Avec la popularité des applications d’IA dotées d’une interface conversationnelle, un “vieux casse-tête” refait surface : comment protéger les données personnelles communiquées, souvent sans méfiance, à un système automatisé de conversation ? Par extension, cette question se pose pour toute application où des données personnelles doivent être partagées avec des tiers. Les dépendances externes d’une application peuvent toutefois constituer un enchevêtrement complexe. Il n’est pas non plus toujours possible (ou économiquement viable) d’éviter les grands acteurs d’infrastructures informatiques d’IA – du moins pas si vous souhaitez rester à jour avec les dernières capacités de manière rentable.
Une solution possible est connue sous le nom de PII Filtering. En l’occurrence, PII est l’acronyme anglais de Personal(ly) Identifiable/Identifying Information, c’est-à-dire les informations par lesquelles une personne peut être identifiée. L’idée est assez simple : un filtre supplémentaire est placé devant l’application, qui élimine les informations à caractère personnel des données d’entrée, avant que celles-ci ne soient transmises à l’application. Si cela fonctionne bien, alors ce que l’application fait de ces données en coulisses n’a pas d’importance.
PII vs. Personal Data
Avant toute chose, il est crucial de comprendre que les PII ne peuvent être assimilées à des “Personal Data” telles que définies par le RGPD et d’autres législations européennes. Les PII sont un concept ancré dans le droit états-unien. Elles font généralement référence à un ensemble fini d’informations d’identification qui peuvent être utilisées dans le but de distinguer ou de confirmer l’identité d’un individu, comme les numéros de registre national, les adresses et les numéros de téléphone. Aux États-Unis, les réglementations sont souvent prescriptives à cet égard : par exemple, HIPAA (réglementation sur la protection des données relatives à la santé) comprend une liste de 18 identifiants définis comme PII. Cela présente le grand avantage d’être relativement facile à implémenter : une fois que la liste est entièrement cochée, il n’y a plus guère de débat juridique possible.
En revanche, la RGPD européenne adopte une approche de principe : elle définit un concept plus large de Personal Data (données à caractère personnel). Ce concept englobe “toute information se rapportant à une personne physique identifiée ou identifiable”. Cela signifie que même des informations en apparence anodines, comme la couleur “rouge”, peuvent être considérées comme des données à caractère personnel si elles se rapportent, par exemple, à la couleur préférée d’une personne. Cette définition des données à caractère personnel dépendante du contexte rend toutefois pratiquement impossible le développement de détecteurs ou de filtres génériques et polyvalents pour ces données. Ce qui est considéré comme des données personnelles ou non doit être évalué au cas par cas. Les développeurs sont donc confrontés à une personnalisation plus importante qu’ils ne le souhaiteraient, mais les juristes, les DPO et les autorités de protection des données ont également fort à faire avec de telles évaluations dans chaque pays de l’UE.
Ainsi, les solutions de filtrage des PII considérées comme conformes aux États-Unis risquent toujours de ne l’être que partiellement dans l’Union européenne. Étant donné que le terme PII semble s’être imposé sur le marché mondial, nous ferons dans le présent article uniquement référence aux PII. Gardez toujours à l’esprit que le Personal Data doit être le point de départ dans le contexte de l’UE.
Détection et filtrage des PII
Afin de filtrer des informations textuelles, nous utilisons généralement des modèles techniques de reconnaissance de formes et de traitement automatique des langues (Natural Language Processing ou NLP). Ces modèles analysent les données non structurées, à la recherche de formes telles que des formats d’adresses e-mail ou des chaînes numériques similaires à un registre national ou encore à des numéros de téléphone, afin de les modifier ou de les anonymiser par la suite. En outre, des formes d’expression régulières (regex) personnalisées sont souvent ajoutées afin de reconnaître les formes d’informations sensibles spécifiques à l’application en question.
