Eventual Consistency – Een nog te weinig ontgonnen Principe
Eventual Consistency is dé truc waarmee vele NOSql databases hun beschikbaarheid gevoelig kunnen verbeteren. Maar kunnen we dit principe ook doortrekken naar de rest van de architectuur, en misschien zelfs laten meespelen op business niveau? Of is het sop de kool niet waard, en moeten we kiezen voor de eenvoudig bruikbare garanties die Strong Consistency ons biedt?
In deze blog gaan we het concept Eventual Consistency (EC) verder uitdiepen. Wat betekent het precies? Wat zijn goede voorbeelden? En – uiteraard – wat hebben we er precies aan? Wanneer wordt dit principe nuttig?
Wat is Eventual Consistency?
Het principe / model van Eventual Consistency bestaat reeds lang, maar werd vooral bekend door het gebruik ervan in NOSql databases. Deze databases waren een broodnodige revolutie toen populaire webtoepassingen een zodanig grote schaal kregen dat traditionele databases ontoereikend bleken.
Het grote voordeel van deze databases is namelijk dat ze enorm schaalbaar zijn en, zelfs bij het voorkomen van netwerkfalen, blijven werken. Het is precies het EC model dat hiervoor zorgt. Maar wat doet dit principe nu juist?
Het Eventual Consistency model is van toepassing op gedistribueerde systemen; m.a.w. systemen met meerdere nodes, verbonden door een netwerk. Een systeem dat als consistentiemodel EC heeft, zal ervoor zorgen dat een update aan een gegeven na verloop van tijd op alle nodes zal geraken. Tot die tijd kan het zijn dat we op bepaalde nodes nog de vorige waarde van het gegeven uitlezen.
Dit is natuurlijk een erg zwakke garantie, maar ze laat toe dat de nodes afzonderlijk kunnen blijven werken, zelfs indien het netwerk ertussen faalt, of indien een aantal nodes een tijdlang uitgeschakeld worden. Wanneer alles terug in orde geraakt, zal het systeem ervoor zorgen dat alles overal terug up-to-date is.
Eventual Consistency wordt ook wel Optimistische Replicatie genoemd. Wanneer een EC systeem de nodige updates heeft verwerkt en terug consistent is, zeggen we dat het systeem is geconvergeerd. De tijd die verstrijkt tussen een update en het convergeren, noemen we de inconsistency window. Deze willen we natuurlijk liefst zo kort mogelijk houden. In de huidige state of the art zal dit in de meeste gevallen, indien er geen falende nodes of netwerkpartities zijn, slechts milliseconden tot seconden duren.
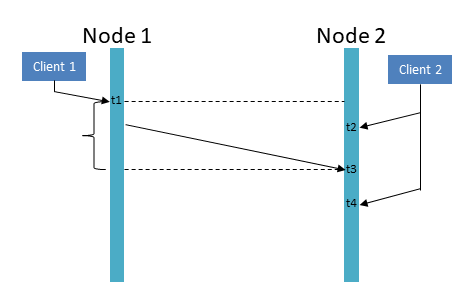
Figuur 1: Het principe van Eventual Consistency geïllustreerd. Nodes 1 en 2 vormen samen ons gedistribueerd systeem. Op tijd t1 doet client 1 een update. Enige tijd later, op tijd t2, vraagt client 2 hetzelfde gegeven op; dit zal echter nog de oude versie zijn, vermits de update van node 1 de andere node slechts op tijd t3 bereikt. Wanneer het gegeven nogmaals wordt opgevraagd, op tijd t4, is het up-to-date. De tijd tussen t1 en t3 noemen we de “inconsistency window”, aangegeven door de accolade.
Natuurlijk maakt het Eventual Consistency model het ook wel moeilijker om te redeneren en om te gaan met de data. Zo zijn er een aantal problemen waar developers een antwoord op zullen moeten hebben, indien ze EC willen gebruiken. Wat doe je bijvoorbeeld met clients die een node consulteren die nog niet de laatste nieuwe gegevens heeft? En – erger nog – wat als twee nodes een update binnenkrijgen voor hetzelfde gegeven, vóór ze elkaar op de hoogte hebben gebracht?
