5 vragen om te stellen voor de start van een AI-project
De hype rond AI valt niet te ontkennen, maar dat mag niet betekenen dat alle realiteitszin uit het raam gekieperd mag worden. Een nuchtere analyse op voorhand blijft noodzakelijk voor een betere inschatting van de ROI, risico's en afhankelijkheden van elk project. Er bestaan al vragenlijsten voor zulke SWOT-achtige analyses die specifiek zijn toegespitst op AI-projecten, met verschillende niveau's van technische diepgang of over verschillende subthema's. Enkele goede startpunten zijn onder andere:
- "Key questions for the board" uit J.B. Mantas, Intelligent Approaches to AI
- Gartner toolkit: Selecting and Prioritizing AI Use Cases
- De Data Protection Impact Assessment template op gdpr.eu (geen officiële EU-publicatie)
- Het ontwerp van een Trustworthy AI Assessment list, in voorbereiding door de EU High Level Expert Group on AI
- De Data Project Checklist van Fast.AI
- ...
De ene vragenlijst is technisch, de andere descriptief, nog andere proberen zoveel mogelijk in cijfertjes te gieten. Dé ultieme checklist maken is onbegonnen werk, want veel hangt af van wie het doelpubliek is van de analyse: de projectleider vindt andere dingen belangrijk dan de CEO, de aandeelhouder of de eindgebruiker.
Goed beseffend dat nòg een extra vragenlijst dat probleem niet oplost, kunnen we het toch niet laten om zelf ook enkele overwegingen te lanceren die wij maken in ons werk bij overheidsdiensten. Zonder te claimen volledig te zijn, 5 kernvragen die wij ons vaak stellen:
1. Hoe zou je het probleem oplossen zonder AI?
Is er wel een goede usecase, en vereist die wel een AI-oplossing? Te vaak wordt AI voorgesteld als hét toverstokje dat alle problemen oplost vanuit het niets. Was dat maar waar: in het echte leven zijn AI-systemen moeilijk om goed geconfigureerd te krijgen, vragen ze constante opvolging en monitoring, en veel werkuren door specialisten. Een dure zaak, daarom kan het geen kwaad om eerst grondig na te gaan: wat is eigenlijk het probleem dat we willen oplossen? Is dat welgedefinieerd en goed afgelijnd? Wat is de situatie vandaag en waar willen we naartoe? Weegt de geschatte ROI van een AI-oplossing wel op tegen die van een aanpak met traditionele IT of zelfs manueel werk? Heb je die andere opties überhaupt overwogen?
2. Zijn de succescriteria (KPIs) goed gekozen, gedefinieerd en meetbaar?
Een enkel AI-systeem lost veelal een klein, welomschreven probleem op. Allerlei criteria kunnen aangewend worden om te meten of ze dat ook voldoende goed doen: precisie en recall, de tijdspanne nodig voor de berekening, de reductie in manueel werk, ... Wat men ook hanteert als KPIs, goede meetbaarheid en opvolgbaarheid zorgen voor gemakkelijker monitoren of kwantificeren van de resultaten. Juist kiezen en meten is niet noodzakelijk gemakkelijk. Welke accuraatheid wordt verwacht van het AI-systeem, wat is “fout” en wat is “correct”? Bij die vergelijkingen mag men gerust de kanttekening toevoegen dat ook mensen fouten maken als zij dezelfde taak manueel zouden uitvoeren. Is er al eens gemeten hoe vaak dat gebeurt en wat de gevolgen daarvan zijn? Vanaf wanneer zou het AI-systeem ook effectief tot verbetering leiden in de praktijk?
3. Welke praktische beperkingen zijn er?
Elk bedrijf dat niet dezelfde cashpositie heeft als pakweg Amazon of Google, past best ook zijn verwachtingen inzake AI wat naar verhouding aan. Talent is schaars, zeker als ze naast kennis over AI of data science ook nog vertrouwd moeten zijn met projectmanagement en de praktische aspecten van softwareontwikkeling. Zelfs met wat geluk op HR-vlak, is technologische infrastructuur nog steeds niet gratis. De trial-en-error methodiek die de ontwikkeling van AI-systemen vaak kenmerkt, vergt een zekere financiële ademruimte - zeker bij toepassingen waarbij 1 iteratie van 1 trainingsproces al tot een aardige energiefactuur leidt. Daarnaast zijn er ook de ethische en legale beperkingen, bijvoorbeeld inzake gebruik van gevoelige gegevens. Veel van de software aan de basis van een AI-systeem zal van derde partijen afkomstig zijn, of gebruikmaken van open source componenten – met alle risico's vandien aangaande stabiliteit, onderhoudbaarheid en ondersteuning op langere termijn, licentiëring, ...
