Kruisen van persoonsgegevens met eHealths blinde pseudonimiseringsdienst
De nieuwe pseudonimiseringsdienst van eHealth biedt hoge veiligheidsgaranties en wordt momenteel ingezet om de privacy van de burger te beschermen onder meer bij de opslag en verwerking van elektronische voorschriften. Deze dienst leent zich daarnaast ook bijzonder goed voor het kruisen en pseudonimiseren van persoonsgegevens in het kader van onderzoeksprojecten. Dit artikel licht toe hoe dit conceptueel mogelijk zou zijn.
De blinde pseudonimiseringsdienst van eHealth
De blinde pseudonimiseringsdienst van eHealth werd reeds uitgebreid beschreven in een eerdere blogpost. We hernemen het scenario waarbij een huisarts (client) vraagt aan de voorschriften backend (owner) om een elektronisch voorschrift te registreren.
Figuur 1 toont de basisflow; de dokter (client) vraagt aan de pseudonimiseringsdienst om een identifier om te zetten in een pseudoniem. De dokter stuurt vervolgens het pseudoniem, samen met de voorschriftendata naar de voorschriften backend, die de voorschriftendata onder dit pseudoniem bewaart.
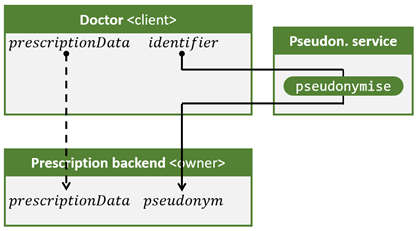
Figuur 1. Basisflow voor het scenario waarbij een arts (client) vraagt aan de voorschriften backend (owner) om een elektronisch voorschrift te registreren.
Om een hoog niveau van veiligheid te bereiken, zijn de volgende veiligheidseigenschappen cruciaal:
- De client is verziend; ze ziet enkel globale identifers (rijksregisternummers).
- De owner is bijziend; het ziet enkel de lokale identifiers (pseudoniemen).
- De pseudonimiseringsdienst is blind; het ziet noch identifiers, nog pseudoniemen.
Figuur 2 illustreert hoe dit gerealiseerd wordt door een aantal stappen aan de flow uit Figuur 1 toe te voegen.
- De veiligheidseigenschap blinde pseudonimiseringsdienst (3) wordt gerealiseerd m.b.v. de blind en unblind-operaties (paars). Het rijksregisternummer van de patient wordt geblindeerd, wat een kortstondige encryptie is met een sleutel die slechts eenmaal gebruikt wordt. De pseudonimiseringsdienst zet het geblindeerde rijksregisternummer om in een geblindeerd pseudoniem en ziet daarbij noch het originele rijksregisternummer, noch het resulterende pseudoniem (vergeet even de blauwe en oranje operaties; die bespreken we dadelijk). Enkel de client kan de blindering ongedaan maken m.b.v. de unblind-operatie.
- In de basisflow in Figuur 1 komt de owner geen rijksregisternummers te weten, waardoor de veiligheidseigenschap bijziende owner (2) sowieso reeds gerealiseerd is.
- Dankzij de encrypt- end decrypt-operaties (oranje) wordt, ten slotte, de veiligheidseigenschap verziende client (1) gerealiseerd; de pseudonimiseringsdienst encrypteert het geblindeerde pseudoniem, zodat enkel de owner kan decrypteren.
Ten slotte wordt ongeoorloofd hergebruik van de geëncrypteerde pseudoniemen – die de client bekomt na de unblind-operatie – vermeden doordat de pseudonimiseringsdienst met de add context-operatie (blauw) context-informatie aan het vercijferde pseudoniem toevoegt, zoals het moment van creatie. De owner zal deze informatie controleren m.b.v. de verify context-operatie (blauw) en aanvaardt enkel binnenkomende vercijferde pseudoniemen die recent gecreëerd zijn.
