Un fraudeur ne fraude jamais seul
Posted on
09/08/2016
by
Vandy Berten
Depuis toujours, certains essayent d'obtenir davantage que ce que la société veut leur accorder. Et depuis tout aussi longtemps, la société met un certain nombre de moyens en place pour prévenir ces abus. Aujourd'hui, la fraude occupe des équipes entières dans toutes les grandes banques, les assurances ou les institutions publiques et services de police et de renseignements. Si les techniques "classiques" (analyse individuelle et manuelle de dossiers, contrôles sur le terrain...) ont encore de beaux jours devant elles, tous ces organismes ont maintenant à leur disposition de très grandes quantités d'informations numériques à partir desquelles elles essayent de mettre en évidence des comportements suspects.
Techniques classiques
Voyons quelques techniques, ultra-simplifiées ici à titre d'illustration, d'analyse de données permettant de suspecter des fraudes, et qui nécessiteront bien sûr, ensuite, une investigation plus approfondie.
Détection "d'outlier"
On peut raisonnablement estimer que, dans la restauration, le chiffre d'affaire et le nombre d'employés soient corrélés, c'est-à-dire que, en général et pour une même classe de restaurant et une même région, une enseigne avec plus de personnel aura un chiffre d'affaire plus important (les deux mesures étant liées à un troisième facteur, à savoir le nombre de tables ou de clients). Un organisme tel que le ministère des finances, qui possède ces deux données, pourrait donc dessiner un graphique en nuage de points, dans lesquels chaque point représente un restaurant ; sa position sur l'axe des abscisses représente son nombre d'employés et sur l'axe des ordonnées son chiffre d'affaire, tel qu'illustré ci-contre (données totalement fictives). 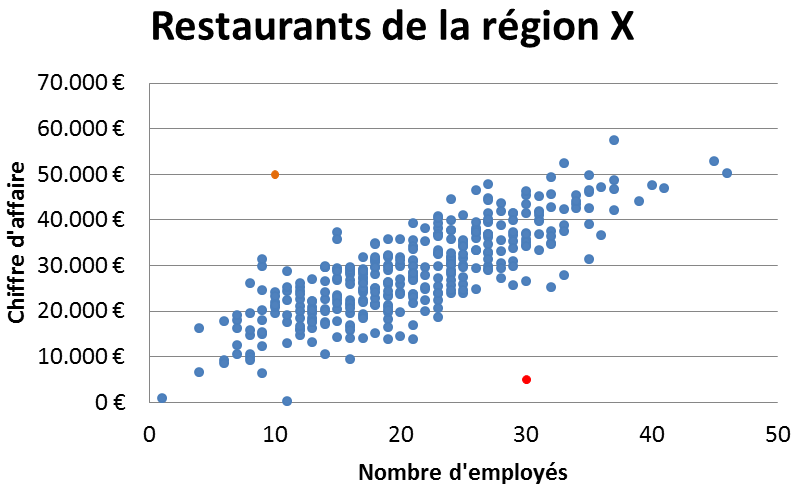
Dans l'exemple ci-contre, le point orange en haut à gauche représente un restaurant ayant soit un chiffre d'affaire particulièrement élevé (par rapport à son nombre d'employés), soit un nombre d'employés très bas (par rapport à son chiffre d'affaire). On pourrait dès lors suspecter qu'une partie du personnel ne soit pas déclaré, voire, pire, que du blanchiment d'argent soit en cours dans ce restaurant.
De façon similaire, on pourrait suspecter dans le cas du point rouge (en bas) qu'il corresponde à un restaurant qui cache une partie de son chiffre d'affaire, ce qui pourrait inciter le service d'inspection à envoyer un de ses inspecteurs. En général, on appelle "outlier" une observation statistique qui se distingue nettement de la grande majorité des données. Il va de soi que dans la réalité, on fait se genre d'exercice sur plus que deux variables.
