La gestion de la qualité de données (Data Quality), régulièrement abordée dans ce blog, consiste souvent à traiter (comparer, simplifier, transformer, “phonétiser”…) des chaînes de caractères : des noms de personnes, d’entreprises, de villes, de rues, numéros de téléphones, adresses email…
Dans cet article, nous allons considérer le genre de problèmes que l’on peut détecter lorsque les données sont associées à des coordonnées géographiques (latitudes, longitudes), en considérant les données ouvertes du projet “BeSt Address” (pour “Belgian Street Address”), du SPF BOSA (Service Public Fédéral Stratégie & Appui), source authentique des adresses en Belgique. Ce projet agrège et consolide les données des régions (UrbiS pour la région bruxelloise, le Adressenregister pour la Flandre et ICAR pour la Wallonie), qui elles-mêmes récupèrent les données d’adresses collectées par chaque commune, autorité responsable de l’attribution des adresses. On peut y télécharger une série de fichiers CSV ou XML, permettant, pour chaque adresse en Belgique, d’en connaitre l’orthographe officielle ainsi que les coordonnées géographiques.
Notre expérience nous a montré que les données des BeSt Address sont de loin les données de la meilleure qualité par rapport à d’autres sources officielles contenant des adresses (Registre national, Répertoire des employeurs, Banque Carrefour des Entreprises…), à tout le moins sur les aspects classiques de la qualité de données (cohérence des noms, absence d’abréviation…), résultat de l’énorme travail réalisé par les équipes des régions et du SPF BOSA. Néanmoins, nous avons pu y trouver un certain nombre d’anomalies identifiables uniquement en considérant les données géographiques et des analyses spatiales.
Les anomalies identifiées correspondent en grande majorité à des adresses mal placées (mauvaises coordonnées), ou à des codes postaux problématiques. Le nettoyage ne pourra être fait que par les entités sur le terrain, à savoir les communes.
Notons que les anomalies présentées ci-dessous sont issues d’une analyse “académique”. Celle-ci a déjà été discutée avec un certain nombre de personnes des instances concernées (régions, registre national, SPF BOSA, IGN…), et certaines de ces anomalies sont considérées comme acceptables. Le but de cet article n’est pas de critiquer la qualité des données, mais simplement de présenter une méthodologie, en l’illustrant avec une source de données pertinentes.
Contexte
Comme déjà expliqué dans un article précédent, la Belgique est composée, à l’heure d’écrire ces lignes, de 581 communes (ce nombre diminuera dans les prochains mois, suite à une série de fusions de communes). Chacune de celles-ci est composée d’un ou plusieurs codes postaux (associés à un nom à Bruxelles et en Flandre), et chacun de ces codes postaux peut contenir une ou plusieurs sous-communes, ou localités (part of municipality en Wallonie, dans le jargon BeSt Address).
Pour l’analyse ci-dessous, nous sommes partis des fichiers CSV disponibles sur https://opendata.bosa.be/, et avons mené quatre types d’analyse :
Dans la première, nous regardons si tous les numéros de boite d’une même adresse sont bien localisés proches les uns des autres ;
Dans la deuxième, nous comparons les frontières des codes postaux définis par bpost (la poste belge) avec les codes postaux des adresses BeSt Address ;
Dans la troisième, nous recherchons des incohérences sur des noms de rues géographiquement proches (par exemple une “Rue Roi Albert I” juste à côté d’une “Rue du Roi Albert I”) ;
Dans la quatrième, nous recherchons des anomalies géométriques dans la forme d’une rue.
Incohérence de boites
Comme détaillé précédemment, une adresse contient toujours un “numéro de police”, ou numéro de maison, qui désigne le bâtiment, et, parfois, un “numéro de boite”, qui désigne l’unité d’habitation au sein de ce bâtiment. Dans BeSt Address, pour chaque adresse avec une boite, nous trouvons toujours une adresse équivalente de base (même rue, code postal, numéro) sans boite. Imaginons qu’au 20 de l’avenue Fonsny, on trouve deux boites, “boite 1” et “boite 2” : on trouvera trois items dans BeSt Address : “Avenue Fonsny 20” ; “Avenue Fonsny 20 boite 1” et “Avenue Fonsny 20 boite 2”.
Nous avons regardé pour chaque adresse (rue, code postal, numéro) si les coordonnées associées aux boites ne sont pas anormalement éloignées. Dans une grande majorité des cas, les différentes boites d’un même numéro auront toutes les mêmes coordonnées, mais ça n’est pas toujours le cas.
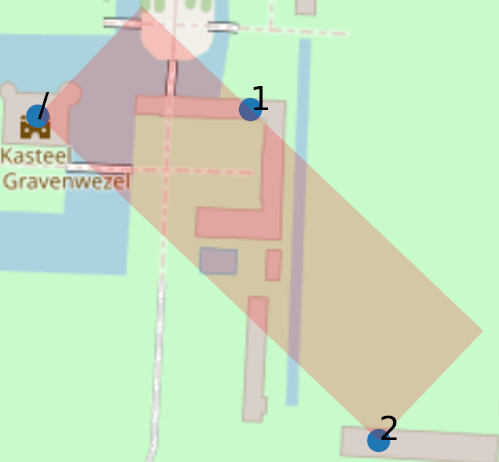
Pour chaque adresse ayant des numéros de boite, nous construisons pour ce faire le “rectangle orienté minimum” (minimum rotated rectangle), à savoir le rectangle de surface minimale englobant l’ensemble des points (les coordonnées de l’adresse “de base”, représentée par “/”, ainsi que celles de chacune des boites), en autorisant toute rotation du rectangle. Un tel rectangle englobant deux points aura une largeur nulle et une longueur équivalente à la distance entre les points. En cas de points multiples non alignés, les deux dimensions seront positives.
Les anomalies ont essentiellement été détectées en Flandre, avec plus de 100 cas. En Wallonie, les coordonnées des différentes boites sont toujours égales aux coordonnées de l’adresse de base. À Bruxelles, seules deux anomalies ont été détectées.
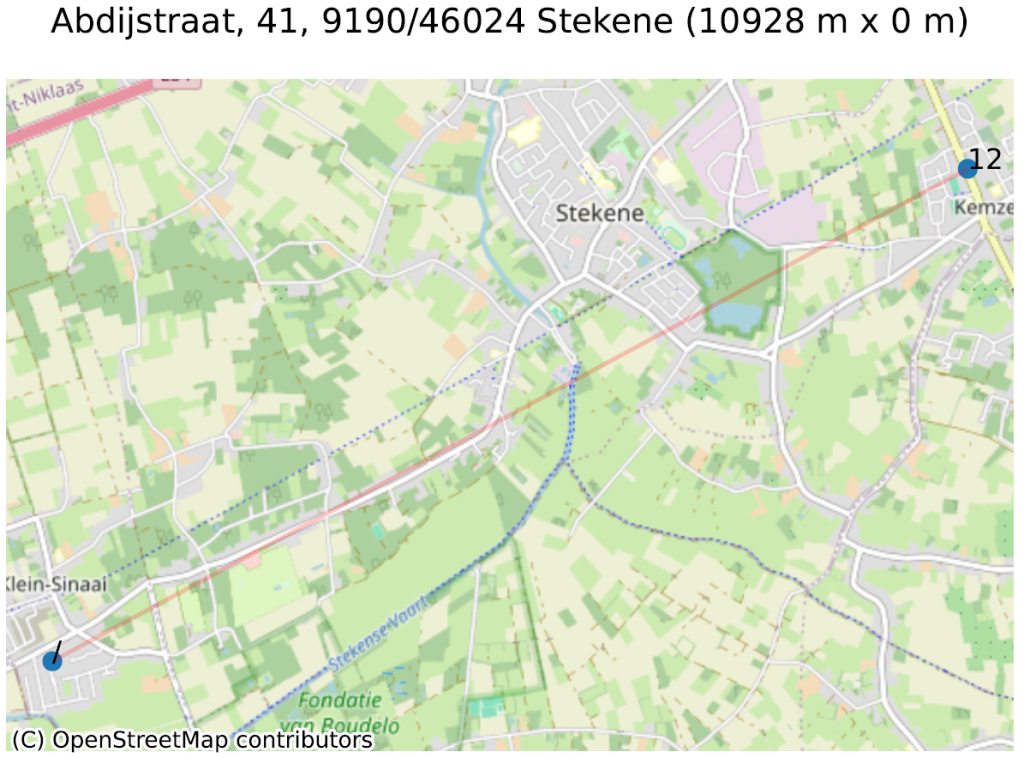
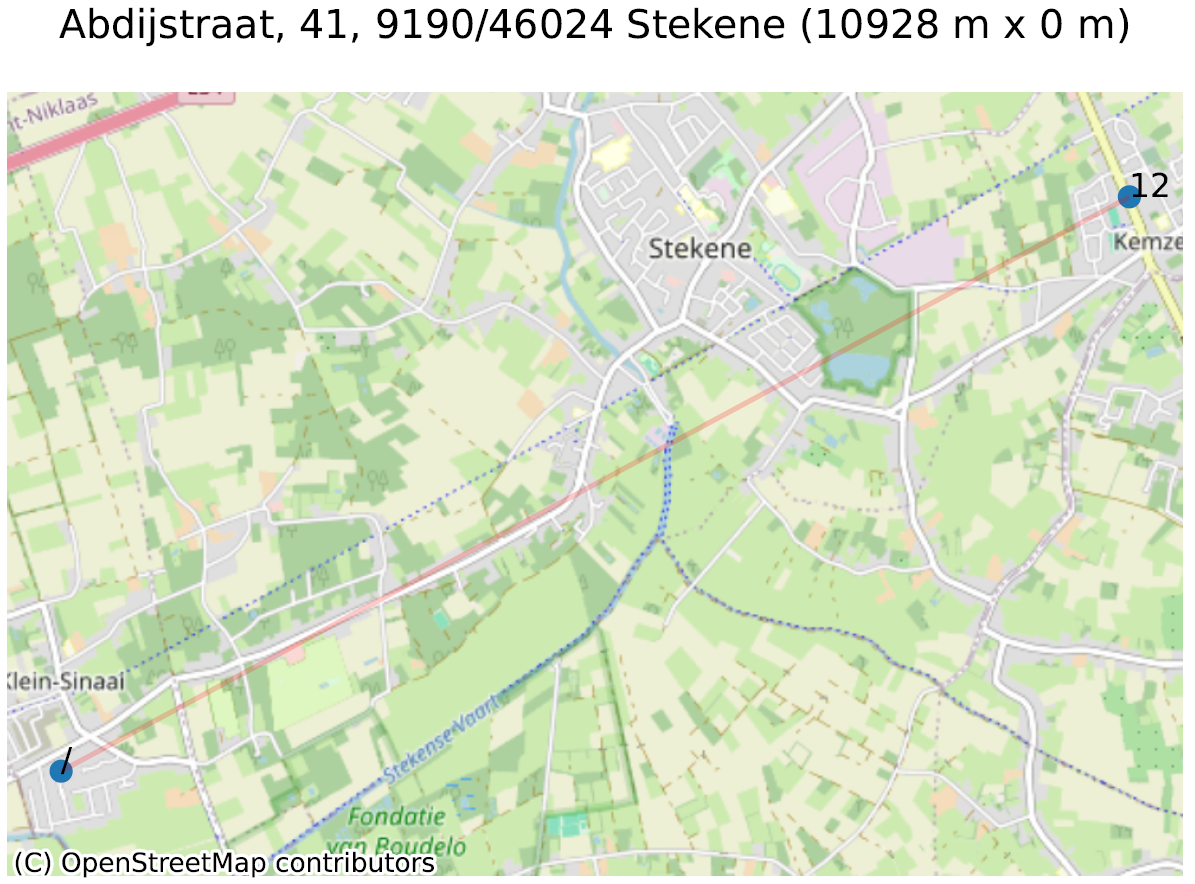
Pour illustrer ceci, prenons deux exemples, représentés dans la figure ci-dessous. Le premier exemple (Abdijstraat, 41 à 9140 Stekene) montre que l’adresse de base (Abdijstraat, 41, représenté par un “/”) est située à 11 kilomètres de Abdijstraat, 41 bus 12. Nous avons trouvé près d’une centaine d’exemples très similaires.