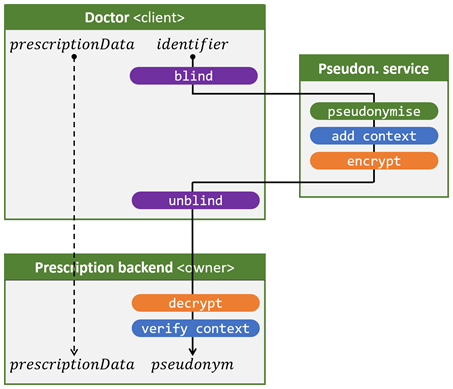
Figuur 2. High-security flow voor het scenario waarbij een arts (client) vraagt aan de voorschriften backend (owner) om een elektronisch voorschrift te registreren.
De convert-operatie
In voorgaande sectie paste de pseudonimiseringsdienst specifiek de pseudonymise-operatie toe om rijksregisternummers om te zetten in pseudoniemen. In bepaalde scenario’s is ook de inverse operatie vereist, met name de identify-operatie, waarbij een pseudoniem gekend door de owner terug omgezet wordt in het oorspronkelijke rijksregisternummer aan de kant van een client.
Systemen (owners) communiceren ook onderling met elkaar. Een dienst op het eHealth platform zou bijvoorbeeld kunnen vragen aan de TherLink service of een patiënt een therapeutische relatie heeft met een bepaalde arts. Indien TherLink ook met pseudoniemen werkt, zal een pseudoniem van de ene dienst/owner omgezet moeten worden naar het pseudoniem van de andere dienst/owner. Dit gebeurt met behulp van de convert-operatie. Om het identificatierisico zo klein mogelijk te houden is het immers aangewezen om dezelfde pseudoniemen niet over meerdere diensten te hergebruiken.
De drie operaties die de pseudonimiseringsdienst moet ondersteunen zijn dus pseudonymise, identify en convert. We zullen zien dat zowel de pseudonymise– als de convert– operaties nuttig zijn bij het kruisen en pseudonimiseren van persoonsgegevens. De identify laat ons dan weer toe om gecontroleerd burgers te identificeren. Dit kan in bepaalde situaties wenselijk zijn, bijvoorbeeld wanneer onderzoekers merken dat bepaalde burgers een wel erg hoog risico lopen op bepaalde aandoeningen, of misschien onbewust reeds hebben.
Kruisen van persoonsgegevens – de huidige aanpak
Voor onderzoeksdoeleinden worden geregeld persoonsgegevens afkomstig van verschillende bronnen gekruist en gepseudonimiseerd. Dat laatste is een noodzakelijke maatregel die helpt te verhinderen dat de onderzoeker persoonsgegevens kan koppelen aan natuurlijke personen.
Als concreet voorbeeld nemen we beraadslaging 13/093 van 22 oktober 2013, dat Sciensano toegang geeft tot medische data afkomstig van verschillende ziekenhuizen, met als doel inzichten te verkrijgen in de epidemiologie van patiënten met diabetes. Sciensano komt daarbij geen rijksregisternummers te weten, maar enkel pseudoniemen.
Figuur 3 toont – enigszins geabstraheerd – hoe dit tot op vandaag verloopt m.b.v. eHealth Batch Codage, een pseudonimiseringsdienst die al wat langer bestaat dan onze blinde pseudonimiseringsdienst. dataAid is de data m.b.t. de burger met rijksregisternummer id die aangeleverd wordt door ziekenhuis A.
De ziekenhuizen sturen voor elke betrokken burger de gevraagde data rechtstreeks naar Sciensano en het rijksregisternummer naar eHealth Batch Codage. Die laatste zet het rijksregisternummer om naar een projectspecifiek pseudoniem pseudonymlinkid en stuurt dit pseudoniem naar Sciensano. Sciensano ontvangt dus data afkomstig van een ziekenhuis via het ene kanaal en pseudoniemen afkomstig van de Batch Codage via een ander kanaal. Dankzij een tijdelijk transit-pseudoniem (vb. nymAid), dat verborgen blijft voor Batch Codage, is Sciensano in staat om de data aan de projectspecifieke pseudoniemen te koppelen. Via die projectspecifieke pseudoniemen, ten slotte, is Sciensano in staat om data over dezelfde burger maar afkomstig van verschillende bronnen aan elkaar te koppelen.
