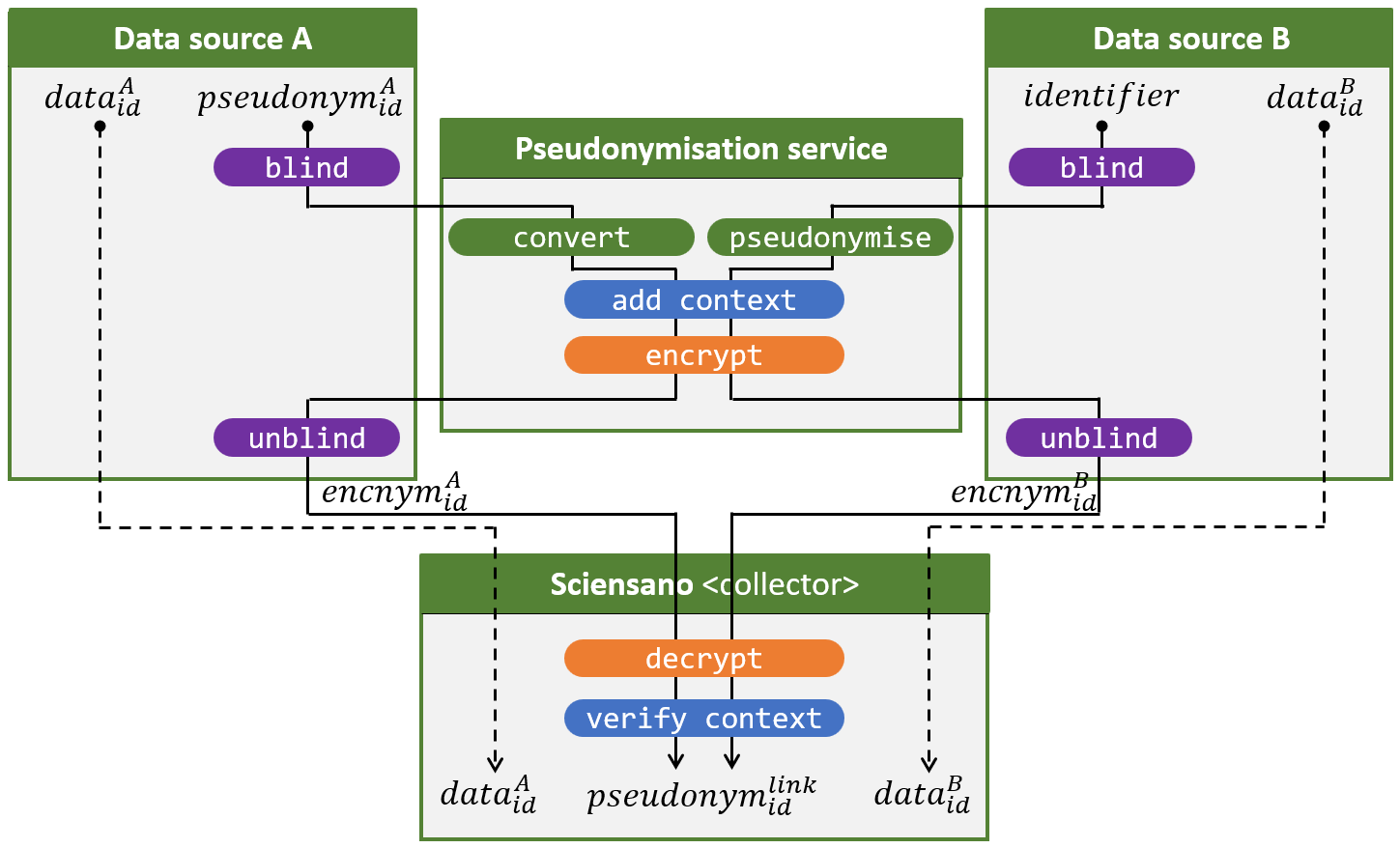
Illustration 5. Croiser et pseudonymiser les données provenant de deux sources de données, l’une stockant les données à caractère personnel sous des numéros de registre national et l’autre sous des pseudonymes.
Les inconvénients de l’approche actuelle mentionnés précédemment sont supprimés :
- Le service de pseudonymisation ne voit ni les identifiants ni les pseudonymes et ne peut donc plus créer de profils. En outre, le fait d’effectuer plusieurs fois une opération en aveugle sur le même numéro de registre national (ou pseudonyme) donne lieu à une opération en aveugle différente à chaque fois. Le service de pseudonymisation ne peut donc pas non plus utiliser les identifiants ou les pseudonymes masqués pour relier les informations de profil.
- Le collector (par exemple Sciensano) reçoit toutes les informations provenant de la même source de données (par exemple, l’hôpital) par un seul canal direct.
- Nous pouvons traiter de manière particulièrement élégante les situations dans lesquelles une ou plusieurs sources de données utilisent déjà le service de pseudonymisation à l’aveugle.
Conclusion
Grâce au service de pseudonymisation à l’aveugle d’eHealth, nous pouvons élégamment et en toute sécurité croiser et pseudonymiser des données provenant de différentes sources de données à des fins de recherche.
En outre, un autre avantage est qu’aucune infrastructure supplémentaire n’est nécessaire ; beaucoup plus de prescriptions sont émises et traitées pendant la journée que pendant la nuit. Par conséquent, la capacité de pseudonymisation est largement excédentaire pendant la nuit. C’est donc le moment idéal pour réaliser de tels projets de croisement, qui ne sont pas critiques en termes de temps. Bien entendu, les missions critiques en termes de temps sont toujours prioritaires.
Pour chaque projet de croisement, le service de pseudonymisation utiliserait une clé différente, ce qui entraînerait l’impossibilité de relier les pseudonymes au niveau du collecteur ; il ne serait alors pas en mesure de relier les données relatives au même citoyen, mais provenant de projets différents, sur la base des pseudonymes.
Si cela s’avère nécessaire, la réidentification est possible grâce à l’opération identify, mais uniquement avec l’autorisation et la coopération du service de pseudonymisation, ce qui permet d’éviter l’arbitraire et les abus. Ces demandes doivent également être enregistrées. Le service de pseudonymisation peut également, si nécessaire, retirer la clé de pseudonymisation à un moment convenu, rendant ainsi impossible toute réidentification par ce moyen.
Bien entendu, les opérations blind et unblind doivent être prévues dans le logiciel utilisé par les sources de données, tandis que du côté du collecteur, les opérations decrypt et verify context doivent être prévues. L’expérience montre que cette intégration se fait sans problème.
Il convient toutefois de noter que cette approche n’est utile que si toutes les sources de données peuvent déterminer de manière autonome quels enregistrements sont pertinents et lesquels ne le sont pas. Ce n’est pas toujours le cas, comme par exemple dans le projet de croisement des données approuvé pendant la délibération 20/020 du 14 janvier 2020, où la Fondation Registre du Cancer est le seul à pouvoir fournir des données sur les citoyens atteints de sclérose en plaques (SEP), mais ne peut pas savoir qui est atteint de SEP. Smals Research a également trouvé une solution efficace et flexible pour cela. Cette solution est accessible à tous, ce qui élimine la nécessité d’un service de pseudonymisation pour assurer la sécurité de la pseudonymisation. Cela dépasse toutefois le cadre de cet article.
Si notre solution ou d’autres solutions de pseudonymisation et de référencement croisé des données à caractère personnel vous intéressent, n’hésitez pas à nous contacter.
Cette contribution a été soumise par Kristof Verslype, cryptographe chez Smals Research. Elle a été rédigée en son nom propre et ne prend pas position au nom de Smals.
Image source: Pixabay