4. Zijn er genoeg middelen voor deployment, monitoring, onderhoud?
Een AI-systeem bouwen is 1 ding, het in productie zetten is nog iets anders. Er moeten heel wat waters doorzwommen worden voordat een stuk code ontwikkeld op enkele laptops uiteindelijk klaar is om 24/7 blootgesteld te worden aan de buitenwereld. De extra overhead gevormd door CD/CI, backups, testing, code review, etc. is onmisbaar voor de langere termijn maar kost allemaal tijd en geld. AI-projecten zijn anders dan klassieke softwareprojecten in die zin dat het niet afgelopen is eens de software is opgeleverd. Integendeel, bij oplevering begint het pas, en start een fase van actieve monitoring die schier eindeloos kan zijn: blijft de software wel doen wat ervan verwacht wordt in de buitenwereld? Zeker als nieuwe data wijzigt van karakter, zal je vaak actief moeten bijsturen.
5. Hoe transparant is dat allemaal?
De GDPR legt beperkingen op aan systemen die automatisch beslissingen nemen: er moet altijd de mogelijkheid zijn om de beslissing te laten (her)bekijken door een mens (art. 22). Niet alleen in de GDPR maar in het gehele AI-beleid dat de EU hoopt te voeren is transparantie een sleutelwoord, waarmee de EU hoopt zich te onderscheiden van andere grootmachten. Het kunnen uitleggen waarom een AI-systeem tot een bepaald resultaat komt is belangrijk voor die transparantie, maar is niet noodzakelijk evident wanneer de trainingsdata onoverzichtelijk groot is, misschien niet onder eigen beheer ligt, of wanneer het aantal parameters van het model onoverzichtelijk groot is. Je wil immers niet met je mond vol tanden staan als ooit een journalist of wakkere burger je voorschotelt: is er een ethische evaluatie en Data Privacy Impact Assessment gebeurd, en waar kan ik mijn data raadplegen en beslissen wat ermee gebeurt?
Praktisch
Veel analyses kunnen erg langdradig zijn, dagen in beslag nemen en leiden tot rapporten van 50 bladzijden die niemand achteraf nog leest. Ook is niet alles even relevant voor elke usecase: een AI die een keukenrobot aanstuurt heeft niet dezelfde KPIs of foutentoleraties als eentje die een pacemaker aanstuurt. Om het overzicht te bewaren kan het handig zijn om, voor de eigen usecases, de belangrijkste vragen uit verschillende analyses mee te nemen in een eigen assessment, waarvan de resultaten bijvoorbeeld in een grafiek zoals deze kunnen weergegeven worden:
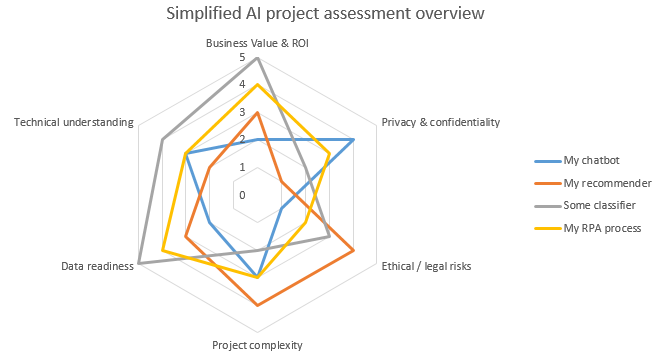
AI project assessment summarized in a radar chart
Dit is uiteraard maar een greep uit de bedenkingen die men kan maken bij de start van een nieuw AI-project. Zulke denkoefening, vooraleer geld en middelen in de uitvoering te steken, is de investering meestal wel dubbel en dik waard.
______________________
Dit is een ingezonden bijdrage van Joachim Ganseman, IT consultant bij Smals Research. Dit artikel werd geschreven in eigen naam en neemt geen standpunt in namens Smals.