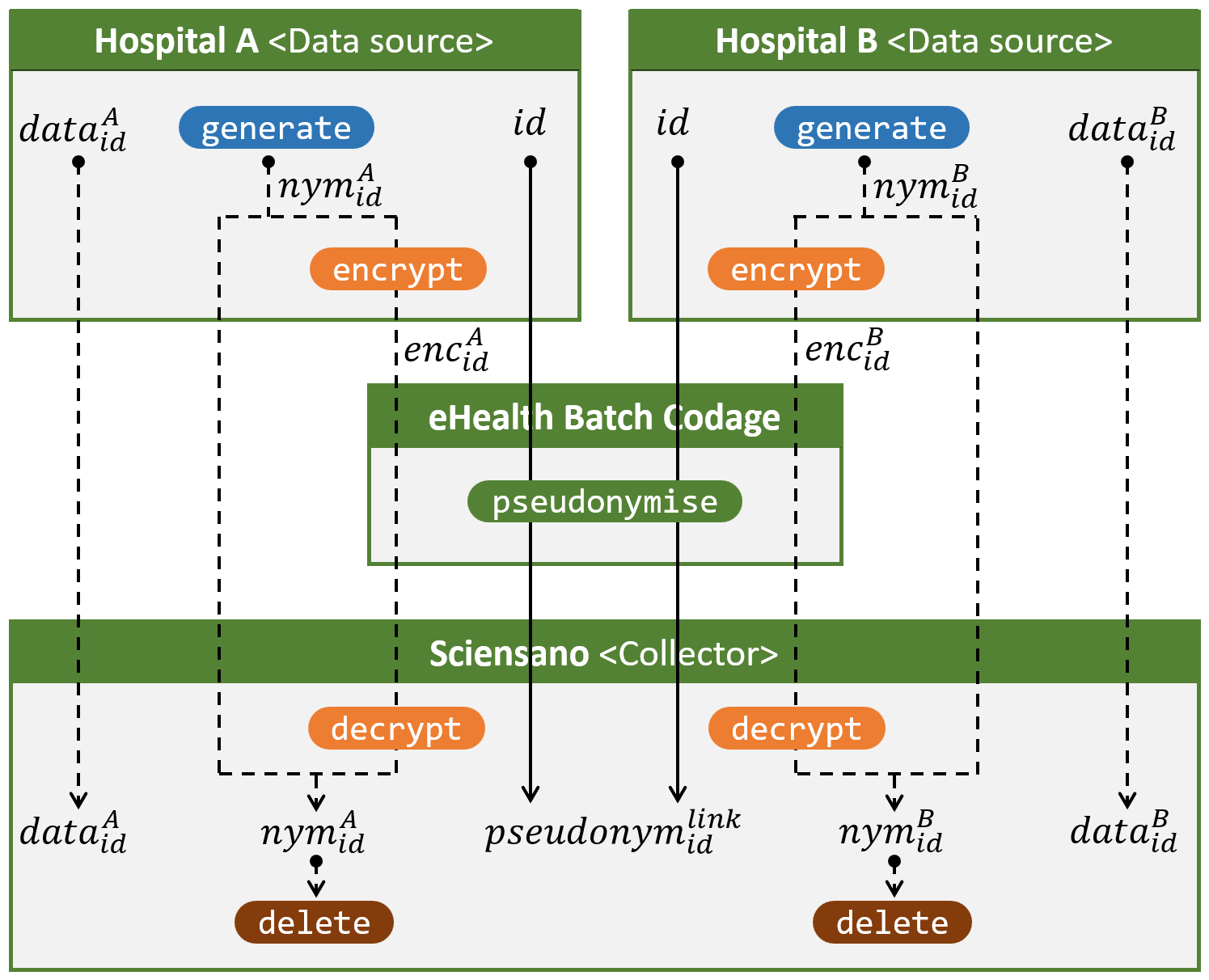
Figuur 3. Kruisen en pseudonimiseren van persoonsgegevens afkomstig van meerdere ziekenhuizen, bestemd voor Sciensano, zoals beschreven in beraadslaging 13/093.
Deze aanpak heeft een aantal minpunten:
- Batch Codage moet vertrouwd worden. Het is een Trusted Third Party (TTP); het ziet zowel de binnenkomende rijksregisternummers als de buitengaande pseudoniemen. Het weet aan welk kruisingsproject het meewerkt en kan dus in theorie profielen per burger aanleggen; bijvoorbeeld weet het na twee projecten welke burgers zowel betrokken waren in zowel het onderzoek rond diabetes als het onderzoek rond Multiple Sclerose. Dergelijke profielen kunnen op termijn vrij veel gevoelige informatie bevatten.
