De meilleurs résultats de recherche grâce aux bases de données vectorielles
Posted on
20/06/2024
by
Bert Vanhalst

Dans le monde de l’IA, les bases de données vectorielles sont devenues un outil important.
Elles nous permettent de stocker et de fouiller efficacement de grandes quantités de données non structurées, fonction essentielle pour de nombreuses applications.
Embeddings vectoriels
Les bases de données vectorielles gèrent essentiellement des données vectorielles, c’est-à-dire des données représentées sous la forme d’une série de nombres, ou vecteurs, représentant un point dans un espace à haute dimension. La quantité de nombres dans un vecteur correspond à la quantité de dimensions.
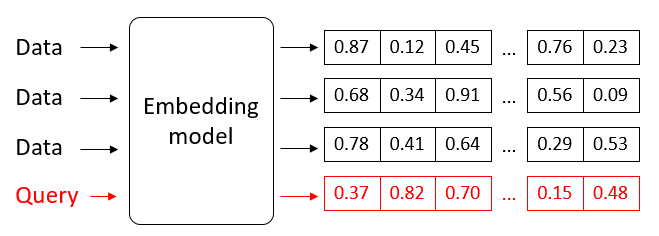
La conversion des données en vecteurs s’opère sur la base d’un modèle d’embedding, où est captée leur signification (sémantique). On parle d’embeddings vectoriels. Par exemple, le vecteur du mot “chiot” sera proche du vecteur du mot “chien”, et plus éloigné du vecteur du mot “pomme”.
Création d’embeddings vectoriels
Ces vecteurs sont sauvegardés sous forme indexée dans une base de données vectorielle, de manière à ce que la recherche s’effectue le plus efficacement possible.
Recherche de similarité
Les bases de données vectorielles se distinguent par le fait qu’elles peuvent rechercher des données similaires par rapport à une requête d’entrée (query). On parle de recherche de similarité : au lieu de rechercher des correspondances exactes, les bases de données vectorielles peuvent rechercher les données les plus similaires à une requête donnée.
Cette “similarité” est calculée sur la base de la distance entre les vecteurs dans l’espace de recherche : plus la distance entre deux vecteurs est faible, plus ils sont similaires. Plusieurs fonctions permettent de calculer la distance entre deux vecteurs. Le choix peut dépendre de plusieurs facteurs : les données, le modèle d’embedding utilisé et le compromis entre précision et vitesse d’exécution.
Fonctions de distance pour le calcul de la similarité entre vecteurs
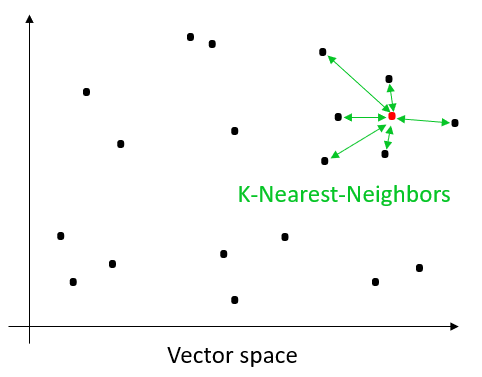
La méthode la plus évidente pour chercher les vecteurs les plus proches d’un vecteur de requête consiste à comparer exhaustivement le vecteur de requête à tous les vecteurs présents dans la base de données (k-Nearest-Neighbors ou kNN). Nous avons ainsi la certitude de trouver les k vecteurs les plus proches. Dans ce cas, nous obtenons une précision parfaite. L’inconvénient de cette méthode est qu’elle nécessite beaucoup de calculs et qu’elle n’est pas extensible.
k-Nearest-Neighbors
Pour effectuer des recherches plus performantes parmi de grandes quantités de données, il existe des méthodes approximatives où il n’y a pas de comparaison exhaustive entre la requête et les vecteurs de la base de données (Approximative Nearest Neighbors ou ANN). La méthode la plus utilisée est sans doute HNSW (Hierarchical Navigable Small World). Il s’agit d’une méthode basée sur un graphe hiérarchique où chaque nœud représente un vecteur et où les liens entre les nœuds indiquent la distance qui les sépare. Lors d’une recherche, l’algorithme navigue efficacement dans le graphe, en commençant par les niveaux supérieurs (où la densité des nœuds est moindre) et en descendant progressivement vers les niveaux inférieurs pour trouver les voisins les plus proches.