De meeste developers zijn gewend aan de luxe van “Strong Consistency” bij de systemen waarop ze verder bouwen. Deze tegenhanger van EC garandeert dat indien er een update is gebeurd, élke leesopdracht die daarna nog volgt deze update zal zien. Daarenboven is het in zo’n systeem niet mogelijk om conflicterende updates te doen aan éénzelfde gegeven.
Je kan natuurlijk al aanvoelen dat Strong Consistency zijn eigen problemen heeft: wanneer de schaal groter en groter wordt, kan het steeds vaker voorkomen dat clients moeten wachten, omdat het systeem bezig is ervoor te zorgen dat alle nodes consistent zijn. Het systeem wordt daardoor dus minder beschikbaar. Of nog: onvoldoende nodes kunnen met elkaar communiceren om consistentie te garanderen, en het volledige systeem wordt onbeschikbaar. Dit is natuurlijk precies de te maken keuze die wordt geïllustreerd door het CAP / PACELC theorema, waarover we reeds eerder hebben geblogd. Een gedistribueerd systeem moet altijd Partitietolerant zijn (P), dus daarna blijft nog de keuze over om te focussen op Consistentie (C) of Availability (A), maar alle drie samen gaat niet (zelfs de laatste evolutie in databases, de NewSql databases, maken hierin de keuze voor consistentie, al voorzien ze heel wat verbeteringen om toch nog zo beschikbaar mogelijk te zijn).
Voorbeelden
Buiten het typische voorbeeld van NOSql Databases die EC storage kunnen leveren aan applicaties, kunnen we ook een aantal voorbeelden geven waarbij de EC op een hoger niveau van abstractie zijn werk doet binnen een applicatie, en zelfs op business niveau zijn impact heeft.
1. Domain Name System (DNS)
DNS, een zeer bekend systeem in de informatica, koppelt internet domeinnamen aan IP-adressen. Het is een hiërarchisch systeem, doch grotendeels gedecentraliseerd. Noodzakelijkerwijs moet de data sterk verspreid en gerepliceerd worden, want het volledige internet maakt gebruik van dit systeem, en geen enkele individuele machine of zelfs cluster zou deze schaal aankunnen.
Wanneer er een update gebeurt binnen dit systeem, zal dit eerst op één server gebeuren. Deze server (de “authoritatieve server” voor een bepaald domein) heeft dan het correcte IP-adres dat bij een domeinnaam hoort, maar andere servers nog niet. Na verloop van tijd zal de informatie zich echter verspreiden doorheen het hele DNS systeem. Uiteindelijk zullen alle servers die de desbetreffende domeinnaam stockeren, hun cache laten verlopen, en de meest recente versie opvragen, en op deze manier is DNS dus eventually consistent.
Zonder verdere maatregelen, zullen clients die toevallig naar een bepaalde site willen surfen, terwijl de cache van hun DNS server nog naar oude data verwijst, niet naar het nieuwe IP adres kunnen gaan. Met een goed beheer van je DNS data kan je dit echter voorkomen (b.v. op het oude IP adres nog een tijdlang een redirect server plaatsen).
2. Webwinkel
Voor een webwinkel kan elke minuut dat mensen geen bestellingen kunnen doen, een groot verlies betekenen. Beschikbaarheid (van het winkelgedeelte op zijn minst) is dus cruciaal.
Om hiervoor te zorgen, kan er worden gebruik gemaakt van Eventual Consistency in verschillende gradaties. Men zou bijvoorbeeld kunnen stellen dat men veranderingen in het inventorysysteem (b.v. hoeveel van dit artikel is nog in stock?) slechts met enige vertraging laat doorsijpelen tot het frontend systeem, dat de clients bedient, die bezig zijn met winkelen. Je zou dus iets in je winkelkarretje kunnen leggen dat niet meer in stock is. Op het moment echter van de eigenlijke bestelling, zou men wel via een transactie kunnen werken, waarbij men effectief de huidige inventaris gaat nakijken alvorens de bestelling te laten doorgaan. Indien het artikel er niet meer is, krijgt de klant op dat moment een foutboodschap met verontschuldigingen en b.v. de optie om bericht te krijgen wanneer de stock is bijgevuld.
Op deze manier voorziet men reeds een loskoppeling tussen het winkelsysteem zelf, en de inventory backend, waardoor de eerste beschikbaar blijft, zelfs wanneer de laatste niet goed werkt.