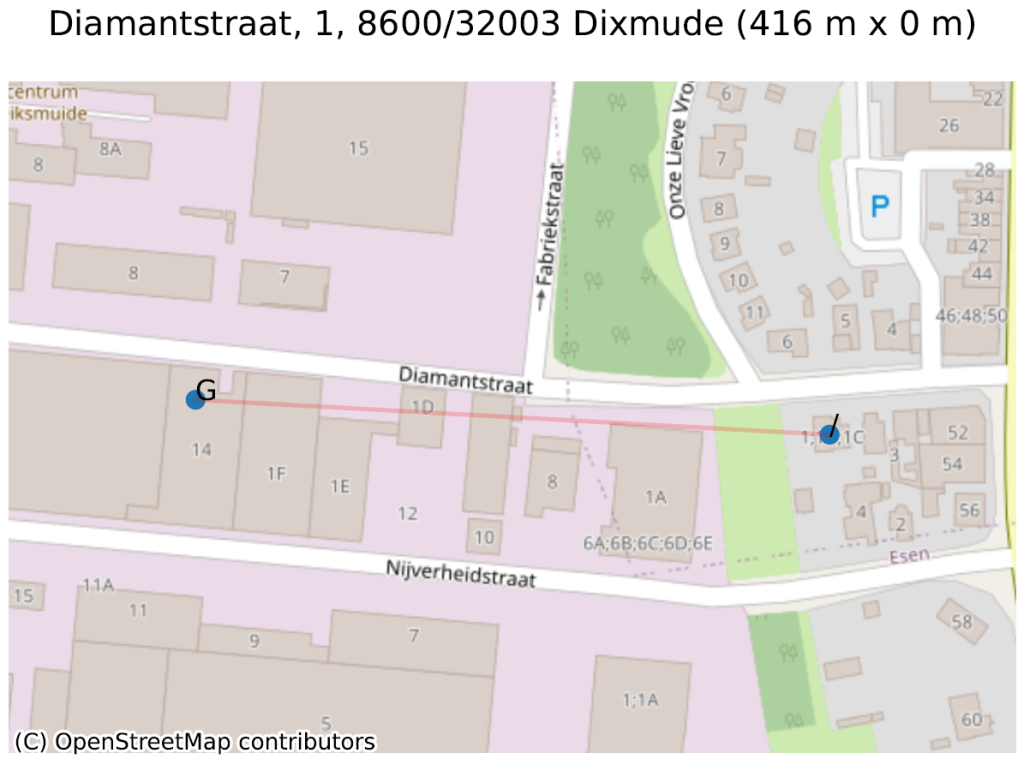
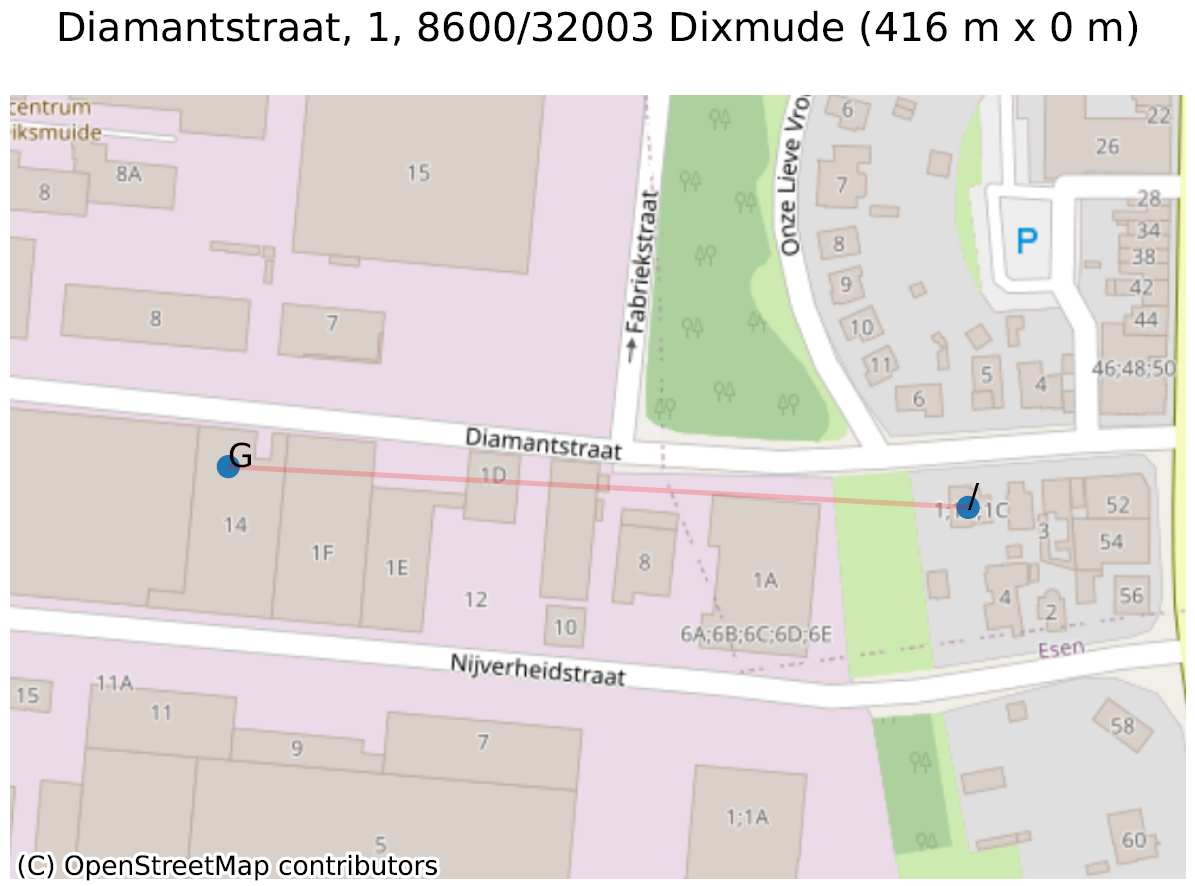
Le second est une conséquence du problème illustré dans notre article précédent : pour créer des adresses entre le “1” et le “3”, on peut soit créer les numéros de maison “1A”, “1B”, “1C”… (sans numéro de boite), soit toutes les appeler “numéro 1”, mais avec un numéro de boite “A”, “B”, “C”… Dans la “Diamantstraat” à Dixmude, un choix hybride (sans doute par erreur) a été fait : à côté du 1, on retrouve bien le “1A”, “1B”, … “1F”, puis … “1 boite G” ! Ceci génère une grande distance entre le 1 (adresse de base) et le 1 (boite G).
Frontières postales
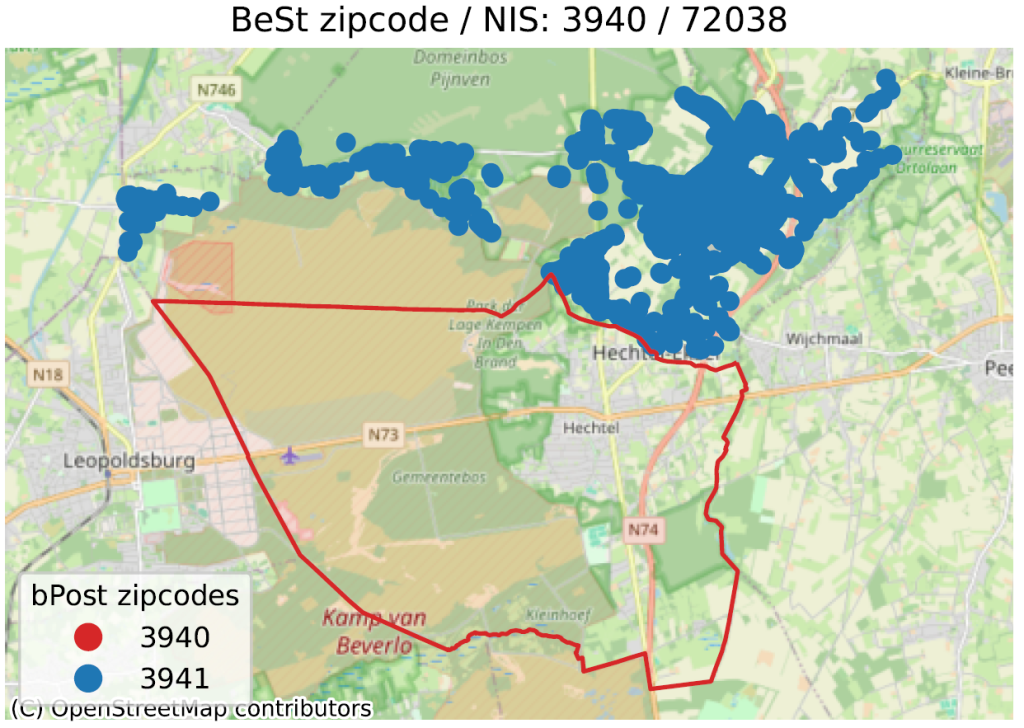
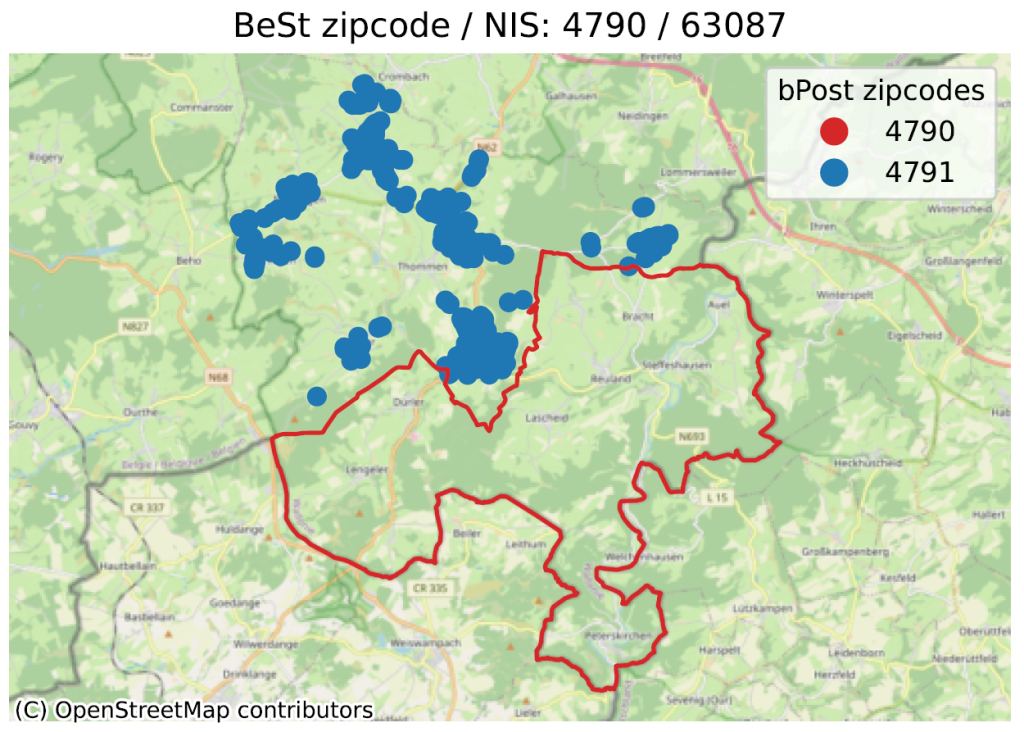
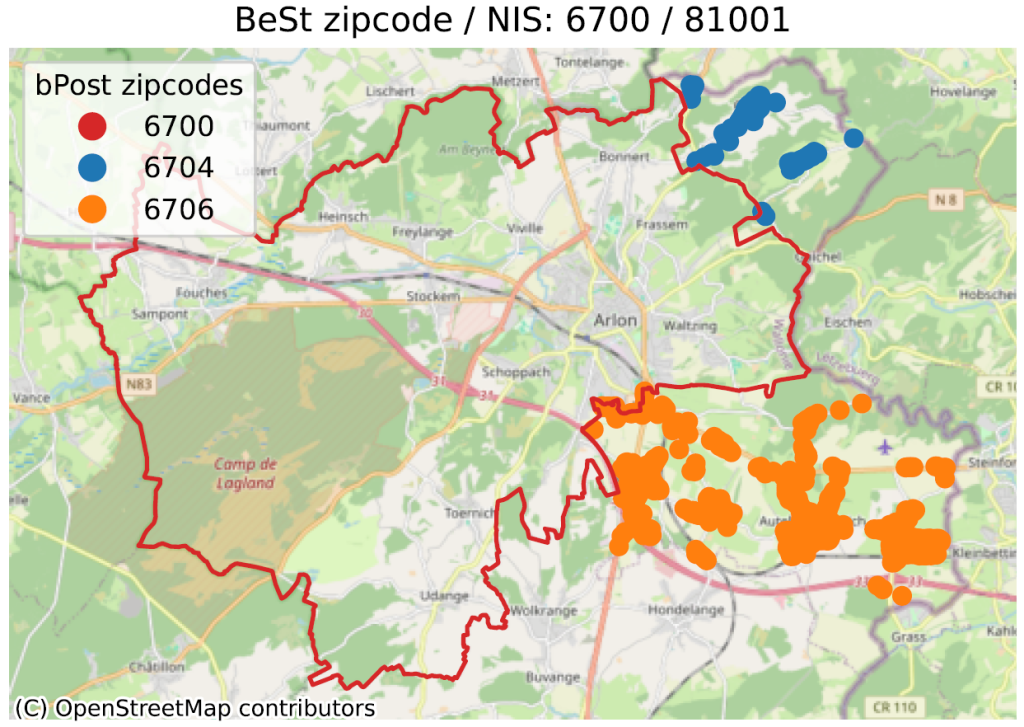
Dans cette analyse, nous comparons les frontières des codes postaux définies par bpost. Pour ce faire, pour chaque adresse de BeSt, nous regardons dans quel polygone de bpost elle tombe et on retient celles pour lesquelles il y a une inconsistance entre le code postal de BeSt et celui de bpost.
Pour éviter les problèmes de précision d’un point qui serait juste à la frontière, on supprime un ruban de 50 mètres des contours dans les codes postaux définis par bpost . On identifie donc une inconsistance uniquement quand une adresse d’un code postal P1 (selon BeSt) est réellement dans le polygone d’un code postal P2 (selon bpost), avec P1 ≠ P2.