- Twee communicatiekanalen. Sciensano moet in staat zijn om de data die het rechtstreeks ontvangt van de ziekehuizen te koppelen aan de pseudoniemen die het ontvangt van Batch Codage. Er is weliswaar een oplossing, maar het zou eleganter zijn indien alle informatie rechtstreeks van het ziekenhuis naar Sciensano gestuurd werd via één enkel kanaal.
- Slechte integratie bij gepseudonimiseerde input. Dit systeem kan niet op een elegante manier overweg met situaties waarbij één of meerdere databronnen reeds gebruik maken van de eerder beschreven blinde pseudonimiseringsdienst en dus zelf geen rijksregisternummers kennen.
Kruisen van persoonsgegevens met de blinde pseudonimiseringsdienst
De drie nadelen beschreven in de vorige sectie zouden verholpen kunnen worden door voortaan beroep te doen op de blinde pseudonimiseringsdienst.
Het scenario waarbij alle databronnen de persoonsgegevens bewaren onder het rijksregisternummer wordt geïllustreerd in Figuur 4. De flow van een ziekenhuis (databron) naar Sciensano (collector) is exact dezelfde flow als die in Figuur 1, waarbij de drie eerder geformuleerde veiligheidseigenschappen uiteraard behouden blijven:
- De databronnen (vb. ziekenhuizen) zijn verziend en zien dus enkel rijksregisternummers
- De collector (vb. Sciensano) is bijziend en ziet dus enkel project-specifieke pseudoniemen
- De peudonimiseringsdienst is blind en ziet dus geen van beiden.
Indien meerdere databronnen data aanleveren over eenzelfde burger, geven ze hetzelfde rijksregisternummer als input aan de pseudonimisatieflow (volle lijn), wat resulteert in eenzelfde projectspecifieke pseudoniem aan de kant van de collector. Dat laat de collector dan weer toe om data over eenzelfde burger, afkomstig van verschillende databronnen, aan elkaar te koppelen.
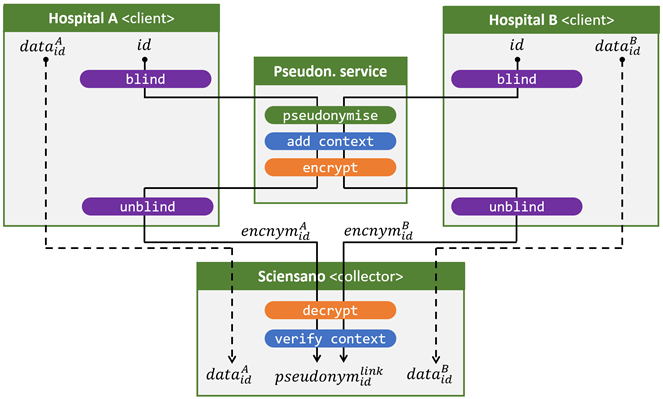
Figuur 4. Kruisen en pseudonimiseren van data afkomstig van verschillende databronnen, die allen persoonsgegevens bewaren onder rijksregisternummers
Figuur 5, ten slotte, illustreert een gemengd scenario, waarbij minstens één databron persoonsgegevens onder rijksregisternummers bewaart en minstens één databron persoonsgegevens bewaart onder pseudoniemen die m.b.v. de blinde pseudonimiseringsdienst bekomen werden. Die laatste databron zou bijvoorbeeld de prescription backend uit Figuur 1 kunnen zijn.
We krijgen dus twee varianten op de pseudonimiseringsflow (volle lijn):
- De pseudonimiseringsdienst ontvangt een geblindeerd pseudoniem van databron A en voert er een convert-operatie op uit (zie sectie “De convert-operatie“) wat resulteert in een geblindeerd projectspecifiek pseudoniem.
- De pseudonimiseringsdienst ontvang een geblindeerd rijksregisternummer van databron B en voert er een pseudonymise-operatie op uit wat eveneens resulteert in een geblindeerd projectspecifiek pseudoniem.