Analyse du comportement
Les voleurs de cartes de crédit ont souvent un comportement d'achat en ligne différent d'un utilisateur classique. Par exemple, un fraudeur utilisera souvent plusieurs numéros de cartes de crédit depuis le même ordinateur (et donc depuis la même adresse IP). On sait aussi que, souvent, un fraudeur qui vient de voler un numéro de carte de crédit commence par l'essayer sur un faible montant, puis ensuite effectue une série d'achats plus conséquents. Par ailleurs, un même numéro volé peut avoir été revendu à plusieurs personnes ; un même numéro utilisé depuis deux ordinateurs très distants sur un court laps de temps peut être également considéré comme suspect. En combinant ce genre de règles, on peut établir un score, qui, s'il dépasse un seuil défini, déclenche un processus de vérification (comme par exemple un appel téléphonique au propriétaire de la carte).
Techniques de "Machine learning"
Comme la plupart des sociétés, les banques n'aiment pas prendre de risque, à moins qu'ils soient maîtrisés ou que le gain soit à hauteur du risque. Pour évaluer le risque qu'un client ne rembourse pas un crédit, les banques se servent souvent de techniques d'apprentissage automatique (machine learning). L'une d'entre elles consiste à fournir à un algorithme les données d'un grand nombre de crédit accordés par le passé (montant, nombre de mensualité, âge du créditeur, salaire, économies, situation familiale, autres crédits en cours, nombre de remboursements en retard, niveau d'études...), de façon à évaluer, lorsqu'un nouveau crédit est demandé, s'il doit être considéré comme risqué ou non. Autrement dit, on regardera si, dans une situation similaire (par rapport au créditeur et au crédit), les remboursements se passent en général bien ou non. Il s'agit de techniques de classification qui ont de nombreuses applications.
Paradoxe du faux positif
Un des grands arguments des opposants à l'utilisation de données massives par les services de police et de renseignement est connu sous le nom du "paradoxe du faux positif". Supposons que, parmi la population belge, que nous arrondirons à 10 millions d'individus, il y ait 100 terroristes susceptibles de passer à l'action, et que, sur base d'une combinaison de techniques présentées ci-dessus (basées, par exemple, sur les méta-données de ses communications téléphoniques et par courriel, ou sur base du comportement sur les réseaux sociaux), on établisse un test qui identifie un terroriste, avec une fiabilité de 99 %, c'est-à-dire que 99 % des individus testés seront correctement catégorisés (et 1 % sera mal catégorisé). Avec un tel test, 99 des 100 terroristes seront (en moyenne) correctement identifiés par notre test (un seul individu sera donc un "faux négatif"). Ce qui peut sembler encourageant... mais cela signifie également que, parmi les (presque) 10 millions de personnes fiables, 1 %, soit 100'000 personnes, seront également qualifiées de terroristes (il s'agit donc de faux positifs). On aura donc que parmi le groupe de 100'099 personnes considérées par le test comme terroriste, moins d'un pour-cent sera en fait effectivement terroriste. Il ne sera clairement pas possible de tous les mettre sur écoute, ou de le faire surveiller.
Pour neutraliser le terrorisme en se basant uniquement sur des données collectées, il faudra donc un test beaucoup plus fiable que celui à 99 % évoqué ci-dessus.
Garbage In, Garbage Out
Par ailleurs, les chiffres présentés ci-dessous ne seront atteints que si les données sont de bonne qualité, c'est-à-dire que les données encodées correspondent à la réalité observable : les adresses des entreprises sont toujours correctes, un nom n'a pas mal été orthographié et confondu avec une autre personne... si ce n'est pas le cas, les résultats des algorithmes seront bien entendu encore moins fiables. D'où l'adage "garbage in, garbage out" : si on donne des données de mauvaise qualité à un algorithme, aussi performant soit-il, le résultat sera de mauvaise qualité. Or dans la réalité, il est d'une part impossible, à partir du moment où une personne encode des données, de s'assurer qu'elles soient toujours correctes, et d'autre part, la réalité évolue toujours plus vite que les données la représentant.