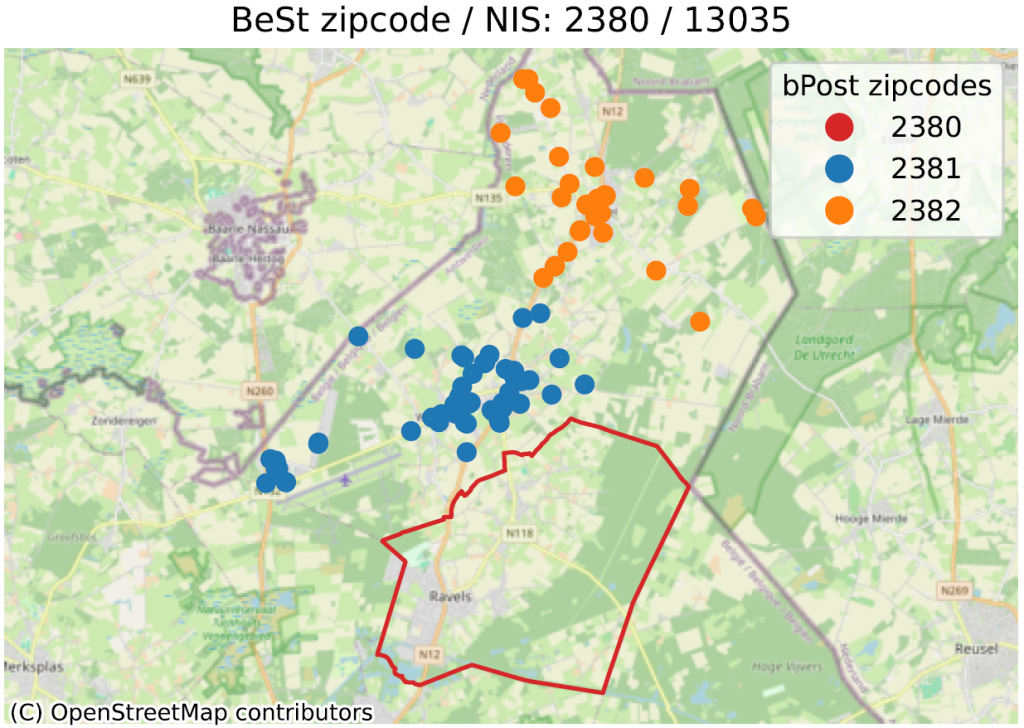
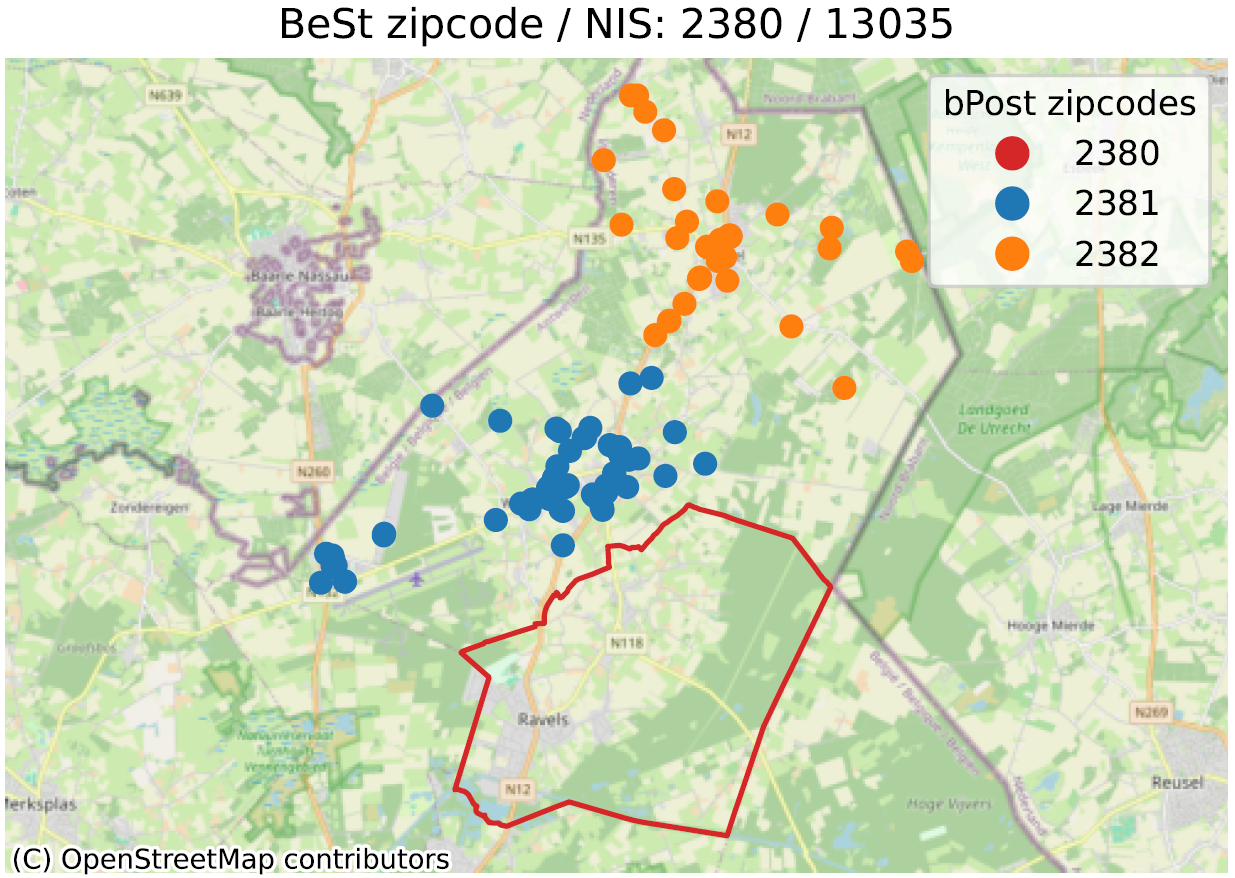
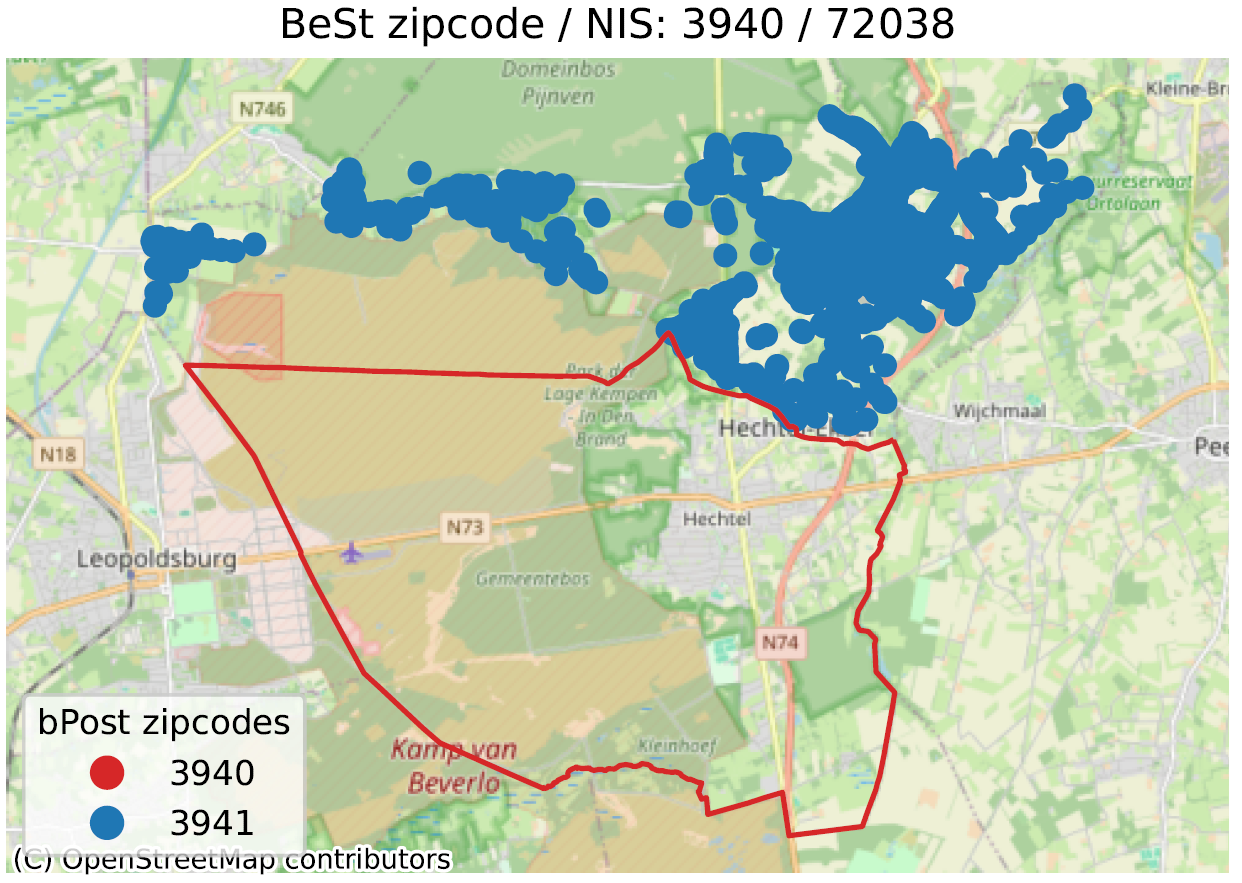
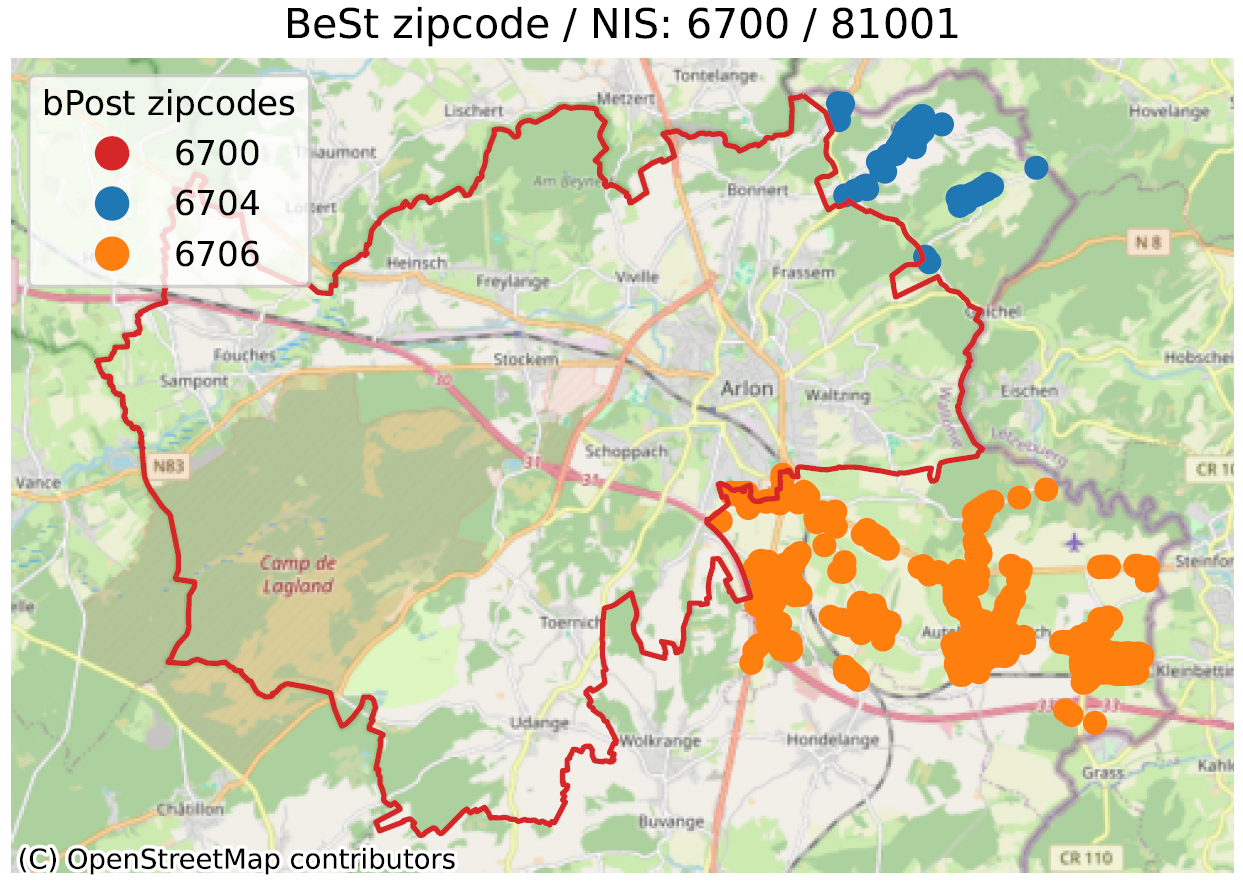
Dans les images ci-dessous, on peut voir quelques-uns des exemples identifiés. La ligne rouge représente la limite correspondant au code postal en titre, selon bpost (6700 pour l’exemple principal). À l’intérieur de cette ligne sont localisées un grand nombre d’adresses de BeSt, associées au même code postal, que nous ne représentons pas ici pour ne pas surcharger l’image. Les points de couleurs en dehors du contour rouge sont donc des adresses que BeSt associe au code en titre, mais qui, selon la poste, sont du code postal indiqué dans la légende (6704 en bleu, 6706 en orange pour le 1er exemple).
Notons que les “échanges” relevés se font toujours au sein d’une même commune (Arlon pour l’exemple). Mais alors que BeSt considère que toutes les adresses de la commune d’Arlon sont sur 6700, bpost considère qu’une partie du territoire est sur 6704 (Guirsch) ou 6706 (Autelbas-Barnich), deux codes postaux inconnus de BeSt.
Il ne s’agit pas uniquement d’une question d’un fichier (Shapefile) qui ne serait pas à jour sur le site de bpost : l’outil en ligne de validation d’adresse de bpost est bien cohérent avec les codes postaux présentés.
Lors de certaines discussions, il nous a été répondu que les communes avaient la liberté de modifier, au sein de leur territoire, l’attribution des codes postaux. Mais il n’y a pas de consensus là-dessus : dans le “Guide en matière de constatation et attribution d’adresses“, il est dit que “(…) les codes postaux et leur systématisation sont la propriété du prestataire du service postal universel, en l’occurrence (…) bpost. Ils ne peuvent être attribués et modifiés que sur proposition de bpost, et après avis motivé de l’IBPT et l’approbation du ministre conformément à l’article 135 de la loi du 21 mars 1991. (Article 22)”.
Nous avons trouvé un peu plus de 8.000 anomalies en Wallonie (sur un total de 1.85 M adresses pertinentes), ~11.000 en Flandre (sur 3.83 M), et un nombre marginal à Bruxelles (sur 860.000). Notons que certaines anomalies sont acceptables, comme par exemple le cas de bâtiments (château, ferme…) loin de la porte d’entrée. BeSt localise le bâtiment, mais son code postal correspond à celui de son entrée.
