Tokenization : méthode moderne pour protéger les données
 En sécurité de l'information, les protections périphériques ne sont plus suffisantes pour protéger correctement les données d'un système. Les attaquants arrivent tôt ou tard à pénétrer le système et à accéder directement aux données. C'est pourquoi il est donc primordial de pouvoir faire appel à des techniques pour sécuriser directement les données. Les plus connues à l'heure actuelle sont le chiffrement cryptographique et le masking. Une nouvelle méthode, relativement méconnue, pourtant très efficace, est de plus en plus utilisée dans les outils de protection de données : la tokenization. Cette dernière a pour but de substituer une donnée par une valeur aléatoire unique, nommée token.
En sécurité de l'information, les protections périphériques ne sont plus suffisantes pour protéger correctement les données d'un système. Les attaquants arrivent tôt ou tard à pénétrer le système et à accéder directement aux données. C'est pourquoi il est donc primordial de pouvoir faire appel à des techniques pour sécuriser directement les données. Les plus connues à l'heure actuelle sont le chiffrement cryptographique et le masking. Une nouvelle méthode, relativement méconnue, pourtant très efficace, est de plus en plus utilisée dans les outils de protection de données : la tokenization. Cette dernière a pour but de substituer une donnée par une valeur aléatoire unique, nommée token.
Méthodes de tokenization
Il existe essentiellement deux méthodes de tokenization.
1. Vault-based tokenization
Avec cette méthode, il n'y a aucune relation mathématique, ni aucune logique entre la donnée originale et le token correspondant. C'est donc un mapping aléatoire unique "donnée-token".
Pour chaque type de données, un mapping est généralement stocké dans une table, nommée lookup table (p.ex. figure 1 ci-dessous). Toutes les lookup tables sont alors stockées sur un serveur de tokens, comme représenté dans la figure 2 ci-dessous.
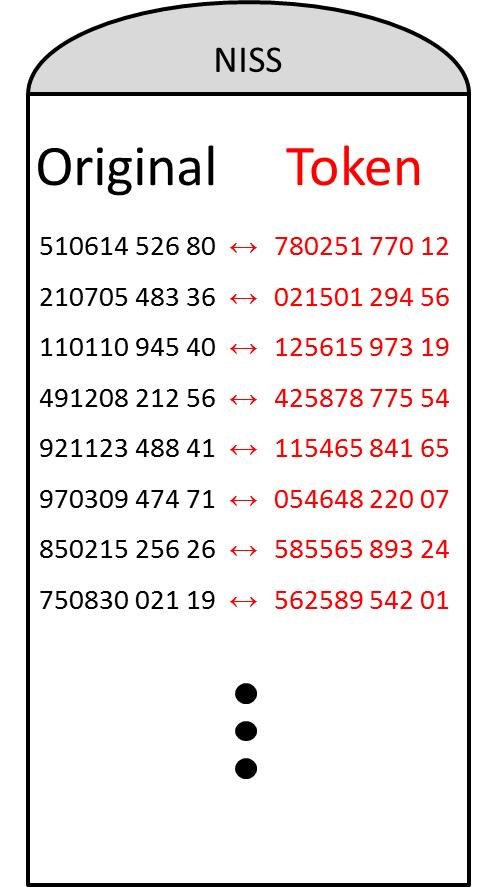 Figure 1: Exemple de lookup table pour des numéros NISS (Numéro d’Identification unique à la Sécurité Sociale). Figure 1: Exemple de lookup table pour des numéros NISS (Numéro d’Identification unique à la Sécurité Sociale). |
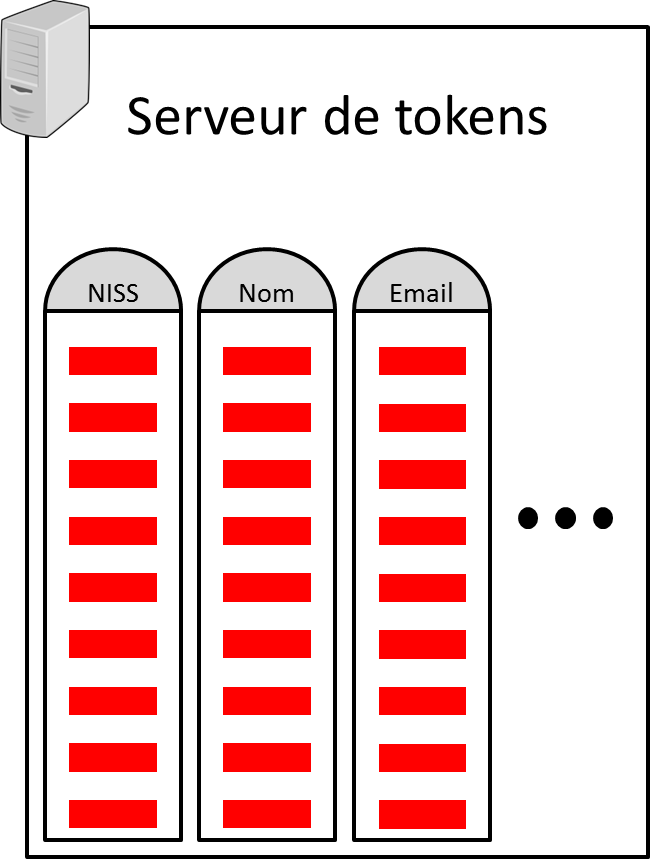 Figure 2: Exemple de serveur de tokens. Figure 2: Exemple de serveur de tokens. |
Cette méthode peut être problématique quand la quantité de données à tokeniser augmente perpétuellement. En effet, si les lookup tables ne font que grossir, alors (1) la taille du serveur de tokens doit sans cesse être augmentée, et (2) il est difficile de répliquer un serveur de tokens de taille trop grande ailleurs.
