Qualité d’un système génératif de questions-réponses
Posted on
21/02/2024
by
Bert Vanhalst
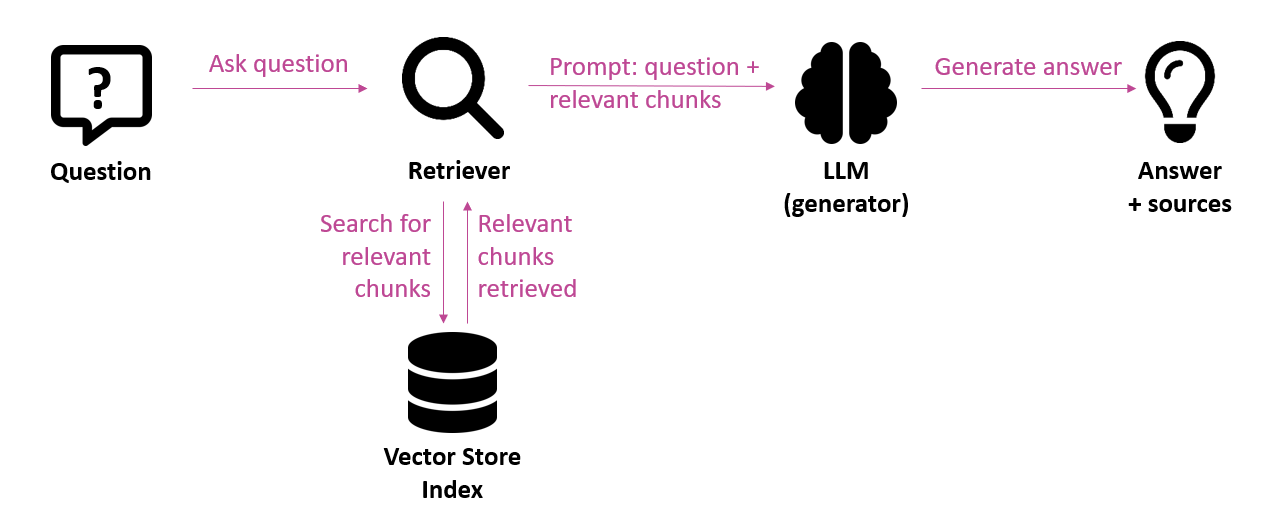
Retrieval Augmented Generation (RAG)
Dans le contexte de l’IA générative, les applications “chat with your data” qui permettent de poser des questions sur des informations propriétaires suscitent un vif intérêt. Les grands modèles de langage (LLM – Large Language Models) tels que GPT-4 sont capables de générer des textes linguistiquement corrects. Par défaut, ils opèrent sur la base des données sur lesquelles ils sont entraînés. Ces connaissances sont toutefois limitées dans le temps. En effet, le modèle de langage n’a pas connaissance d’événements et informations plus récents. On parle de knowledge cut-off à une certaine date. De même, un modèle de langage n’a pas accès à des informations propriétaires. Pour obtenir des réponses concernant des données plus récentes ou des données propriétaires, celles-ci doivent être transmises au modèle de langage d’une manière ou d’une autre. C’est là qu’intervient l’architecture Retrieval Augmented Generation (RAG). Il s’agit d’une approche dans laquelle le prompt, c’est-à-dire l’entrée communiquée au modèle de langage, est enrichi des éléments de texte les plus pertinents en provenance d’une source d’information. De cette manière, le modèle de langage est bel et bien en mesure de formuler des réponses sur la base de sources d’information propres.
Illustration 1 : Phase d’exécution d’un pipeline RAG
Si une version de base d’une telle application générative de questions-réponses peut être mise sur pied rapidement, le véritable défi consiste à livrer des réponses de qualité.
Nous présenterons ci-dessous diverses techniques qui peuvent aider à améliorer la qualité. Cette liste n’est pas exhaustive, mais offre un aperçu succinct des améliorations possibles.