Incohérence de noms
Pour cette analyse, nous allons combiner une approche “classique” basée sur des comparaisons de chaînes de caractères, et une approche géographique. Nous commençons par identifier la liste de tous les couples de rues adjacentes (c’est-à-dire que l’une a une adresse distante de moins de 100 mètres d’une adresse de l’autre). On regarde ensuite si l’on ne trouve pas de petites différences dans les noms de rue. Nous rencontrons typiquement deux situations :
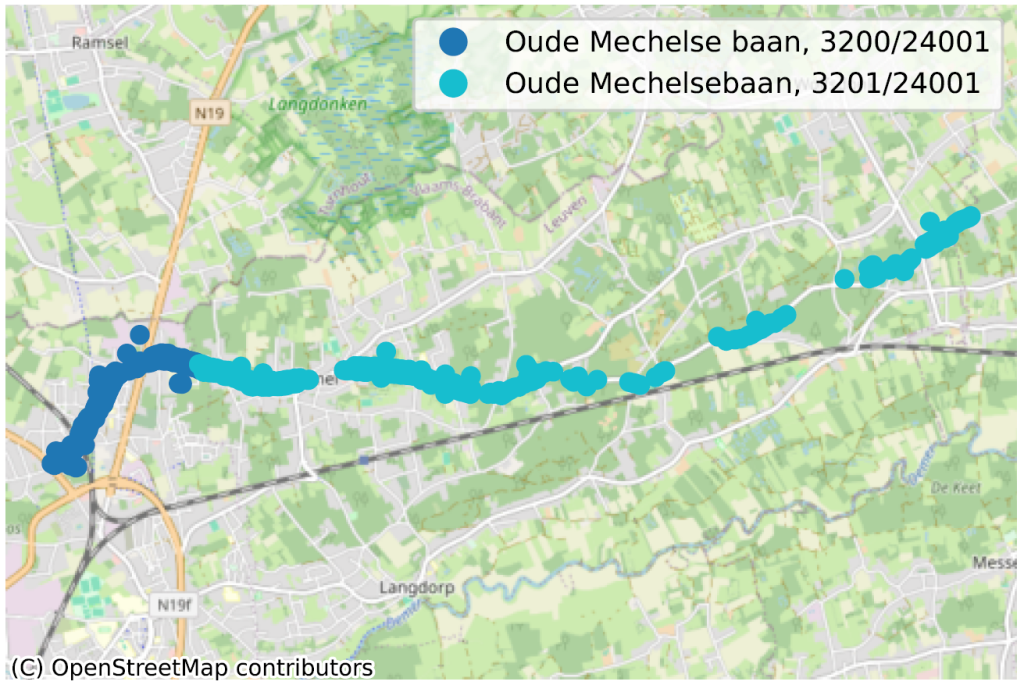
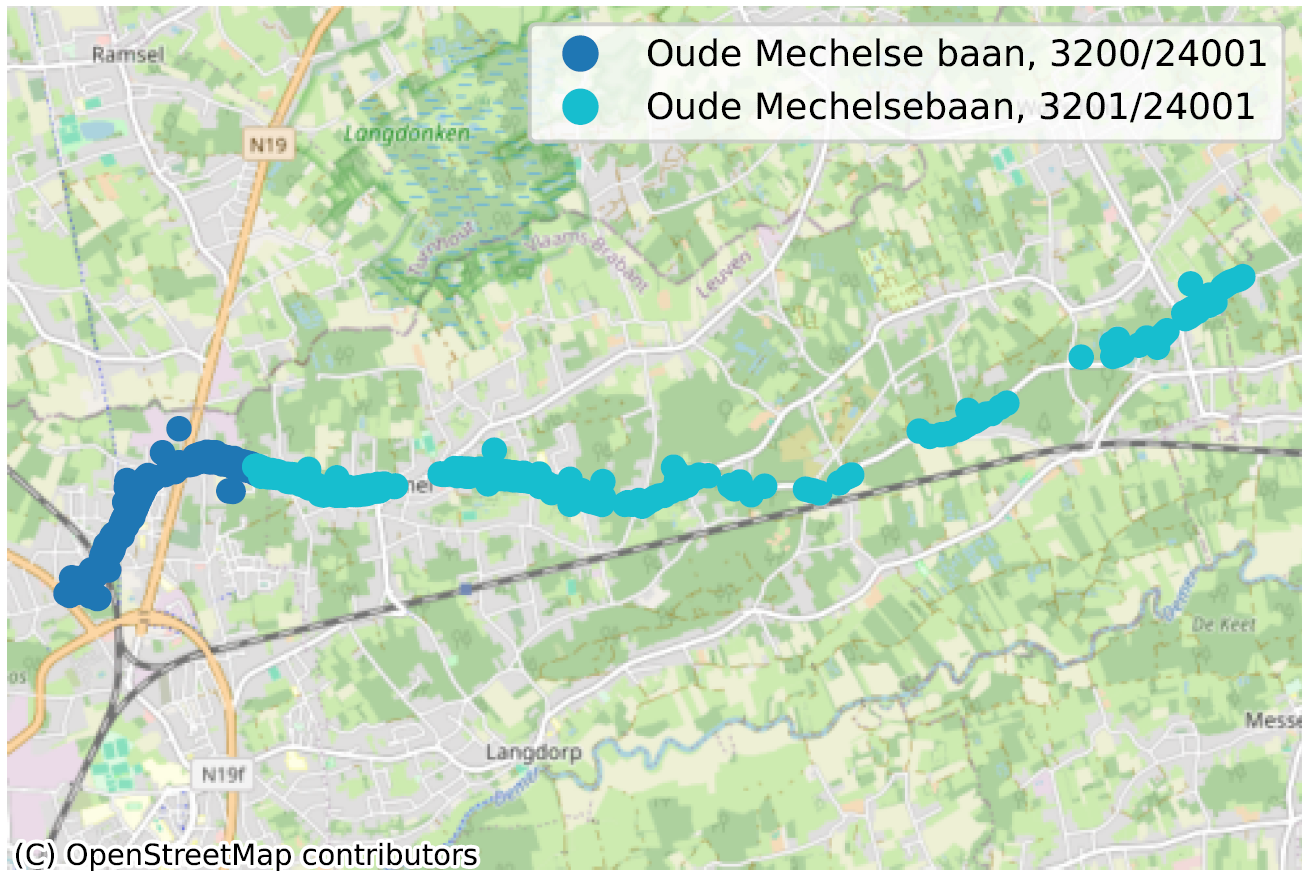
Des rues traversant plusieurs communes avec une orthographe différente dans chacune d’elle : “Rue de Monténégro, 1060″, vs “Rue du Monténégro, 1190″ ;
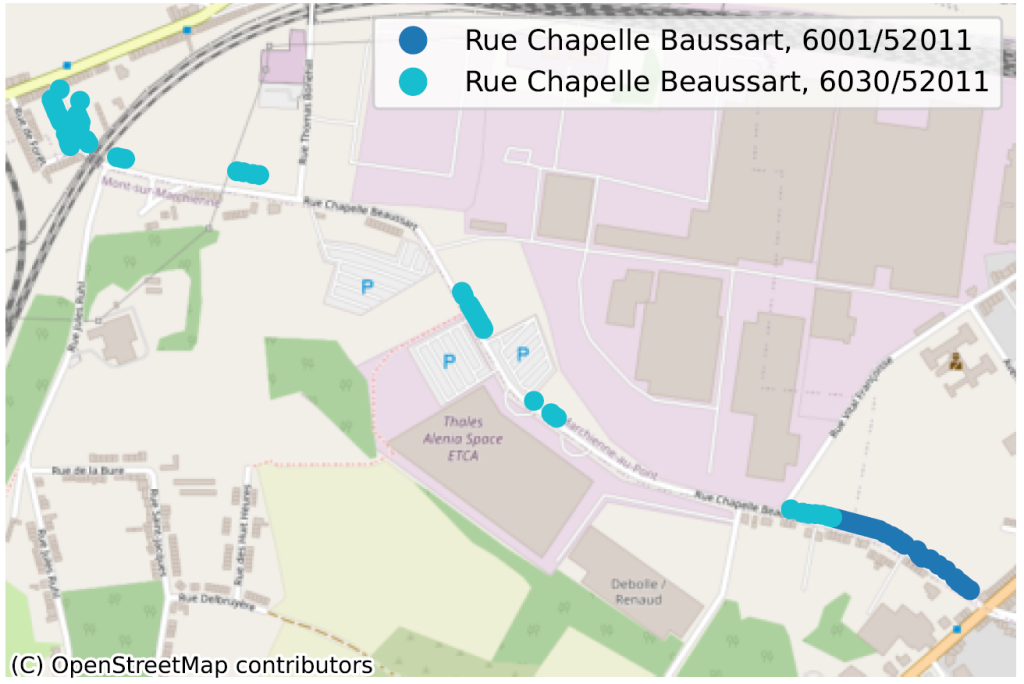
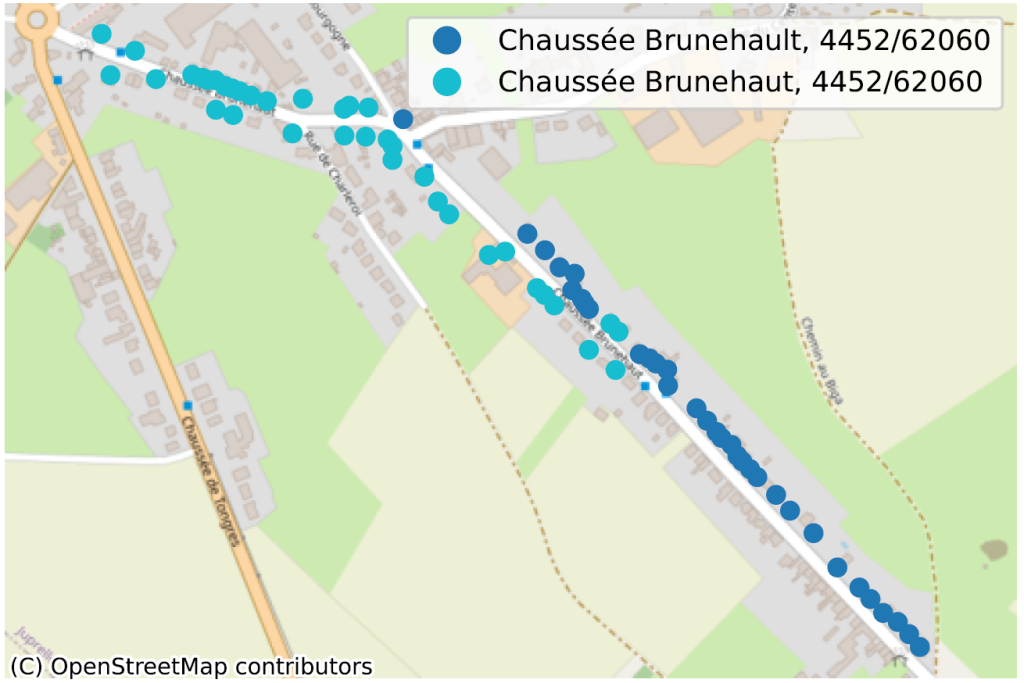
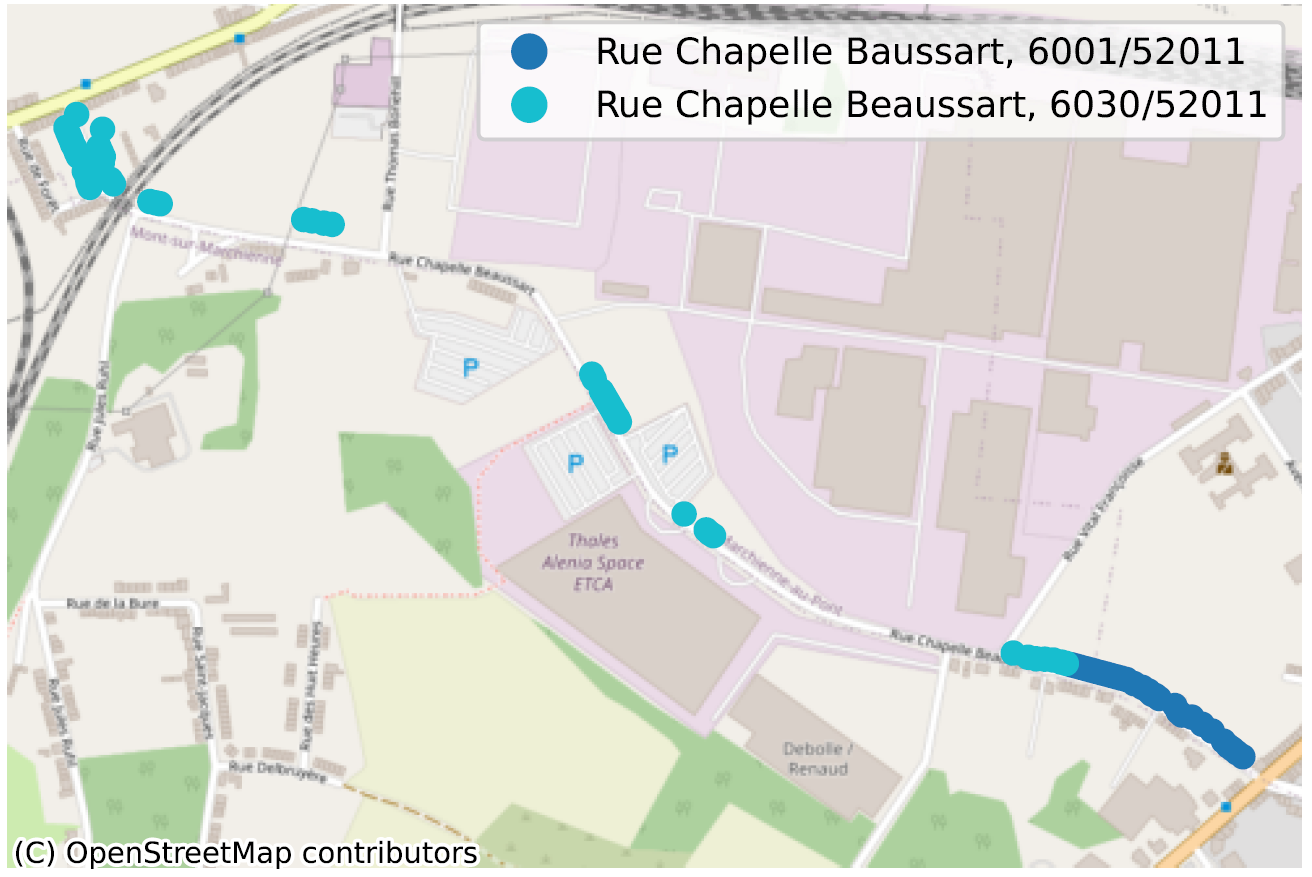
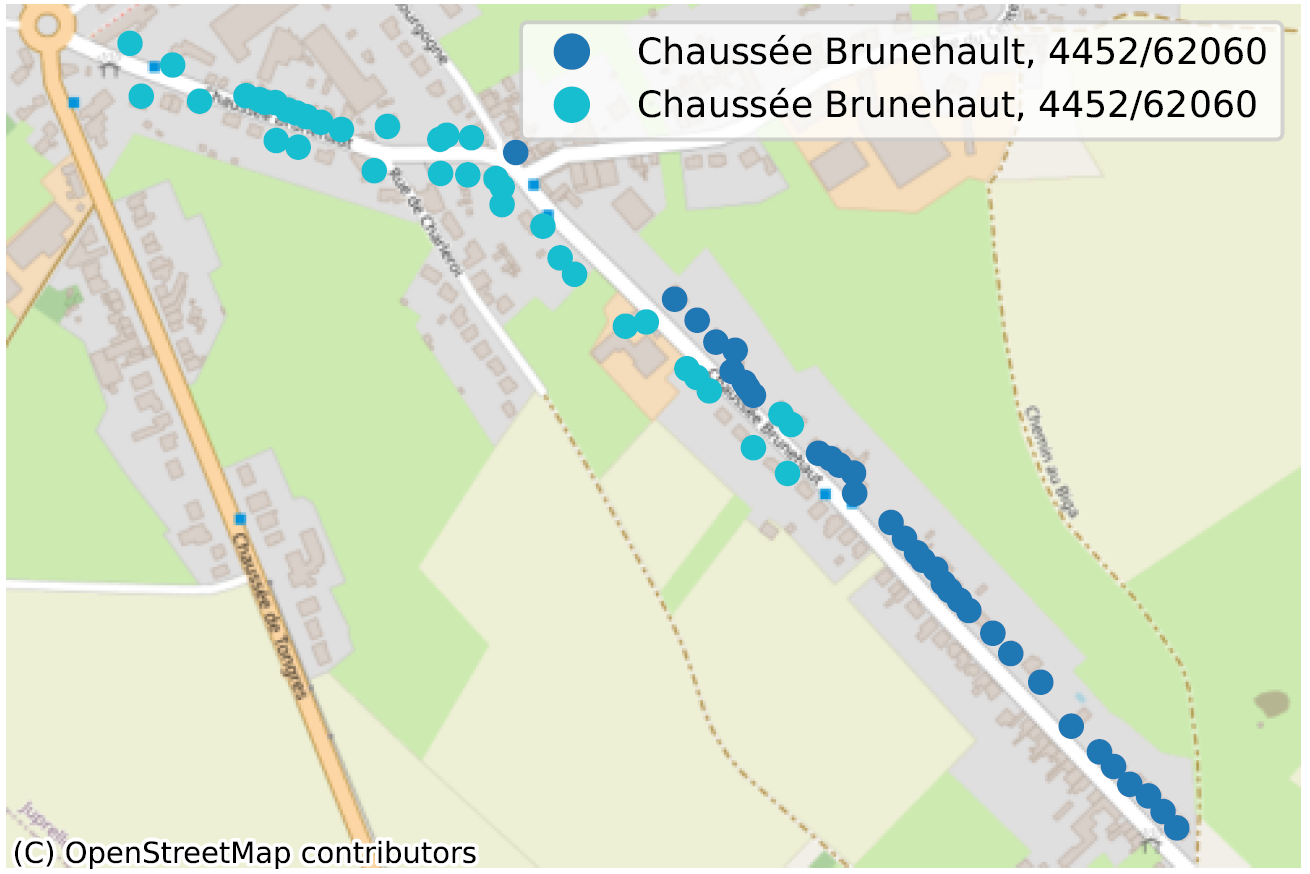
Des rues avec deux orthographes différentes au sein de la même commune : “Chaussée Brunehault” ou “Chaussée Brunehaut“, à 4452 dans les 2 cas.
On trouvera également quelques faux positifs : “Rue de Mars” vs “Rue de Mai”. On élimine de nos comparaisons les noms identiques à part une dernière lettre isolée (“Hensel laan A” vs “Hensel laan B”), ainsi que les noms où seul un chiffre change (“5de Zijweg” vs “6de Zijweg”).