Limites
Une caractéristique commune des méthodes présentées ci-dessous est que l'on analyse le comportement ou la position d'une entité en la comparant ensuite à des repères calculés au préalable (typiquement basés sur l'ensemble des autres entités). Mais on ne considère pas une entité dans sa relation avec d'autres entités. Or en général, les fraudeurs et criminels n'agissent pas seuls. Un entrepreneur monte une structure financière parce qu'un de ses collègues l'a fait avec succès avant lui ; une personne entre dans le monde de la délinquance parce qu'elle est en contact avec des gens qui en font déjà partie. C'est de façon générale ce que les sociologues appellent l'homophilie : qui se ressemble s'assemble, toute personne est influencée par son environnement et ses relations (à ne pas confondre avec l'acception plus répandue de l'homophilie concernant l'orientation sexuelle).
De plus en plus, on s'intéresse au réseau social des entités considérées. Par réseau social, on n'entend bien sûr par Facebook ou Twitter, mais un ensemble d'entités (personnes, entreprise, lieu...) et les relations qui existent entre elles (l'individu I travaille pour ou dirige l'entreprise E, qui a son siège social à l'adresse A, I1 a téléphoné à I2...).
Analyse de réseaux sociaux
Un réseau (ou un graphe) est donc une abstraction mathématique qui représente un ensemble d'entités (appelées nœuds), dont certaines sont reliées entre elles (au travers de liens, ou d'arcs). Un blog y a déjà été consacré il y a quelques temps. Dans la majorité des pays du monde, les services officiels, tels que ceux liés à la sécurité sociale, au ministère des finances ou de l'économie, disposent d'un grand nombre d'informations pouvant être vues comme un réseau :
- Une personne P travaille, est gérante ou administratrice d'une entreprise E. P et E sont les nœuds, l'arc est la relation de travail
- Une entreprise E a son siège social à l'adresse A (éventuellement commune à d'autres entreprises)
- Une entreprise E1 sous-traite une partie d'un travail, comme un chantier de construction, auprès d'une entreprise E2.
Pour chacune de ces relations, l'arc peut disposer d'un certain nombre de labels ou d'attributs : date de début, date de fin, type de relation ("travailleur", "gérant", "siège social"...), éventuellement poids de la relation (nombre de parts d'un actionnaire, montant financier d'une sous-traitance...)
Des services de police ou de renseignements peuvent également disposer d'autres informations :
- Une personne P1 téléphone à une personne P2
- Une personne P1 est le père/frère/cousin d'une personne P2
- Une personne P a été vue à l'endroit X
Faillite organisée
Une technique de fraude sociale répandue consiste à créer une société, y engager du personnel et le rémunérer, éventuellement commander des fournitures et, juste avant de devoir payer les charges sociales ou les fournisseurs, s'arranger pour mettre la société en faillite. Il suffit alors de recommencer le même processus, idéalement dans une autre région pour ne pas tomber sur les mêmes juges ou curateurs. Ce type de fraude est connu sur le nom de "spider construction" (ref1, ref2). Le schéma est en général complexe : on a par exemple deux associés, qui s'associent chaque fois à des personnes différentes pour créer différentes sociétés fictives ; avec de temps en temps des sous-traitants complices, de temps en temps victimes. 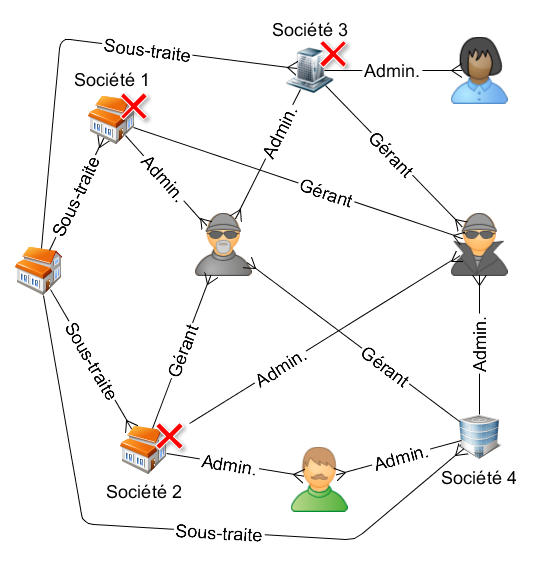 Un fraudeur peut par ailleurs être gérant d'une compagnie, puis administrateur d'une autre et comptable de la troisième.