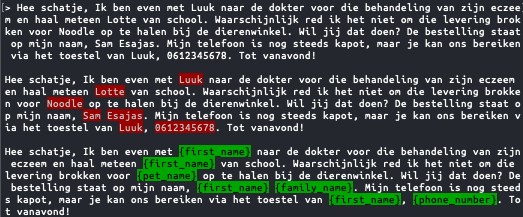
Filtrage PII basé sur NER en néerlandais. Source: pii-filter library (c) “HabaneroCake”, MIT license
Un filtrage efficace des PII repose en grande partie sur la reconnaissance d’entités nommées (Named Entity Recognition ou NER), une méthode NLP qui identifie les entités telles que les noms, les dates et les lieux dans un texte. Nous avons déjà publié des articles plus détaillés à ce sujet – voir les articles sur NLP et NER. L’essor de l’IA générative n’a pas encore changé grand-chose à la conception des techniques de NER. Aujourd’hui encore, de nombreux outils de filtrage de PII utilisent des outils NLP sous-jacents bien développés tels que NLTK, SpaCy ou Flair.
Toutefois, les PII peuvent également apparaître dans des images : scans de documents, photos de visages ou de plaques d’immatriculation, … Le filtrage de ces images nécessite une approche plus sophistiquée, car les données sensibles peuvent apparaître sous diverses formes, de notes écrites à la main à des reflets sur des photos. La reconnaissance optique de caractères (Optical Character Recognition ou OCR) permet d’extraire le texte des images et de le convertir dans un format qui peut être analysé de la même manière que des données textuelles. Une fois le texte extrait, il est soumis au même processus de filtrage des PII à l’aide de techniques NLP. Des algorithmes de reconnaissance d’objets sont utilisés pour reconnaître les éléments visuels sensibles (tels que des visages ou des documents personnels) contenus dans l’image elle-même.
Une fois identifiées, vous devez décider de ce qu’il convient de faire avec les PII détectées. Les options possibles sont les suivantes :
Remplacement/substitution par une autre valeur. Celle-ci peut éventuellement être créée à l’aide d’un outil de génération de données synthétiques, de sorte que l’original est remplacé par une alternative d’apparence réaliste.
Masquage / obfuscation : remplacement par un caractère ou une barre. Cela peut être partiel, afin de ne pas perdre des informations plus générales utiles : par exemple, nous pouvons toujours voir que +32********* est un numéro de téléphone belge.
Suppression
Hashage (mieux encore avec salage en prévention des attaques par force brute)
Texte en néerlandais (à gauche) anonymisé par masquage (au centre) ou par substitution (à droite) à l’aide de l’outil UE NLP Service. Notons que le texte anonymisé contient toujours des éléments de carrière uniques à partir desquels il est possible de déduire l’identité cachée. Texte source : Ville de Courtrai, communiqué de presse 23/07/2023
D’autres fonctions sont possibles pour les images, notamment :
Flouter (blurring) ou d’autres filtres. Il convient de noter ici que certains filtres sont réversibles.
Couvrir ou écraser, par exemple avec un rectangle noir.
…
Le remplacement par une valeur alternative du même type peut toutefois créer des effets étranges, parce que l’entité n’est pas toujours estimée correctement ou parce que trop peu ou pas de contexte peut être pris en compte. Certains outils peuvent ainsi ne pas tenir compte du genre si un nom aléatoire doit être choisi pour remplacer un nom réel, alors qu’il peut être nécessaire de rester cohérent sur le plan grammatical ou sur celui du contenu. Il arrive également que des noms de lieux comme Saint-Nicolas soient anonymisés en Saint-Kevin, par exemple, parce que Nicolas est considéré comme un prénom. Les modèles de langage utilisés pour la NER ne sont donc certainement pas sans faille.
En théorie, il devrait être possible d’obtenir de meilleurs résultats en activant des LLM modernes comme le GPT-4 avec des requêtes construites de manière intelligente. Des mesures dans ce sens verront probablement le jour sous peu, mais aujourd’hui, les besoins en puissance de calcul, la consommation d’énergie et le coût sont encore trop élevés, et le temps de réponse trop lent, pour que l’on puisse également faire évoluer cette méthode.