Concernant la première situation, où le changement de nom arrive au passage d’une commune à l’autre, on peut regretter le manque de cohérence qui va à l’encontre de l’article 5 de la directive décrite plus haut, qui dit que “[d]ans l’hypothèse où une voie s’étend sur le territoire de plusieurs communes, et que cette voie garde le même nom, ces communes doivent s’assurer que l’orthographe de ce nom de rue soit identique dans toutes les communes concernées”. La directive n’est cependant pas contraignante, les communes sont donc libres de garder leur orthographe propre.
Credit: Google StreetView
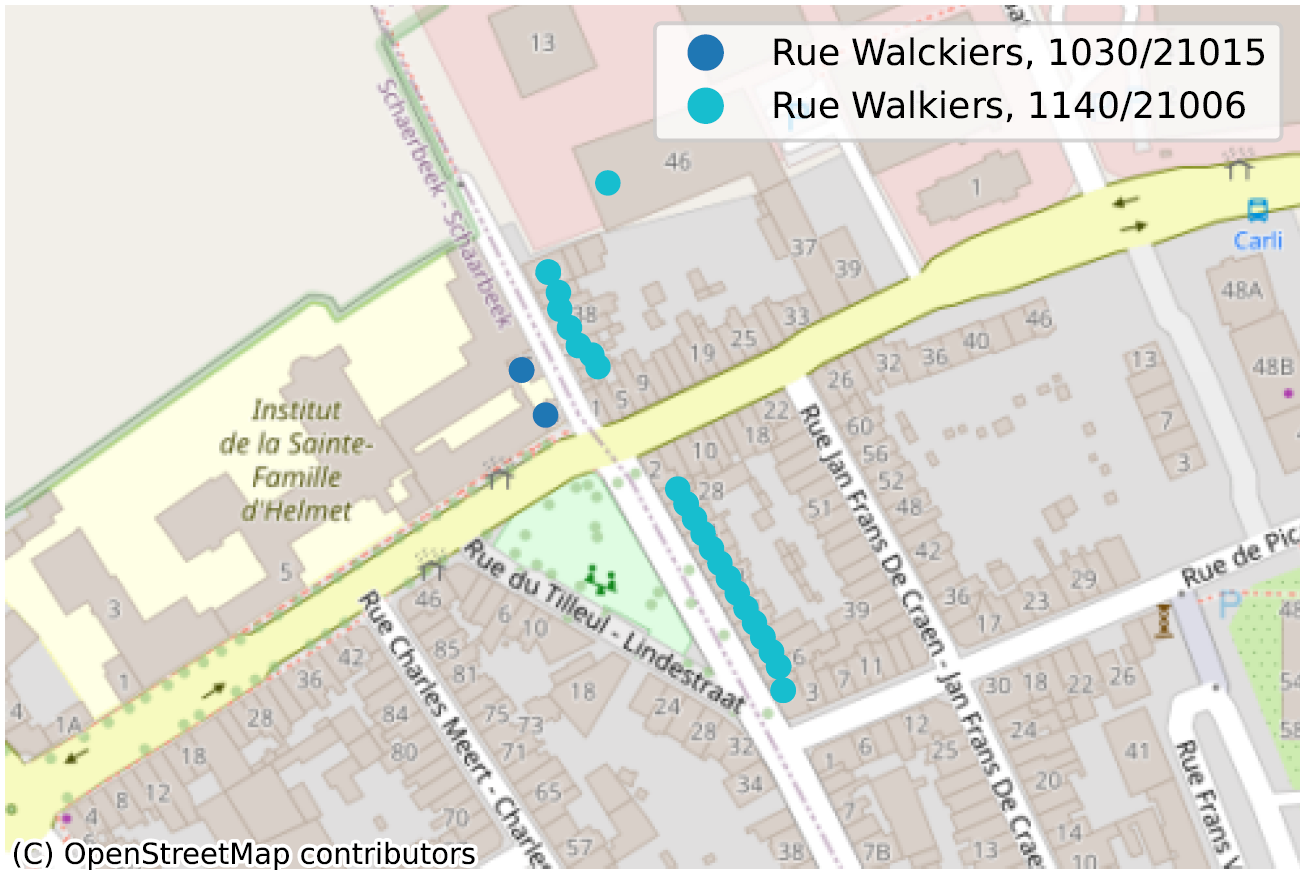
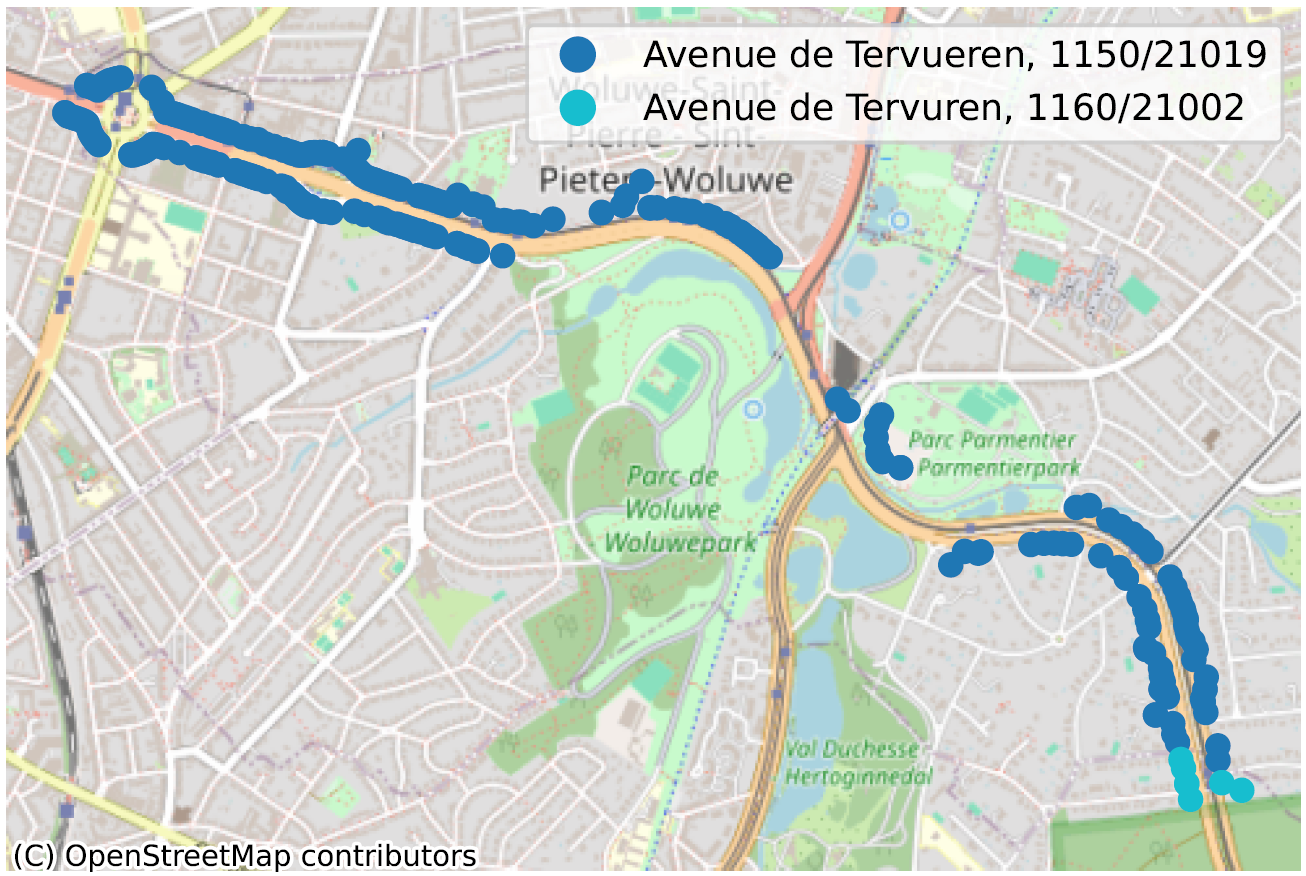
Il est cependant pertinent de se demander si l’orthographe présente dans BeSt (transmise par les communes) est réellement la bonne. On peut par exemple citer la “Rue Walckiers” à 1030 Schaerbeek, qui prolonge la “Rue Walkiers” à 1140 Evere. Or, la (seule) plaque schaerbeekoise de la rue l’orthographie … “Rue Walkiers” ! Il en va de même pour la (petite) portion auderghemoise de l’avenue de Tervueren, orthographiée comme telle à Woluwé-Saint-Pierre, ainsi que sur les plaques de rue à Auderghem, mais reprise dans BeSt comme “Avenue de Tervuren” à Auderghem. Nous pourrions citer bien d’autres exemples.