Un fraudeur peut par ailleurs être gérant d'une compagnie, puis administrateur d'une autre et comptable de la troisième.
La figure ci-contre illustre un exemple, dans lequel trois sociétés (1, 2, 3, marquées par une croix rouge) ont déjà fait faillite, et par lesquelles les deux individus du milieu sont passés. Par ailleurs, une société a été sous-traitante pour les trois sociétés en question. La société 4 mérite toute l'attention des inspecteurs : elle partage à la fois les deux personnes "suspectes", ainsi que le sous-traitant potentiellement complice.
Homophilie et diffusion
La technique précédente ne présuppose aucune connaissance par rapport au caractère frauduleux de certaines personnes. Mais souvent, les services d'inspection ont un historique et ont déjà pu découvrir de nombreux cas de fraude. Cette connaissance peut alors être utilisée. On se base alors sur le principe de l'homophilie déjà évoqué ci-dessus : on a plus de chance de trouver un fraudeur (ou plus généralement un criminel) dans l'entourage proche d'un autre fraudeur qu'en inspectant une personne ou une entreprise totalement au hasard. On constate également que plus une entreprise est liée à une entreprise où de la fraude a été mise à jour (beaucoup de responsables en commun, des sous-traitants identiques...), plus y a de la chance d'y trouver de la fraude.
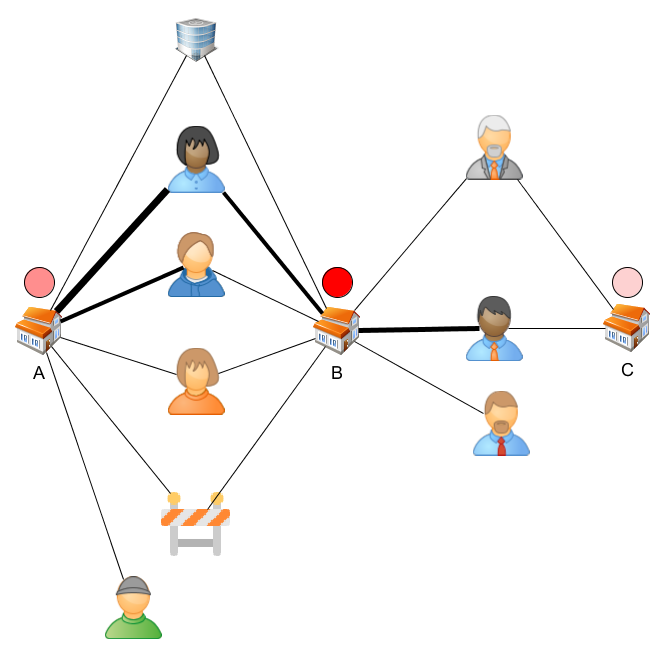 Dans l'exemple ci-contre, une fraude a été mise au jour au sein de la société B, au centre (macaron rouge). On va dès lors examiner toutes les entreprises "voisines", c'est-à-dire ayant partagé des employés (pas nécessairement simultanément), travaillé sur des chantiers communs (s'il s'agit d'entreprises de construction), ou utilisant des mêmes fournisseurs ou sous-traitants. Une relation ayant duré plus longtemps sera considérée comme plus "forte" (lignes plus épaisses dans le schéma ci-contre).
Dans l'exemple ci-contre, une fraude a été mise au jour au sein de la société B, au centre (macaron rouge). On va dès lors examiner toutes les entreprises "voisines", c'est-à-dire ayant partagé des employés (pas nécessairement simultanément), travaillé sur des chantiers communs (s'il s'agit d'entreprises de construction), ou utilisant des mêmes fournisseurs ou sous-traitants. Une relation ayant duré plus longtemps sera considérée comme plus "forte" (lignes plus épaisses dans le schéma ci-contre).