Phase d’ingestion
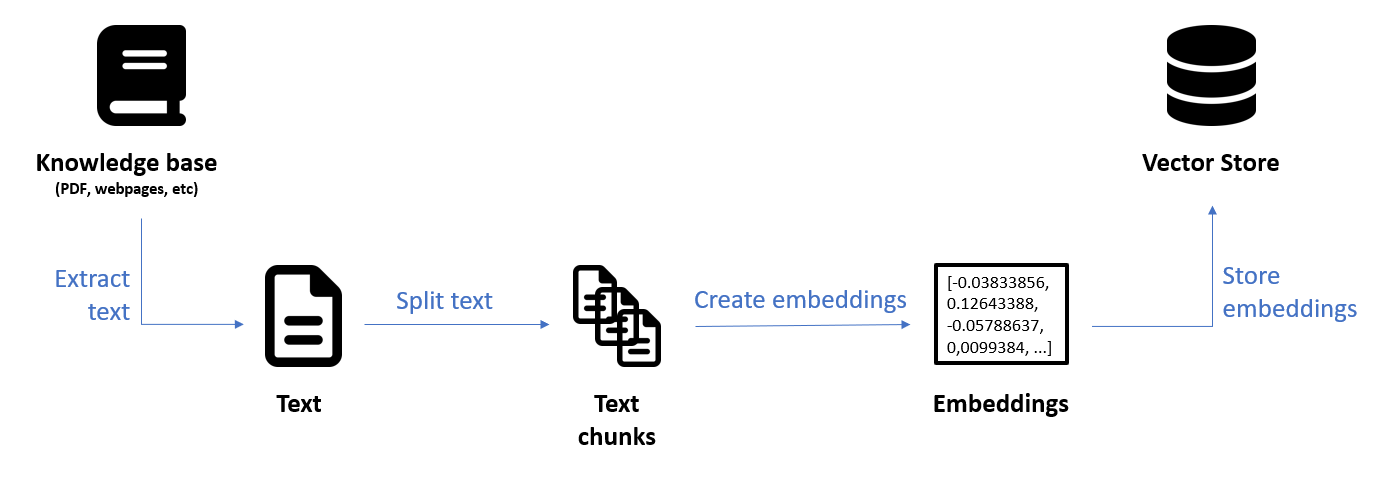
La phase dite Ingestion est la phase préparatoire au cours de laquelle les sources de données originales (base de connaissances) sont converties et stockées dans une base de données vectorielle (vector store).
Dans la phase d’exécution, les fragments de texte les plus pertinents peuvent ensuite être extraits (retrieval) de ce vector store pour être livrés à titre de contexte au modèle de langage en vue de la génération de la réponse.
Illustration 2 : Phase d’ingestion d’un pipeline RAG
Base de connaissances et extraction de données
La première étape du pipeline Ingestion consiste à extraire le texte de la base de connaissances. La qualité des données qui atterriront dans l’index détermine largement la qualité de la réponse finale. Aussi convient-il d’écarter les informations non pertinentes et éventuellement d’enrichir la base de connaissances avec des sources complémentaires qui, quant à elles, contiennent bel et bien des informations pertinentes.
Chunking
L’étape suivante consiste à scinder le texte original en fragments plus petits (chunks). Cela permet de cibler des fragments de textes cohérents et en lien avec la question d’entrée pouvant servir de contexte au modèle de langage.
Cette scission (chunking) peut s’effectuer de plusieurs manières. La technique la plus simple vise à scinder le texte sur la base d’un nombre fixe de caractères. Un environnement de test comme l’open source LangChain Text Splitter Playground permet d’expérimenter la taille (chunk size) et l’éventuel chevauchement de fragments de texte (chunk overlap). Les chunks trop grands peuvent contenir des informations superflues, tandis que les chunks trop petits sont susceptibles de contenir trop peu d’informations.
Mieux encore que de scinder le texte sur la base d’un nombre fixe de caractères, il est possible de scinder le texte sur la base de sa structure. Il s’agit ici à tout le moins de conserver les phrases ou les paragraphes dans leur ensemble. Cette opération peut être réalisée par exemple avec le RecursiveCharacterTextSplitter de LangChain. Il est en outre possible de tenir compte de la structure des documents. Citons par exemple l’outil HTMLHeaderTextSplitter, qui permet de scinder un document HTML sur la base de certains éléments d’en-tête (h1, h2, etc.). De cette manière, les chunks forment un ensemble plus cohérent
Affinement du modèle d’embedding
La dernière étape avant la création de l’index est la création d’embeddings vectoriels basés sur les chunks. Un modèle d’embedding convertit en embeddings les chunks et la question d’entrée. Il s’agit de vecteurs multidimensionnels qui saisissent la sémantique du texte. Cela permet de rechercher les fragments de texte les plus liés sémantiquement à la question d’entrée.