Le même texte en néerlandais (à gauche) anonymisé par ChatGPT 4o (à droite). La requête demandait de “remplacer toutes les PII et les données personnelles, y compris les professions, les employeurs, les villes, les dates et les âges”. Notez que le texte résultant a également été réécrit. Pour y remédier, il faudrait développer et affiner la requête.
Outils courants
Les personnes qui recherchent des systèmes de filtrage de PII à grande échelle, et qui souhaitent pouvoir analyser des bases de données, des réseaux ou des systèmes de fichiers entiers, se retrouvent avec des outils du domaine de Data Loss Prevention. Ceux-ci devraient empêcher les PII de quitter l’entreprise sans les autorisations nécessaires. Vous trouverez une vue d’ensemble du marché en consultant Gartner. Les géants de l’internet proposent également des solutions à cette fin, telles que Amazon Macie, Google SDP, ou IBM Guardium. Les techniques utilisées dans ces outils sont quelque peu liées à celles utilisées dans les enquêtes judiciaires – ce que l’on appelle l’eDiscovery, que nous avons déjà évoquée.
Les créateurs d’applications sont plus susceptibles d’être intéressés par des outils sous forme de bibliothèques, de SDK ou d’API. Les projets intéressants sont les suivants :
Les EU Language Services pour NLP (login requis) : pour l’anonymisation des documents dans les langues de l’UE, basé sur le projet MAPA-EU, qui peut également être utilisé via Docker Compose.
PIICatcher (pour les bases de données et les systèmes de fichiers)
De nouvelles recherches sont également en cours dans les universités. Par exemple, PII-Codex est le résultat d’un projet universitaire qui présente une caractéristique intéressante : il utilise Presidio ou Comprehend, mais ajoute également son propre score de risque, qui devrait être en mesure d’indiquer dans quelle mesure la non modification des PII reconnues pourrait poser un risque (pour la protection de la vie privée). En outre, la plupart des outils permettent d’utiliser vos propres modèles ou ceux des autres. Vous pouvez éventuellement les peaufiner vous-même pour la détection personnalisée d’entités, si vous disposez des données d’entraînement nécessaires à cet effet.
Si nous nous appuyons sur la NER ou la reconnaissance d’images pour la détection des PII, il est certain que certaines PII ne seront pas détectées et qu’à l’inverse, des éléments non PII pourraient également être classés à tort comme des PII. En effet, aucune de ces technologies ne garantit une précision de 100 %. Le taux de réussite variera également en fonction de la langue et du type d’entité que l’on tente de détecter. Il n’est jamais possible de garantir complètement le remplacement ou la suppression de chaque entité dans un document. Il est donc préférable de vérifier le résultat dans les cas où cela s’avère crucial.
Conclusion
Les solutions de filtrage de PII peuvent certainement contribuer à la protection de données à caractère personnel dans un contexte européen. Les techniques sont simples à comprendre et faciles à mettre en œuvre. Cependant, il n’y a jamais de garantie de détection totalement précise de toutes les données à caractère personnel et, dans la plupart des cas, leur utilisation devra donc faire partie d’un éventail plus large de mesures visant à promouvoir la conformité avec la RGPD et d’autres législations.
La technologie sous-jacente est “classique”, en ce sens que la NER et la reconnaissance d’images existent depuis longtemps et sont désormais bien développées. Aujourd’hui, elles bénéficient de l’attention portée à l’intelligence artificielle, et toutes sortes d’étalons leur permettent de rester à la pointe du progrès. Dans la pratique, nous constatons que le texte anonymisé qui en résulte peut parfois sembler un peu aliénant, car certains problèmes tout aussi classiques auxquels la NER est généralement confrontée ne sont pas encore totalement écartés.
______________________
Cette contribution a été soumise par Joachim Ganseman, consultant IT chez Smals Research. Elle a été rédigée en son nom propre et ne prend pas position au nom de Smals.