Indien het pseudoniem dat databron A als input gaf overeenkomt met het rijksregisternummer dat databron B als input gaf, zal dat resulteren in eenzelfde projectspecifiek pseudoniem bij Sciensano.
Voor de rest zijn beide flows identiek. Noch voor de databronnen (vb. publieke instellingen) noch voor de collector (vb. Sciensano) verandert er iets. De collector hoeft niet eens op de hoogte te zijn of een databron al dan niet met pseudoniemen werkt.
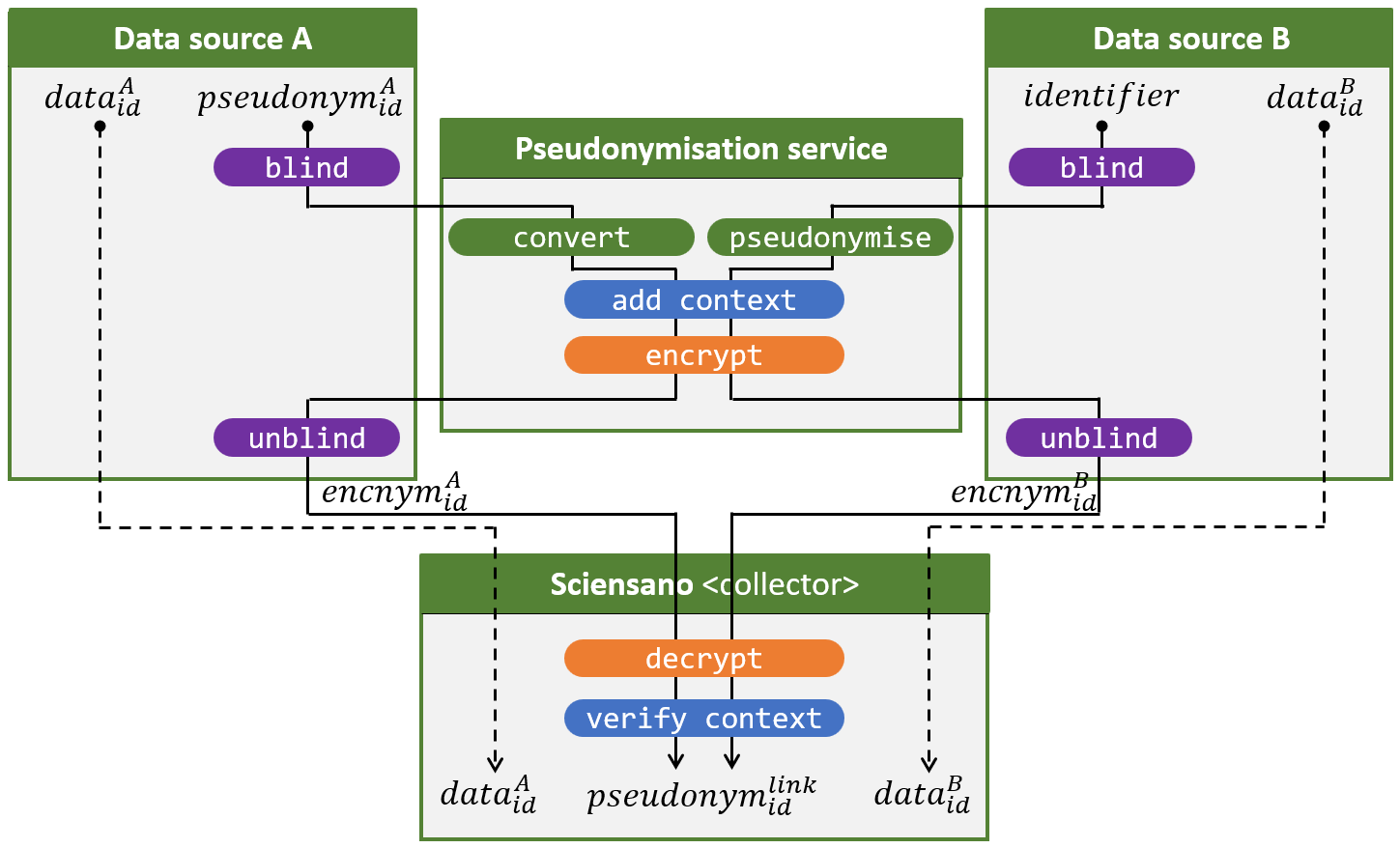
Figuur 5. Kruisen en pseudonimiseren van data afkomstig van twee databronnen, waarbij de ene databron persoonsgegevens bewaart onder rijksregisternummers en de andere onder pseudoniemen.