Men kan hier de Eventual Consistency zelfs nog verder doortrekken: we laten de bestelling doorgaan zonder de inventory op te nemen in de transactie, en we brengen deze pas later (eventually) up-to-date. Zo kan een klant een item zelfs bestellen indien het niet meer in stock is. Uiteraard zal er echter wel iets moeten gebeuren in zo een geval. We kunnen dan op zoek gaan naar mitigerende processen op business niveau. Er kan bijvoorbeeld een email gestuurd worden met verontschuldigingen: “spijtig genoeg moeten we dit artikel nabestellen en zal het dus iets later zijn; u krijgt de verzendingskosten terug of mag de bestelling alsnog annuleren”. Of nog: “We kunnen dit helaas nu niet leveren; we annuleerden uw bestelling en u krijgt een waardebon”. Hier zijn tal van mogelijkheden, de ene al klantvriendelijker dan de andere, waaruit de business kan kiezen als strategie.
3. Het bancair systeem
Het lijkt misschien contra-intuïtief, maar een aantal aspecten van het bancair systeem, bijvoorbeeld bij het “settlen” van rekeningen, zijn via EC geregeld, en dit was noodzakelijkerwijs zelfs al zo voordat er sprake was van computers!
Wanneer in de IT een voorbeeld van de bankwereld wordt gebruikt, zal men typisch de atomaire transactie uitleggen die moet gebeuren bij een overschrijving: indien één rekening gedebiteerd wordt, moét de andere gecrediteerd worden, of vice versa. Dit is natuurlijk een voorbeeld van Strong Consistency.
Maar er zijn tal van manieren waarop de stand van een rekening niet overeenkomt met wat de waarde ervan zou moeten zijn, rekening houdend met alle transacties die al hebben plaatsgevonden of nog moeten plaatsvinden. Zo kan ik b.v. allerlei online zaken bestellen op zondag, terwijl ik zaterdag al ben gaan winkelen. De bancontact transactie van de winkel is nog niet doorgekomen, en het saldo op mijn rekening is dus een pak hoger, waardoor ik meer geld kan uitgeven dan ik heb. Op maandag wordt alles dan vereffend en komt mijn rekening onder nul. Gelukkig werd op vrijdag mijn loon gestort en komt dit óók maandag tot uiting op mijn rekening. Net op tijd om de cheque aan te kunnen die geïnd zal worden op dinsdag, maar die ik reeds een week geleden aan iemand heb gegeven voor een grote aankoop, met de vraag of die even wou wachten met het innen.
Er kunnen dus allerlei zaken gebeuren die het saldo van een rekening beïnvloeden en die soms zelfs het saldo van de rekening nakijken, zonder dat het saldo al met al deze zaken rekening houdt. De rekeningstand is dus “eventually consistent”: uiteindelijk komen alle transacties erop terecht, maar dit kan even duren.
De bankwereld heeft geen probleem met het bestaan van dit soort inconsistenties in hun systeem, die zelfs op business niveau zichtbaar zijn. Misbruik ervan wordt dan ook vrijwel geheel vermeden door allerlei provisies (eveneens op business niveau): b.v. wetten die fraude strafbaar maken.
4. Onze sector?
We kunnen niet direct voorbeelden geven van zaken die binnen onze sector via eventual consistency zijn geïmplementeerd, maar we kunnen wel eens verkennen waar er eventueel mogelijkheden bestaan om dit in de toekomst te gaan doen.
Als we de typische workflows binnen de overheid in beschouwing nemen, zien we dat er geregeld processen zijn waarbij iets wordt aangevraagd, of een dossier wordt ingediend, dat dan later wordt nagekeken en wordt verwerkt met menselijke tussenkomst. Dit is een heel goede indicator dat we misschien wel EC kunnen gebruiken, gezien er reeds een natuurlijke vorm van uitstel in het proces zit. Hetzelfde zien we bij die processen waarin gegevens verplicht moeten worden ingediend, maar niet noodzakelijkerwijs onmiddellijk worden behandeld door de desbetreffende overheidsdienst.