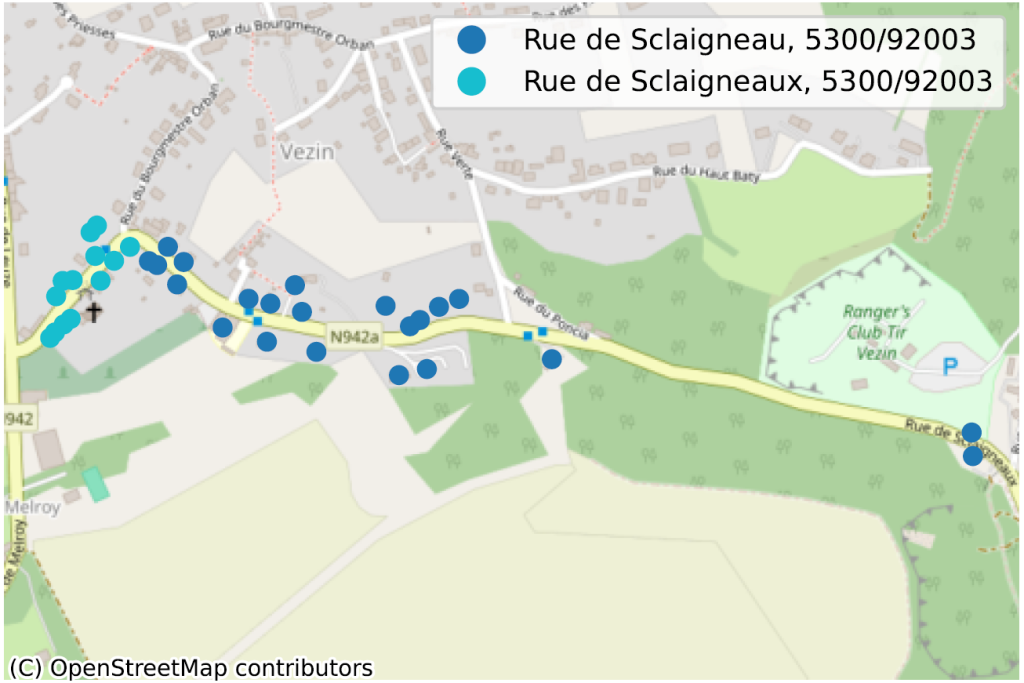
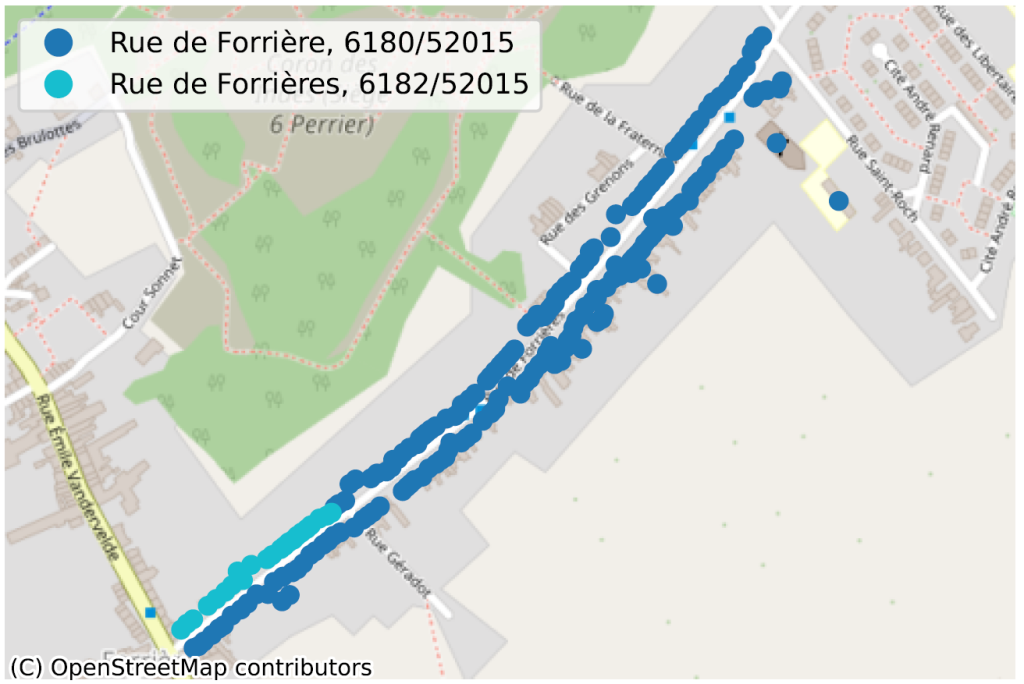
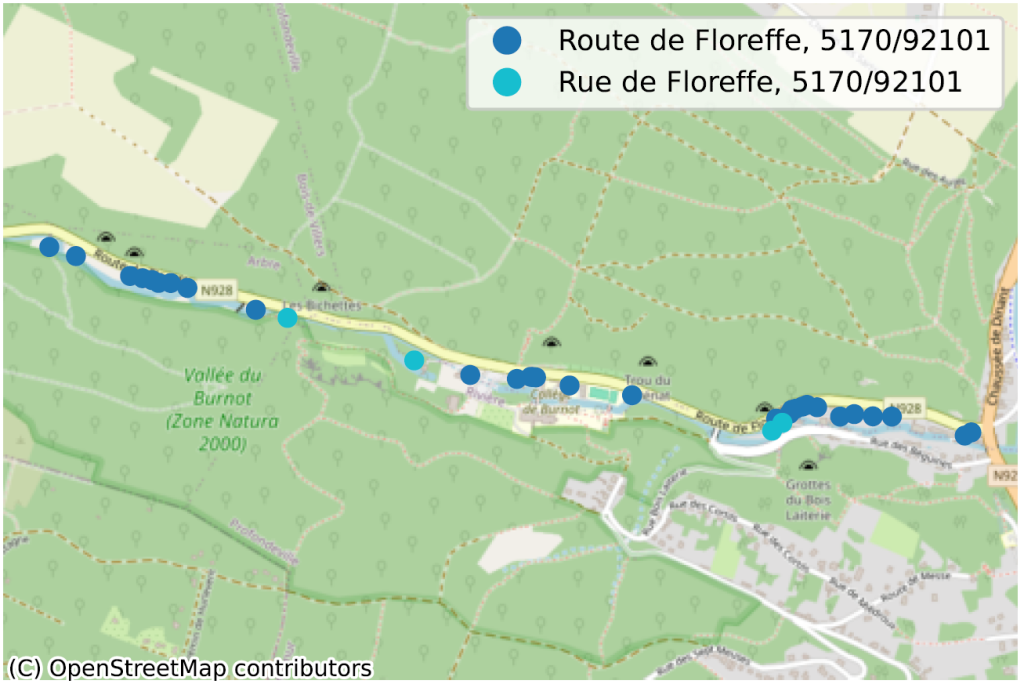
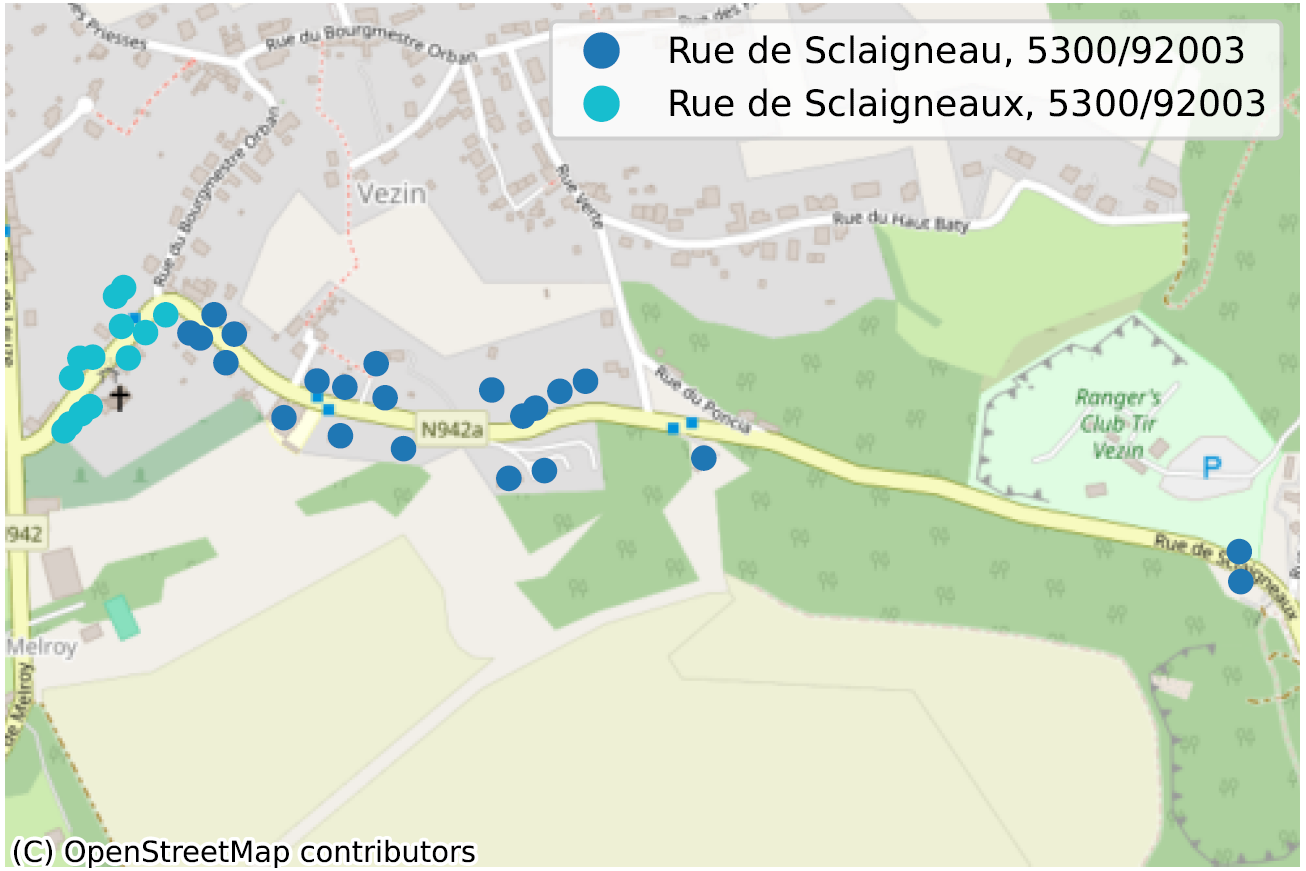
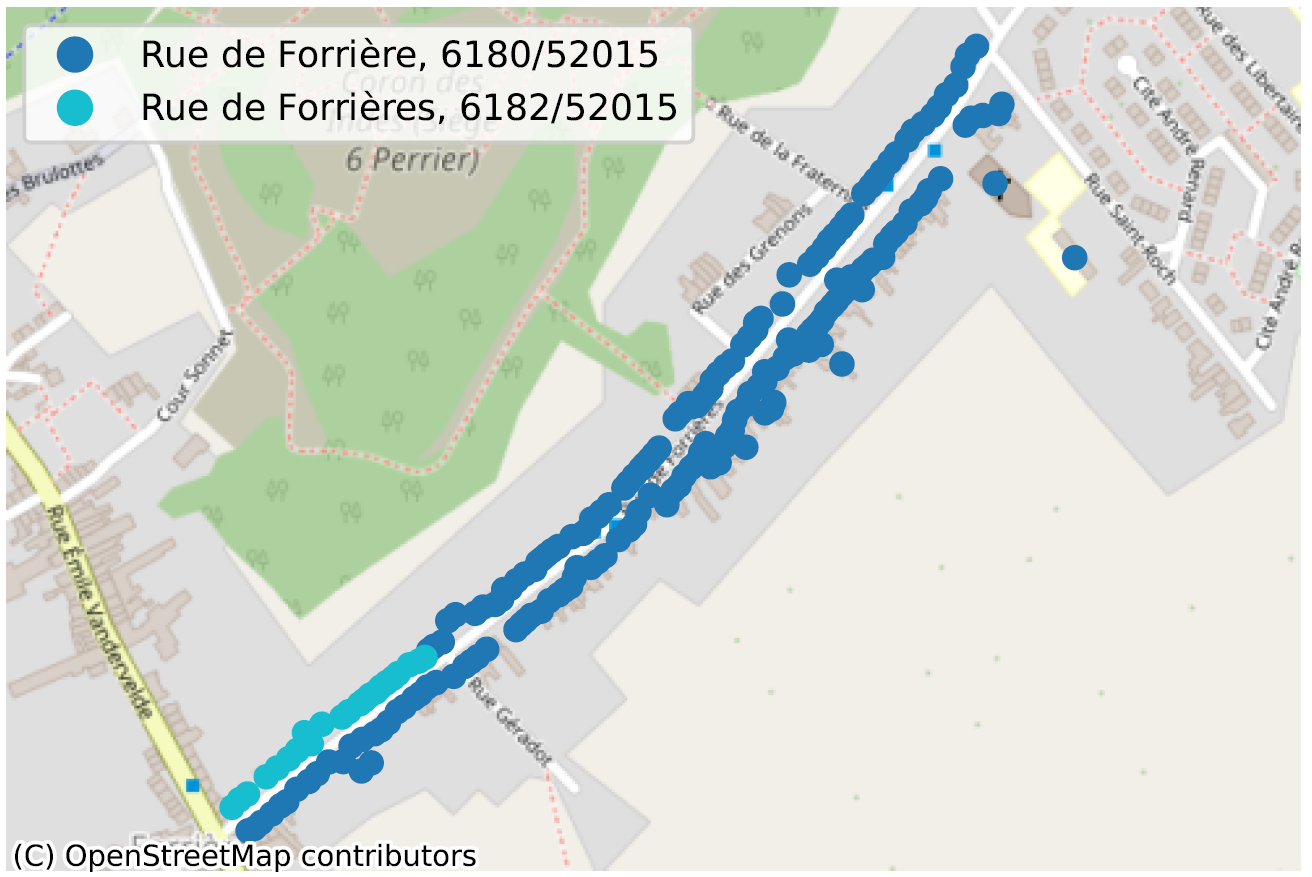
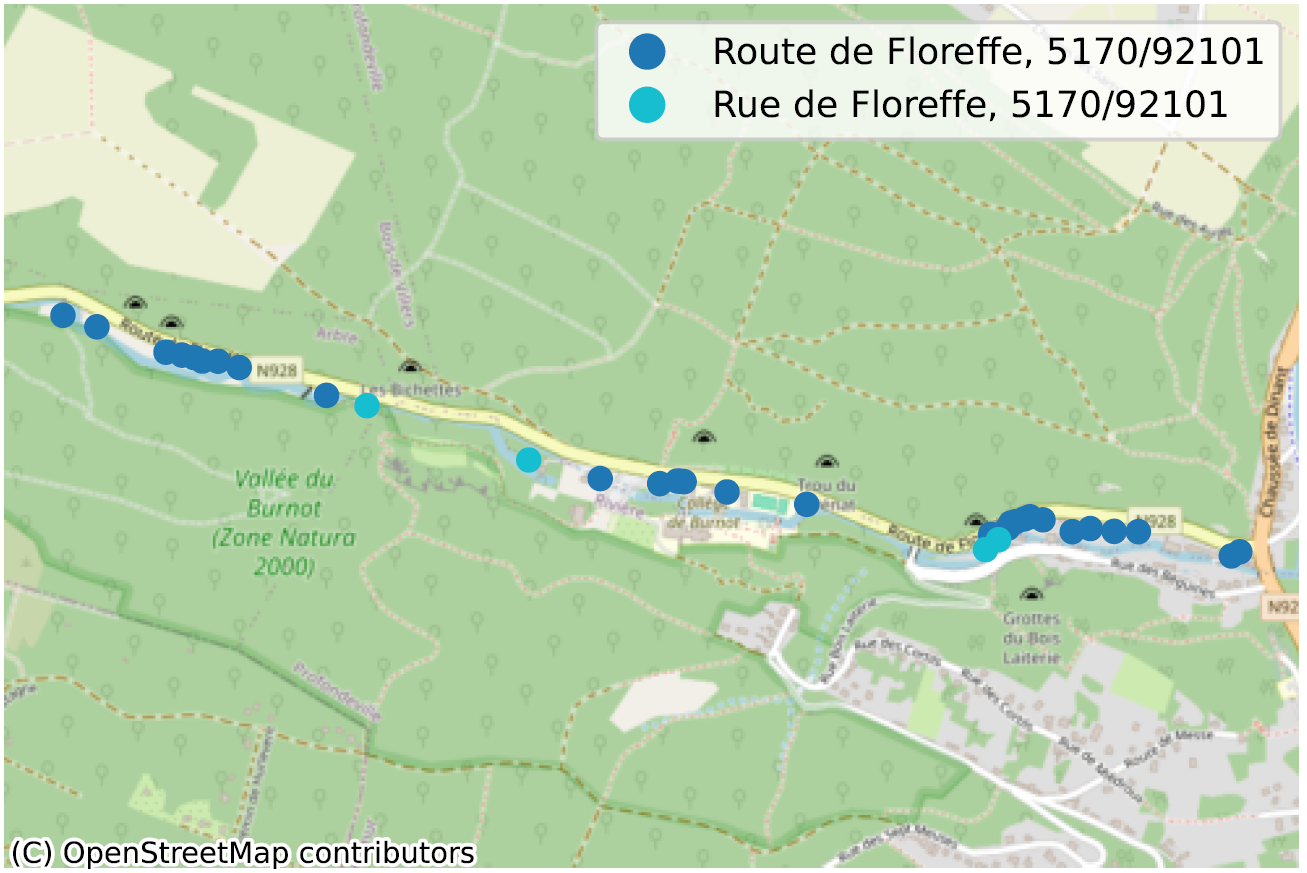
La situation où, au sein d’une même commune, parfois même pour un même code postal, deux portions de rue n’ont pas la même orthographe, dénote de façon plus évidente d’un problème de qualité de données. Nous en avons identifié des dizaines, principalement en Wallonie, nous n’en reprenons ici que quelques-uns pour illustration.