De eerder geformuleerde minpunten bij de huidige aanpak zijn bij deze van de baan:
- De pseudonimiseringsdienst ziet identifiers noch pseudoniemen en kan dus geen profielen meer aanleggen. Meerdere malen een blind-operatie uitvoeren op eenzelfde rijksregisternummer (of pseudoniem) resulteert bovendien telkens in een andere blindering. De pseudonimiseringsdienst kan dus evenmin geblindeerde identifiers of pseudoniemen gebruiken om profielinformatie aan te koppelen.
- De collector (vb. Sciensano) ontvangt alle informatie afkomstig van eenzelfde databron (vb. ziekenhuis) via één rechtstreeks kanaal.
- We kunnen op een bijzonder elegante manier overweg met situaties waarbij een of meerdere databronnen reeds gebruik maken van de blinde pseudonimiseringsdienst.
Conclusie
Dankzij de blinde pseudonimiseringsdienst van eHealth, kunnen we op een elegante en erg veilige wijze data afkomstig van verschillende databronnen kruisen en pseudonimiseren voor onderzoeksdoeleinden.
Een bijkomend voordeel is bovendien dat er geen bijkomende infrastructuur vereist is; overdag worden veel meer voorschriften uitgegeven en verwerkt dan ’s nachts. ’s Nachts is er bijgevolg heel wat pseudonimisatiecapaciteit op overschot. Dat is dan ook het ideale moment om dergelijke kruisingsprojecten, die niet tijdskritisch zijn, uit te voeren. Uiteraard krijgen tijdskritische opdrachten steeds voorrang.
Voor elk kruisingsproject zou de pseudonimiseringsdienst een andere sleutel gebruiken, wat resulteert in pseudoniem-onlinkbaarheid bij de collector; deze is dan niet in staat om gegevens over eenzelfde burger, maar uit verschillende projecten, aan elkaar te linken op basis van pseudoniemen.
Mocht dit nodig zijn is met de identify-operatie heridentificatie mogelijk, maar enkel mits autorisatie en medewerking van de pseudonimiseringsdienst, wat willekeur en misbruik tegengaat. Dergelijke aanvragen dienen bovendien gelogd te worden. De pseudonimiseringsdienst kan ook – mocht dit vereist zijn – de pseudonimiseringssleutel op een afgesproken moment verwijderen, waardoor heridentificatie langs deze weg onmogelijk wordt.
Uiteraard moet de blind– en unblind-operatie voorzien worden in de software die de databronnen gebruiken, terwijl aan de kant van de collector de decrypt– en verify context-operaties voorzien moeten worden. De ervaring leert ons dat deze integratie vrij vlot verloopt.
Bemerk wel dat deze aanpak enkel nuttig is indien alle databronnen autonoom kunnen bepalen welke records relevant zijn en welke niet. Dit is niet steeds het geval, zoals bijvoorbeeld in het datakruisingsproject dat goedgekeurd werd met beraadslaging 20/002 van 14 januari 2020, waarbij het Belgisch Kankerregister enkel data mag aanleveren over burgers met Multiple Sclerose (MS), maar zelf niet te weten mag komen wie MS heeft. Ook daarvoor heeft Smals Research een efficiënte en flexibele oplossing bedacht. Die oplossing is bovendien gedistribueerd, waardoor niet langer een pseudonimiseringsdienst nodig is om veilig te pseudonimiseren. Dit valt echter buiten de scope van dit artikel.
Aarzel niet ons te contacteren bij interesse in onze oplossingen voor het pseudonimiseren en kruisen van persoonsgegevens.
Dit is een ingezonden bijdrage van Kristof Verslype, cryptograaf bij Smals Research. Het werd geschreven in eigen naam en neemt geen standpunt in namens Smals.
Image source: Pixabay