Il est clair que le modèle d’embedding peut largement contribuer à la qualité du système de questions-réponses. Le choix du modèle d’embedding doit être aligné sur les besoins du projet, tels que la prise en charge d’un contenu multilingue. Le cas échéant, le modèle d’embedding peut être affiné pour mieux saisir les termes spécifiques à un domaine. Cela requiert toutefois un certain effort.
Phase d’exécution
La phase d’exécution est la phase au cours de laquelle la question d’entrée de l’utilisateur est traitée pour au final aboutir à la génération d’une réponse via les étapes d’extraction (retrieval) et de génération (generation). C’est aussi et surtout lors de cette phase que diverses techniques peuvent influencer favorablement la qualité du résultat final.
Recherche hybride
Une fois le contenu préparé et l’index construit, la question est de savoir comment trouver les fragments de texte qui répondent à la question d’entrée. La technique la plus simple est la recherche sémantique : pour la question d’entrée, il s’agit de rechercher les fragments de texte les plus “proches” et les plus sémantiquement liés dans l’espace vectoriel.
La recherche hybride combine une recherche textuelle (recherche lexicale ou recherche par mots-clés) et une recherche sémantique sur la base d’un index contenant à la fois du texte brut et des embeddings vectoriels.
L’avantage de la recherche vectorielle est qu’elle permet de trouver des informations sémantiquement corrélées à la question d’entrée, même en l’absence d’une correspondance de mots-clés. Par exemple, la question “Quel âge dois-je avoir pour un job d’étudiant ?” peut bel et bien être liée à un fragment tel que “à partir de 16 ans“. L’avantage de la recherche lexicale réside dans la précision apportée par la correspondance exacte des mots.
Les deux recherches – lexicale et sémantique – sont exécutées en parallèle et les résultats de ces deux recherches sont combinés en une seule liste de résultats. Ces résultats sont ensuite reclassés (re-ranking) en fonction de leur pertinence par rapport à la question d’entrée.
Cette étape importante garantit que les résultats les plus pertinents sont restitués, qu’ils soient le fruit d’une recherche sémantique ou d’une recherche lexicale. Cette étape de reclassement est particulièrement utile dans les techniques d’extraction qui restituent une liste étendue ou diversifiée de documents, comme la query expansion (voir ci-dessous).
Techniques concernant la question d’entrée
Un certain nombre de techniques ont pour but d’élargir l’entrée pour l’extracteur (query expansion) afin d’améliorer les résultats de l’extraction. En effet, l’extraction peut produire des résultats différents en raison de changements subtils dans la question d’entrée ou si les embeddings ne saisissent pas correctement la sémantique des données.
Multi-query retriever – Cette première technique utilise un LLM pour générer des questions supplémentaires basées sur la question d’entrée originale, comme variantes de la question d’entrée originale. Pour chacune de ces questions (y compris la question originale), une extraction des documents est exécutée. Enfin, la combinaison de tous les résultats est restituée. Le but est ainsi d’obtenir un ensemble de résultats plus riche et plus diversifié lors de l’extraction.
HyDE (Hypothetical Document Embeddings) est une méthode qui consiste à générer une réponse hypothétique pour la question d’entrée au moyen d’un appel supplémentaire au LLM. Cette réponse hypothétique et la question d’entrée originale servent alors d’entrée pour l’extraction. L’idée sous-jacente est que la réponse hypothétique peut être plus proche des documents pertinents dans l’espace d’embedding, en comparaison de la question d’entrée.
Sub-queries – Une question d’entrée complexe ou composée peut être divisée en plusieurs questions plus simples (sub-queries). Cela permet d’obtenir des réponses plus pertinentes, car chaque sous-question peut être traitée séparément.