Kijken we anderzijds naar de gezondheidssector (eHealth). Hier is het uiteraard cruciaal dat de toegang tot patiëntendossiers een zo hoog mogelijke beschikbaarheid biedt. Maar is het absoluut noodzakelijk dat de informatie tot op de seconde up-to-date is? Persoonlijk zou ik denken van niet. Indien mijn huisarts mijn dossier een half uurtje geleden heeft geüpdated, is het allicht niet erg dat ze dit in het ziekenhuis nog niet kunnen zien. De volgende dag, als ik naar het ziekenhuis ga, wil ik dit uiteraard wel, maar tegen dan heeft men tijd genoeg gehad om alle nodes van het systeem voldoende met elkaar te laten communiceren.
En wat met apothekers die de verzekerbaarheid van iemand moeten nagaan? Het is cruciaal dat deze informatie beschikbaar is wanneer iemand een medicijn komt kopen. Maar de kans dat dit gegeven is veranderd gedurende het voorbije half uur is enorm klein; ook hier kan men dus overweg met gegevens die niet tot op de seconde up-to-date zijn. Voeg daarbij eventueel een mitigerende regel op business niveau toe, voor de minieme hoeveelheid uitzonderingen waarbij men toch een medicijn zonder korting zou verschaffen terwijl de klant hier wel recht op had (b.v. een terugbetaling achteraf, wanneer dit wordt vastgesteld dankzij de zich convergerende gegevens).
Evaluatie en Besluit
De voorbeelden maakten het reeds duidelijk: Eventual Consistency kan ervoor zorgen dat een systeem gewoon blijft doorwerken, zelfs wanneer er zaken mislopen. Op die manier kan de resiliëntie gevoelig worden verhoogd. Er moet in zo’n geval echter wel met een aantal inconsistenties in de data worden rekening gehouden, op IT vlak óf op business vlak, en dit maakt het complexer om over deze systemen te redeneren en om deze te bouwen. En uiteraard heeft een complex systeem ook een verhoogde kans op falen, net door de verhoogde kans op fouten die deze complexiteit met zich meebrengt.
We zullen dan ook een afweging moeten maken, samen met de business, om te zien waar de prioriteiten liggen. Hoe belangrijk is het dat dit systeem een beschikbaarheid heeft van vele negens (99,9% beschikbaarheid, “triple nine availability”, is b.v. nog haalbaar zonder EC voor een niet al te groot systeem)? Hoeveel data zal het systeem op termijn gaan bevatten / behandelen? In welke mate zal het moeten schalen voor gebruik door vele gelijktijdige clients?
We kunnen stellen dat Eventual Consistency enorm vruchten begint af te werpen, wanneer men met systemen te maken krijgt van een redelijk grote schaal. Voor dit soort systemen wordt het sowieso complex om ze draaiende te houden en zal de bijkomende complexiteit die EC met zich meebrengt, relatief een minder groot verschil maken. Het voordeel van de verhoogde resiliëntie zal in dat geval meer doorwegen. Sommige experts stellen zelfs dat sterke consistentie een sprookje wordt vanaf een bepaalde (erg grote) schaal, en dat men dus op een bepaald moment altijd naar eventual consistency zal moeten grijpen bij een sterk groeiend systeem.
Indien men echter met een klein systeem zit, b.v. bedoeld voor intern gebruik en met beperkte volumes aan data, dan zal het sop de kool meestal niet waard zijn en kan men, voor het gemak, best gebruik maken van Strong Consistency, wat het veel eenvoudiger maakt voor de ontwikkelaars van het systeem om het te bouwen en onderhouden.
Ten slotte kan men best bij elk project van enige omvang eens kritisch kijken naar de business processen die worden gedigitaliseerd. Vergen alle te implementeren functionaliteiten daadwerkelijk sterke consistentie doorheen het volledige proces? Moet alle data binnen de paar seconden gegarandeerd overal up-to-date zijn? Of zijn er misschien van nature stappen aanwezig waar menselijke tussenkomst is vereist, en men dus sowieso met wachttijden zit? Bestaan er eventueel op business niveau reeds mitigerende processen om om te gaan met een inconcistentie?
Vaak zal men dan zien dat sterke consistentie toch niet nodig is, en zeker niet overheen het volledige systeem, en ontstaan er dus mogelijkheden om de resiliëntie te verbeteren via Eventual Consistency.
_________________________
Dit is een ingezonden bijdrage van Koen Vanderkimpen, IT consultant bij Smals Research. Dit artikel werd geschreven in eigen naam en neemt geen standpunt in namens Smals.