La vault-based tokenization est donc la méthode la plus basique, à utiliser de préférence pour un ensemble de données assez petit, qui ne varie pas ou n'augmente pas beaucoup.
2. Vaultless tokenization
L'autre méthode de tokenization consiste en créer une ou plusieurs lookup tables génériques par type de données, comme illustré dans la figure 3 ci-dessous. Pour une base de données simple, on peut ainsi seulement créer une lookup table pour les nombres, et une pour les mots. Ces lookup tables sont pré-calculées à l'avance et bien sûr randomisées. Elles sont donc d'une taille fixe, préférablement plus petite que les tables de la méthode vault-based.
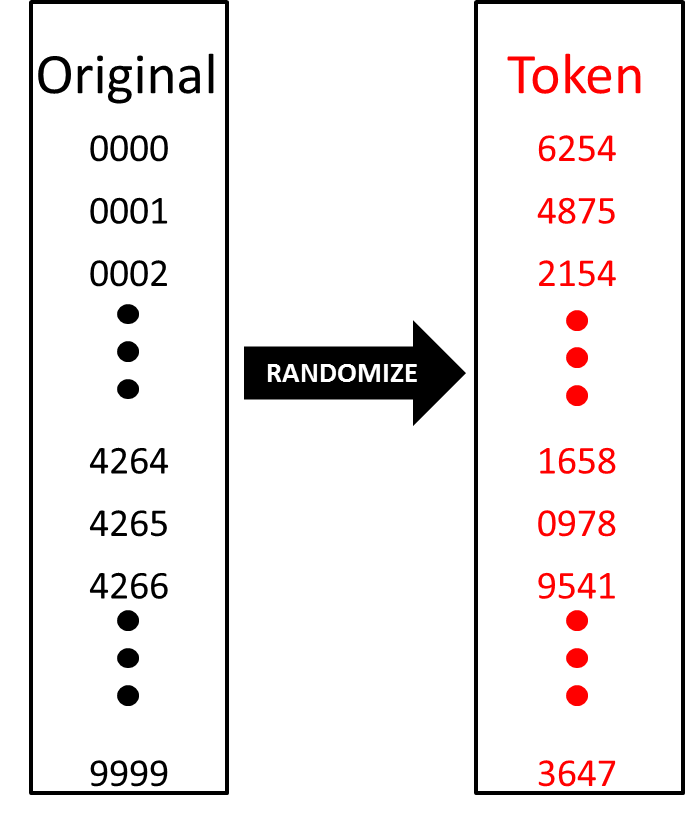 Figure 3: Exemple de lookup table à utiliser pour les nombres. On a pris une base fixe de 4 chiffres. Tous les nombres entre 0000 et 9999 sont randomisés dans la table. Par exemple, le token du nombre 4264 est 1658. Figure 3: Exemple de lookup table à utiliser pour les nombres. On a pris une base fixe de 4 chiffres. Tous les nombres entre 0000 et 9999 sont randomisés dans la table. Par exemple, le token du nombre 4264 est 1658. |
 Figure 4: Exemple simple de vaultless tokenization d'un numéro de carte de crédit, en utilisant bloc-par-bloc la lookup table de la figure 3. Figure 4: Exemple simple de vaultless tokenization d'un numéro de carte de crédit, en utilisant bloc-par-bloc la lookup table de la figure 3. |
Avec ces tables pré-calculées, il est alors possible de tokeniser les données correspondantes. Par exemple, la figure 4 ci-dessus illustre une tokenization d'un numéro de carte de crédit. Notons que cet exemple de tokenization très simple est montré ici pour son aspect didactique. Il est tout à fait possible d'imaginer une tokenization plus élaborée, plus complexe, par exemple qui se servirait de 2 lookup tables de nombres (au lieu d'une), et/ou qui mélangerait davantage les nombres (au lieu d'un simple bloc-par-bloc).
La vaultless tokenization est donc la méthode la plus adéquate lorsqu'on souhaite tokeniser des ensembles de données grands et dynamiques.
Pourquoi la tokenization est-elle une méthode intéressante?
Tout d'abord, le critère unique et aléatoire d'une tokenization est très intéressant : il empêche tout attaquant de détokeniser et de retrouver la donnée originale à partir du token sans avoir les lookup tables correspondantes. Ces dernières sont en fait l'équivalent d'une clé cryptographique "super-puissante" dans un système standard de chiffrement. Donc le niveau de sécurité d'une tokenization est très élevé. Bien sûr, ceci est valable que lorsque les lookup tables sont stockées de manière protégée. Aussi, les données, même tokenisées, sont utilisables "as-is". il est donc possible de faire des SEARCH et des SORT dans une base de données tokenisées. Un des seuls points négatifs est la taille des lookup tables, qui peut s'avérer très grande si l'on utilise la mauvaise méthode de tokenization. Donc le lieu de stockage des tables doit être pensé en fonction de cela.
La tokenization est déjà utilisée dans plusieurs domaines où la sécurité est primordiale. Le plus courant est le milieu bancaire. Par exemple, la tokenization est souvent utilisée pour protéger les données stockées, comme demandé par le standard PCI DSS (Payment Card Industry Data Security Standard). Autre exemple : en mars 2014, EMVCo (consortium des grandes firmes bancaires telles que Europay Mastercard Visa) a publié une méthode de tokenization pour les paiements EMV. On peut aussi retrouver la tokenization dans les systèmes de données médicales, ou encore pour les casiers judiciaires.
En fin de compte, c'est une technologie très intéressante, qui n'est qu'à ses balbutiements en terme de déploiement pratique, mais qui s'annonce être une petite révolution dans la protection des données.