Query re-writing – Enfin, les longues questions peuvent être résumées à l’essentiel (re-writing) par un LLM, ce qui peut profiter à la qualité de l’extraction.
Notons que les techniques ci-dessus recourent à un LLM et peuvent dès lors avoir un coût global plus élevé. La réponse finale peut aussi prendre plus de temps à parvenir en raison de l’exécution des appels supplémentaires au LLM.
Enrichissement du contexte
L’idée des techniques ci-dessous est d’apporter plus de contexte au modèle de langage (voir l’étape de génération du LLM dans l’illustration 1) que les seuls petits chunks obtenus lors de l’extraction.
Sentence window retriever – Cette technique consiste à initialement extraire une phrase (sentence) spécifique qui est la plus pertinente pour la question d’entrée. Cette phrase est ensuite élargie avec une fenêtre plus large de phrases avant et après la phrase en question. Ainsi, le modèle de langage peut bénéficier d’un contexte plus large pour générer une réponse, ce qui peut aboutir à une meilleure réponse.
Auto-merging retriever (ou Parent document retriever) – Ici, chaque chunk est initialement divisé selon une structure hiérarchique composée d’un parent node et de leaf nodes. Lors de l’extraction, les leaf nodes les plus pertinents sont recherchés. Si un certain nombre de leaf nodes d’un parent node correspondent à la question d’entrée, les leaf nodes plus petits sont fusionnés dans le parent node plus grand et l’intégralité du parent node est transmise à titre de contexte au modèle de langage.
Post-traitement
Après l’étape d’extraction, mais avant l’appel au modèle de langage pour générer la réponse, la liste des documents extraits peut encore être actualisée pour optimiser la qualité de la réponse.
Re-ranking – Il peut être utile de reclasser les documents extraits en fonction de leur pertinence, à l’aide d’un modèle. Cette étape est particulièrement utile dans les techniques d’extraction qui restituent une liste étendue ou diversifiée de documents, comme le multi-query retrieval.
Compression – Le simple fait de fournir plus de contexte dans l’idée que “la réponse se trouve quelque part” n’améliore pas la qualité de la réponse. Le modèle de langage a en effet plus de mal à trouver les informations réellement pertinentes dans le contexte. Il peut dès lors être utile d’éliminer les informations redondantes et superflues des documents récupérés.
Prompt engineering et affinement du modèle de langage
Si les techniques susmentionnées visent à optimiser la fourniture d’un contexte optimal au modèle de langage, il existe également des techniques axées sur la manière dont le modèle doit procéder. Le prompt engineering désigne l’art de communiquer les bonnes instructions au modèle de langage. Le few-shot prompting est une technique qui consiste à donner un ou plusieurs exemples de l’entrée et de la sortie attendues du modèle de langage.
Le modèle de langage proprement dit peut être affiné de manière à mieux suivre certaines instructions ou mieux gérer la terminologie spécifique. Cela demande toutefois un gros effortet n’est clairement pas évident à réaliser.
Conclusion
De nombreuses techniques peuvent contribuer à améliorer la qualité des réponses dans un système génératif de questions-réponses. Dans cet article, nous n’en avons abordé que quelques-unes. D’après notre expérience, une recherche hybride permet déjà d’améliorer considérablement la précision des réponses. D’autres techniques peuvent certainement s’avérer utiles, en fonction des besoins spécifiques du projet ; il n’existe pas de solution universelle.
Même si nous parvenons finalement à une qualité élevée, des erreurs demeurent possibles et celles-ci doivent être prises en compte, tant sur le plan de la gestion des attentes des utilisateurs que sur le plan juridique. Une notification indiquant que la réponse est le produit de l’intelligence artificielle est donc indispensable et l’utilisateur final doit en être conscient. Le retour d’information des utilisateurs finaux est un bon moyen d’évaluer la qualité du système et de procéder à des ajustements constants si nécessaire.
Ce post est une contribution individuelle de Bert Vanhalst, IT consultant chez Smals Research. Cet article est écrit en son nom propre et n’impacte en rien le point de vue de Smals.
Bron: Smals Research