L'entreprise A étant plus fortement connectée à B que C, elle sera considérée comme plus à risque (macaron rose foncé pour A, pâle pour C). Par ailleurs, si A était également proche d'une autre entreprise aussi considérée comme à risque, cela ferait augmenter son "score de risque" en conséquence.
Plus généralement, les techniques utilisées pour diffuser les scores de risques sont proches de l'algorithme "PageRank" de Google, utilisé pour trier les résultats d'une recherche. Plus une page est importante, plus elle donnera de l'importance aux pages vers lesquelles elle a des liens.
Dynamique des réseaux
 Dans le but d'éviter d'être repérés par la police, il n'est pas rare que deux individus ne se contactent jamais directement, mais passent systématiquement par un intermédiaire pour se transmettre des informations. Si l'on considère toutes les conversations téléphoniques entre les membres d'un groupe sous surveillance, comme illustré ci-contre, on pourrait penser que Charline n'est jamais en contact avec Bob, et que Danièle ne communique pas avec Frank.
Dans le but d'éviter d'être repérés par la police, il n'est pas rare que deux individus ne se contactent jamais directement, mais passent systématiquement par un intermédiaire pour se transmettre des informations. Si l'on considère toutes les conversations téléphoniques entre les membres d'un groupe sous surveillance, comme illustré ci-contre, on pourrait penser que Charline n'est jamais en contact avec Bob, et que Danièle ne communique pas avec Frank.
Mais si l'on observe ce réseau comme un film, en ne considérant que les contacts ayant eu lieu sur une fenêtre de temps relativement courte, on pourrait apercevoir que, chaque fois que Danièle contacte Éric, celui-ci contacte Frank dans la foulée (temps 1), et que dans les minutes qui suivent chaque appel de Charline à Éric, ce dernier appelle systématiquement Bob (temps 2).
On peut donc en conclure que Danièle et Frank sont plus que probablement en contact (indirect), ainsi que Charline et Bob, et que, dans les deux cas Éric sert d'intermédiaire.
De façon générale, si l'on peut déjà obtenir beaucoup d'information d'un réseau "statique", considérer sa composante dynamique ou temporelle apporte souvent de nombreux renseignements précieux.
Conclusions
L'analyse de réseaux sociaux (ou Social Network Analytics) est une des grandes tendances du moment en matière de lutte contre la fraude. Les grands fournisseurs de logiciels que sont SAS ou IBM mettent par ailleurs beaucoup de moyens dans le développement d'outils tels que SAS SNA ou IBM I2, avec pour cible tant les grandes sociétés privées (banques, assurances, télécommunication...) que les services publiques (sécurité sociale, finance, police...).
Avec des outils d'analyse de réseaux dans des environnements "Big Data", des outils comme GraphX de Spark (compatible avec Hadoop) ouvrent encore de nouvelles possibilités, étant donné la quantité de plus en plus importante de données à la disposition des organismes, et la complexité de certains algorithmes.
Il va de soi de ces nouvelles possibilités d'analyse posent des questions en matière de vie privée. On peut par exemple techniquement sans difficulté combiner des données officielles avec des données publiques collectées sur Facebook ou Twitter. Ceux qui font donc ce genre d'analyse doivent s'assurer de le faire en conformité avec la loi. Et il va dans l'intérêt du citoyen lambda de faire attention à ce qu'il laisse trainer sur les réseaux sociaux.
Références :
- [book] "Fraud Analytics ; using descriptive, predictive and social network techniques", B. Baesens, V. Van Vlasselaer & W. Verkere, Winley, 2015
- Social Network Analysis for Fraud Detection (B. Baesens, V. Van Vlasselaer)
- Social Networks for Fraud Analytics (B. Baesens, V. Van Vlasselaer)
Schémas réalisés avec yEd (http://yed.yworks.com)
Bron: Smals Research