Géométrie incohérente
Nous considérons ici la forme géométrique composée de la séquence de points des adresses de même parité, pour une même rue et un même code postal. Sur cette ligne, nous calculons ensuite un certain nombre de métriques, en supposant que les valeurs les plus élevées dénotent d’une anomalie.
Nous avons défini de façon expérimentale un certain nombre de métriques. Nous allons juste en détailler deux qui nous ont paru les plus pertinentes à l’analyse. Mais dans une analyse approfondie, il conviendra de les combiner avec d’autres :
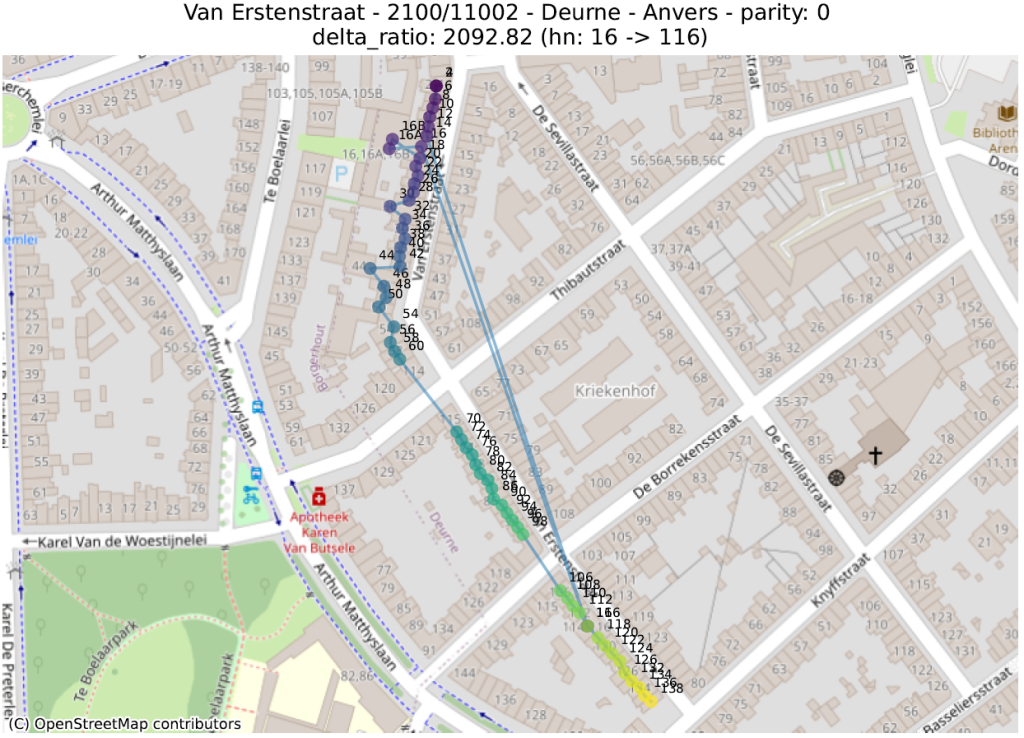
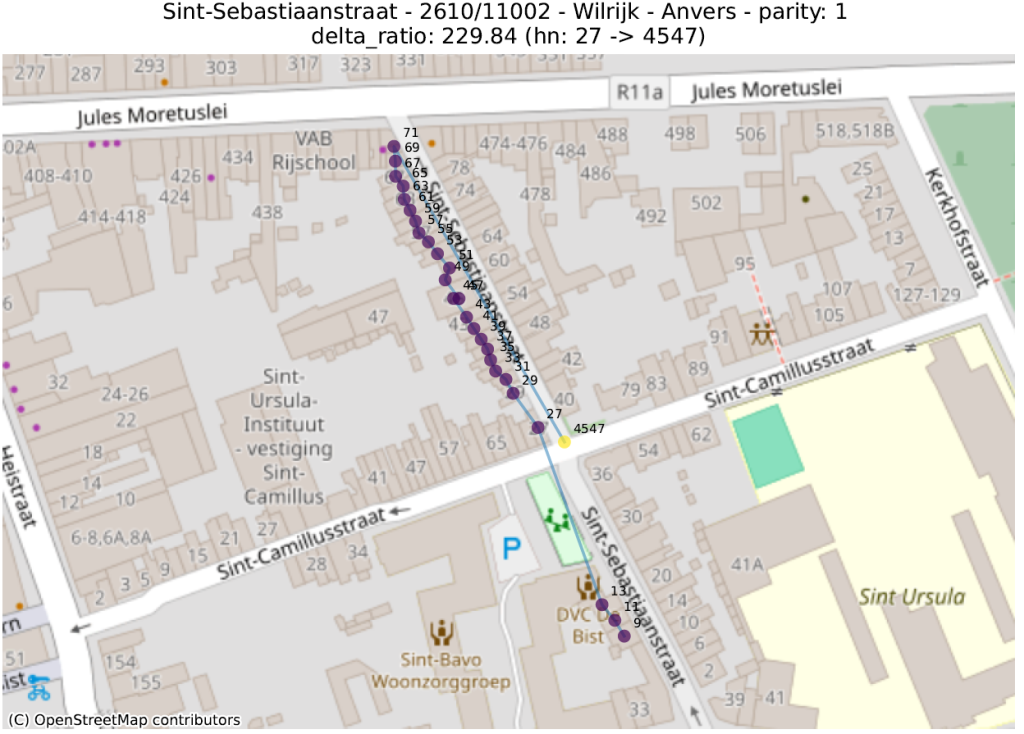
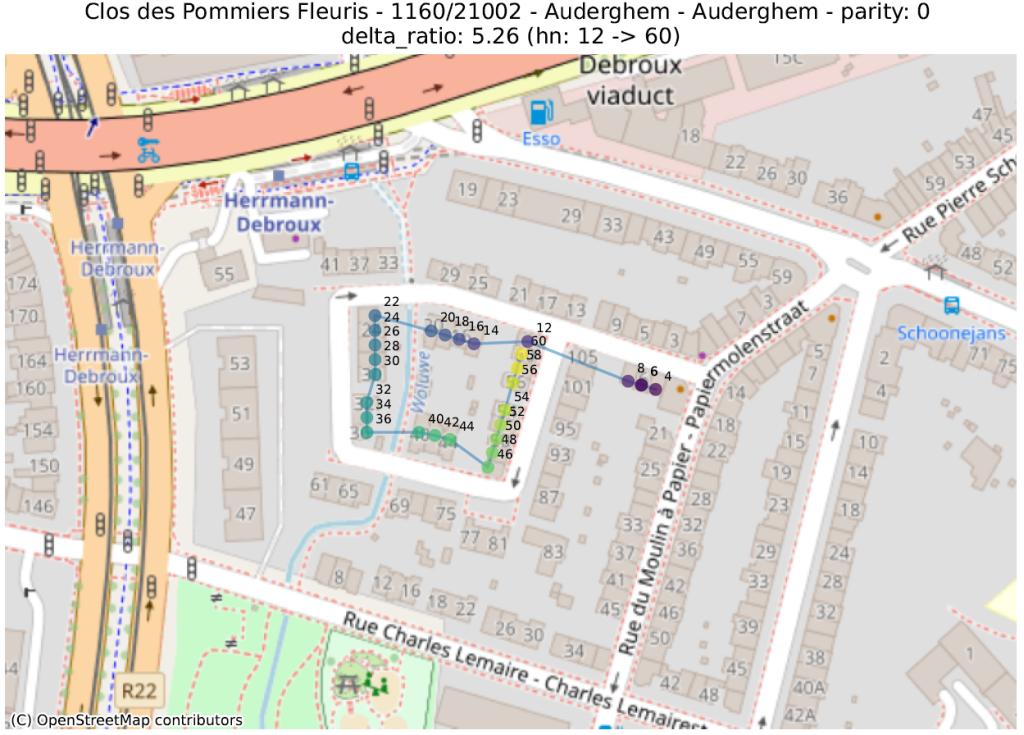
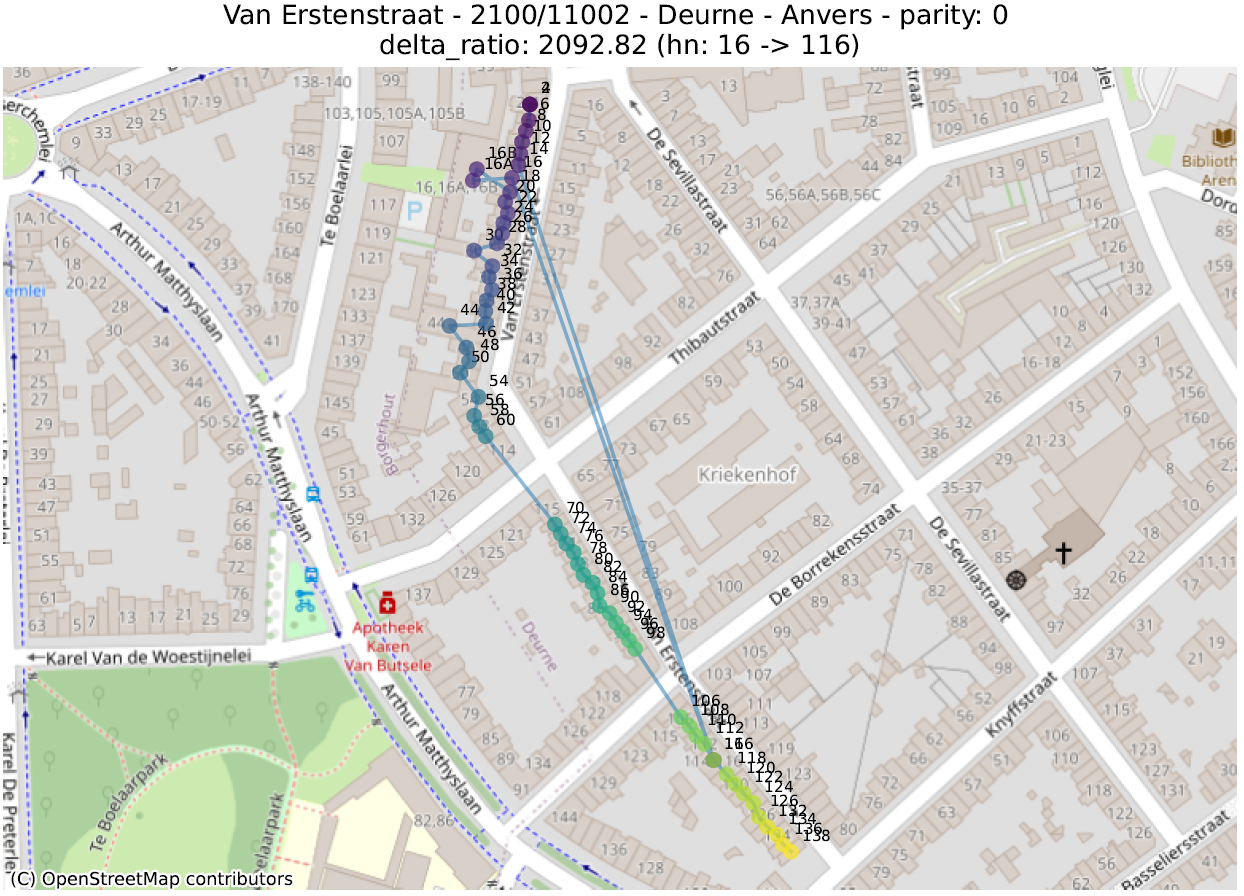