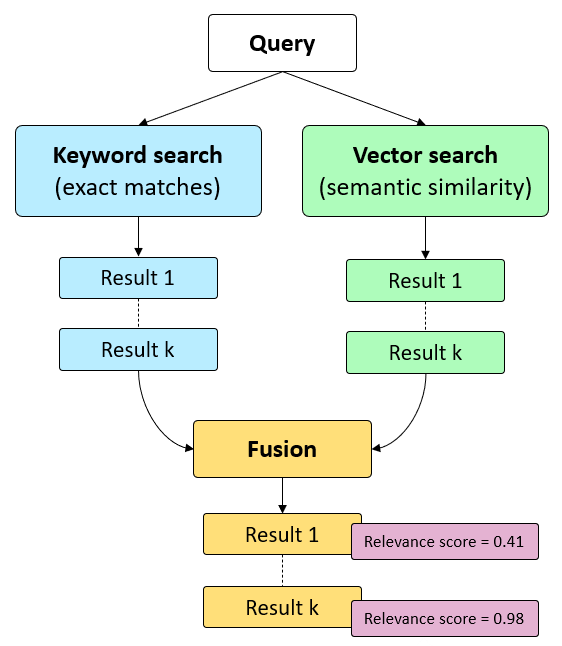
Recherche hybride
La recherche hybride est une technique de recherche avancée qui combine les atouts de la recherche vectorielle et ceux de la recherche classique par mot-clé. La recherche par mot-clé (recherche lexicale) utilise les correspondances exactes des mots-clés dans le texte. Elle est rapide et simple, mais manque parfois de nuances contextuelles. La recherche vectorielle (recherche sémantique) tient compte du sens. Dans la pratique, une combinaison des deux méthodes débouche sur de meilleurs résultats que chaque méthode individuelle.
Recherche hybride
Pour améliorer encore la pertinence des résultats de recherche, il est possible d’appliquer le classement sémantique, qui consiste à utiliser un modèle de machine learning avancé pour réorganiser les résultats de la recherche en fonction de leur pertinence par rapport à la requête. Il s’agit généralement d’une fonction payante ou d’une API facturée sur la base de son utilisation. À titre d’exemple d’un tel service, nous pouvons citer Cohere Rerank.
Domaines d’application
Les bases de données vectorielles peuvent être utilisées pour un grand nombre d’applications :
- Recherche sémantique – Il est clair à présent que les bases de données vectorielles peuvent grandement contribuer à l’amélioration des résultats d’une recherche sur la base de la signification sémantique plutôt que sur la seule base des correspondances exactes.
- Question answering & RAG– Depuis peu, les systèmes génératifs de questions-réponses font l’objet d’une grande attention. Dans un tel système, les bases de données vectorielles peuvent servir d’extracteur. On parle de Retrieval Augmented Generation (RAG). Dans cette approche, un modèle de langage formule des réponses basées sur les informations les plus pertinentes d’une base de connaissances.
- Recommandations – Les bases de données vectorielles peuvent également être utilisées pour recommander des informations ou des produits aux utilisateurs, en fonction ou non de leur historique ou de leurs préférences.
Recherche de similarité multimodale (Multimodal similarity search) – Certains modèles d’embedding sont capables de créer des vecteurs pour plusieurs types de données : non seulement du texte, mais aussi des images, de l’audio ou de la vidéo. Les bases de données vectorielles peuvent ainsi permettre la recherche de contenus similaires, qu’il s’agisse de textes, d’images, d’audio ou de vidéo.
Aperçu du marché
Les acteurs initiaux du marché des bases de données vectorielles comme Chroma, Milvus, Pinecone et Weaviate, proposaient essentiellement des solutions spécifiques.
Ce n’est que plus tard que les acteurs plus établis ont pris le train en marche. Ainsi, ElasticSearch et Postgresql (avec l’extension pgvector) prennent également en charge la recherche vectorielle. Bien évidemment, les grands acteurs sont également représentés dans le paysage : Microsoft propose Azure AI Search, Google Vector AI Vector Search et Amazon Kendra.
Presque toutes les solutions s’intègrent à des solutions d’orchestration LLM telles que LangChain et LlamaIndex. De plus en plus, les bases de données vectorielles fournissent également un support intégré pour RAG, où la création d’embeddings et l’invocation d’un modèle de langage n’ont plus besoin d’être orchestrées en dehors de la base de données vectorielle.
Il convient également de mentionner Neo4j, qui prend en charge la recherche vectorielle en plus de la recherche dans le graphe, ce qui le rend adapté aux cas de données structurées et non structurées.
Conclusion
Enfin, nous pouvons affirmer que les bases de données vectorielles peuvent fournir des résultats de recherche meilleurs et plus pertinents qu’une simple recherche par mot-clé.
Dans les applications génératives de réponse aux questions, les bases de données vectorielles peuvent aider un modèle de langage à formuler des réponses basées sur les informations les plus pertinentes d’une base de connaissances. S’il n’est pas évident de faire fonctionner de grands modèles de langage sur une infrastructure propriétaire, cela est bien possible avec une base de données vectorielle en guise de composant d’extraction, ce qui peut être un facteur favorable dans le contexte de la protection des données.
D’après notre propre expérience, la recherche hybride, à savoir une combinaison de recherche vectorielle et de recherche lexicale, peut être une solution rapide pour améliorer les résultats de la recherche. Le classement sémantique peut en outre renforcer la pertinence des résultats.
Ce post est une contribution individuelle de Bert Vanhalst, IT consultant chez Smals Research. Cet article est écrit en son nom propre et n’impacte en rien le point de vue de Smals.
Bron: Smals Research