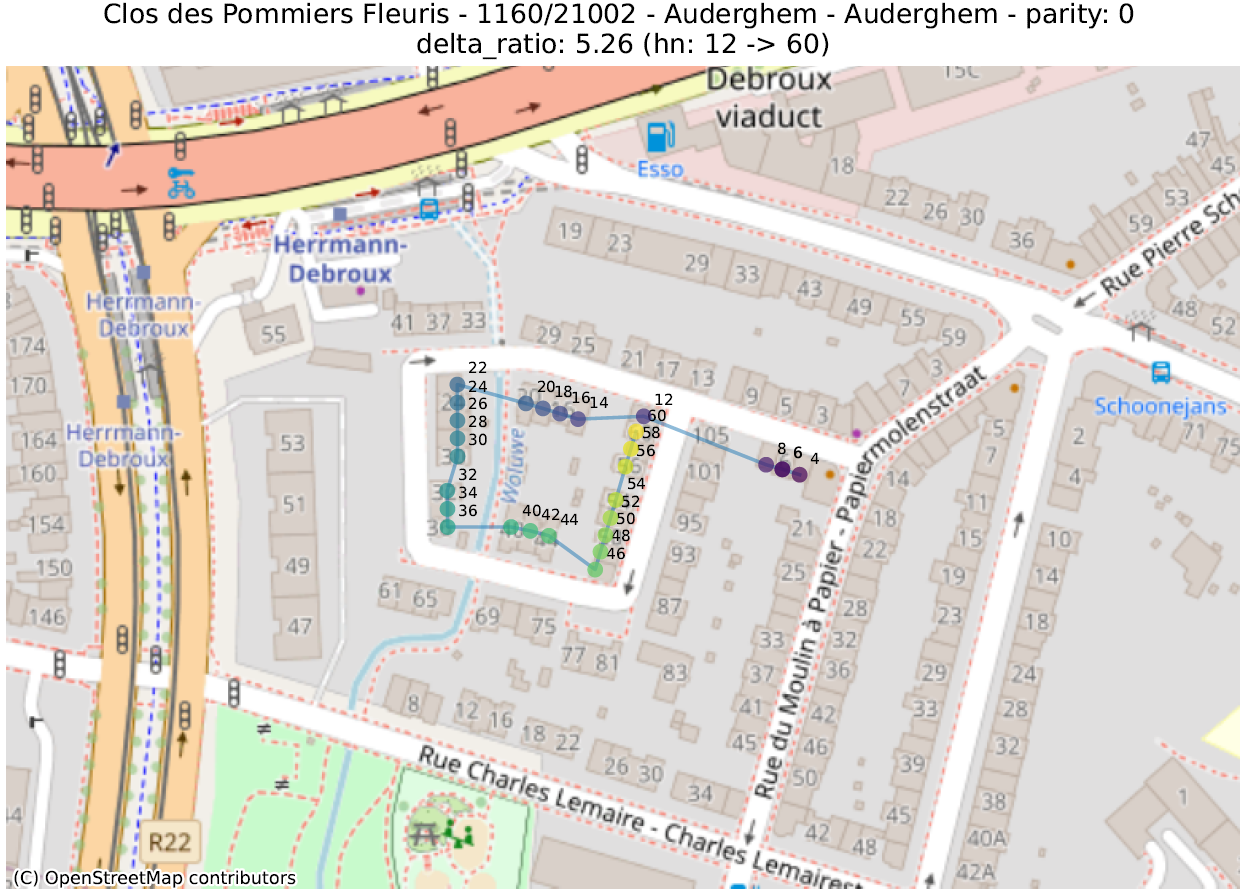
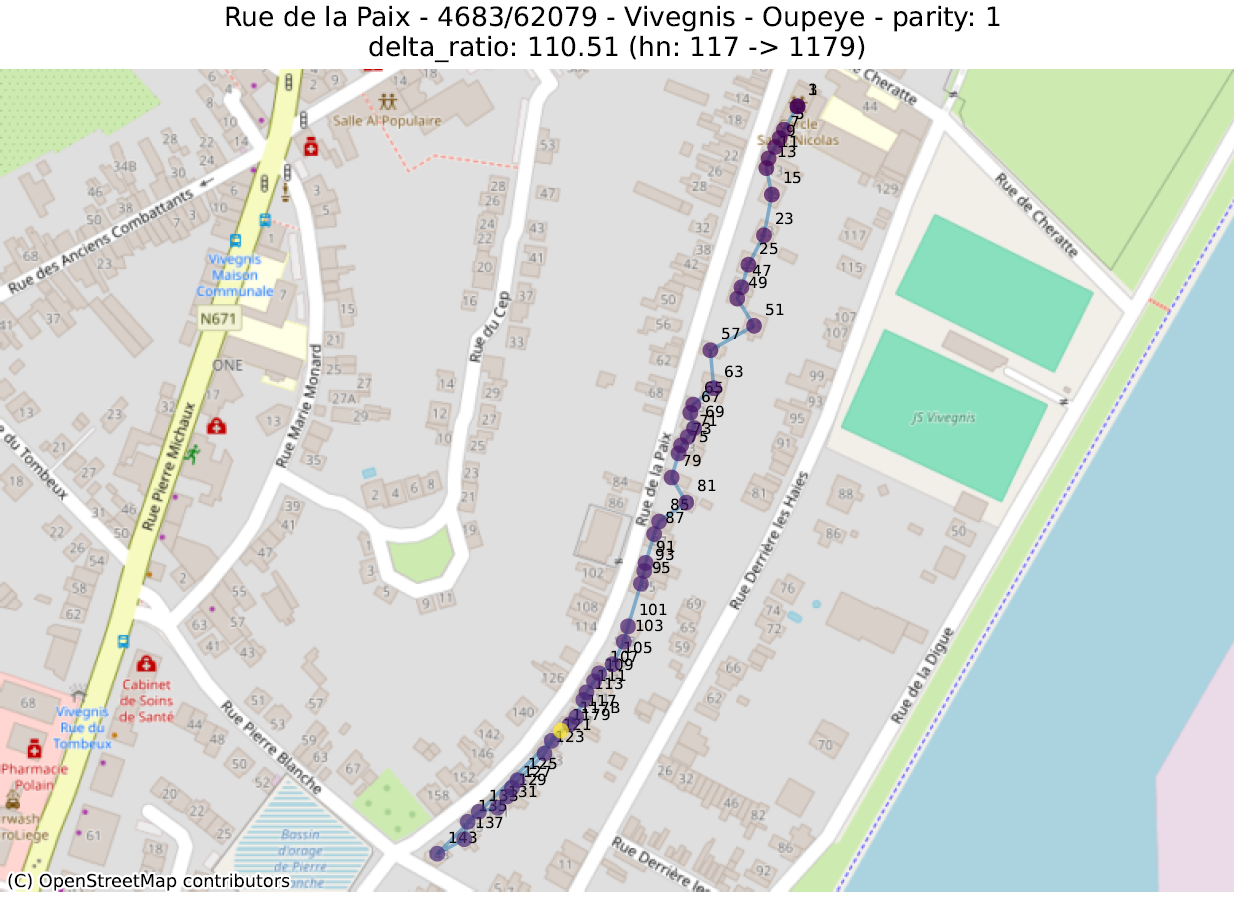
delta_ratio : pour chaque couple d’adresses d’une même rue et de même parité, on calcule le ratio de la différence entre la partie numérique des numéros de maison et la distance. Une valeur élevée indique que deux maisons de numéros très distants sont anormalement proches. Ceci s’explique souvent par deux phénomènes distincts :
Situation normale : une rue “circulaire”, dans laquelle le dernier numéro se situe à côté du premier,
Situation anormale : sur le coin entre deux rues, un bâtiment a été assigné à la mauvaise rue. Ou plus généralement, une inversion entre deux numéros ;
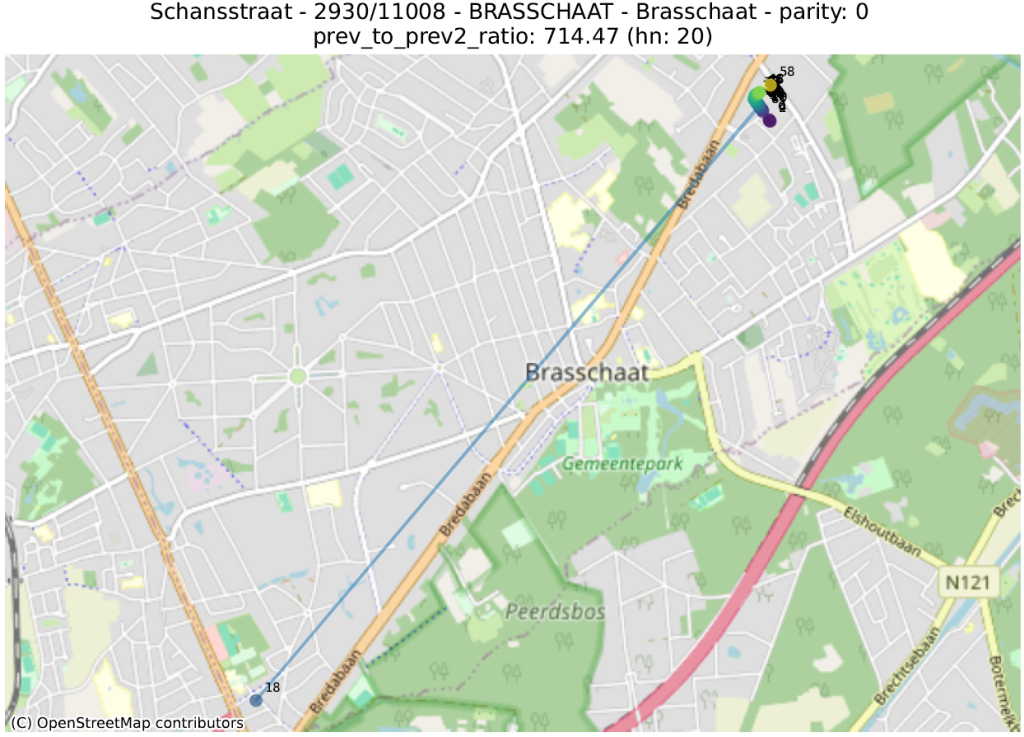
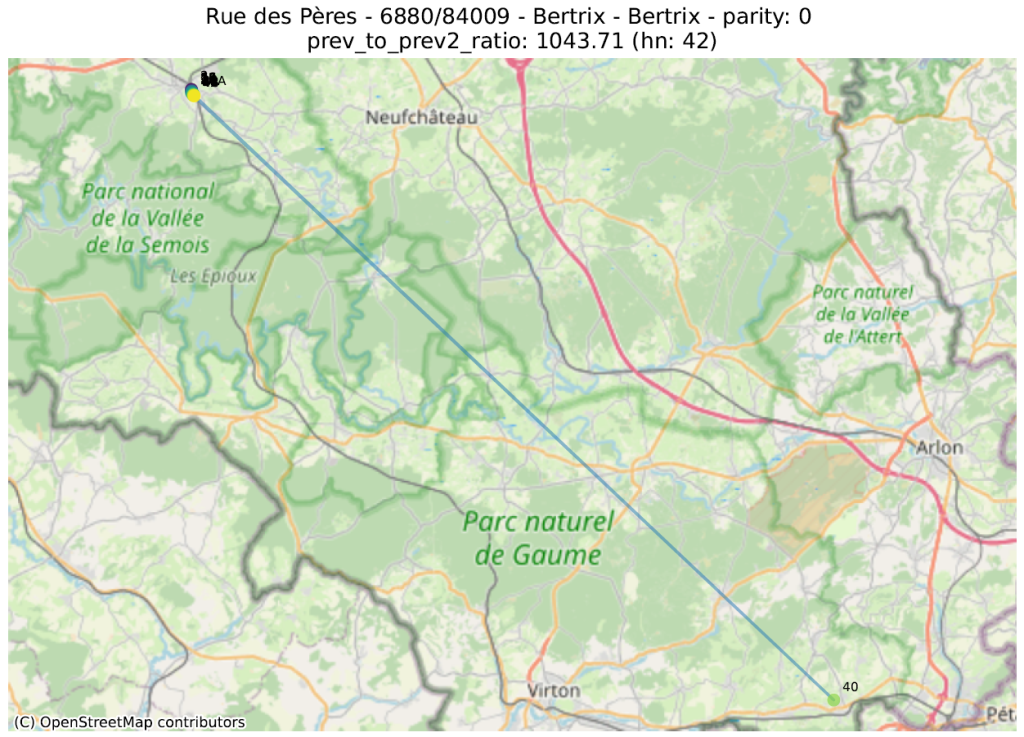
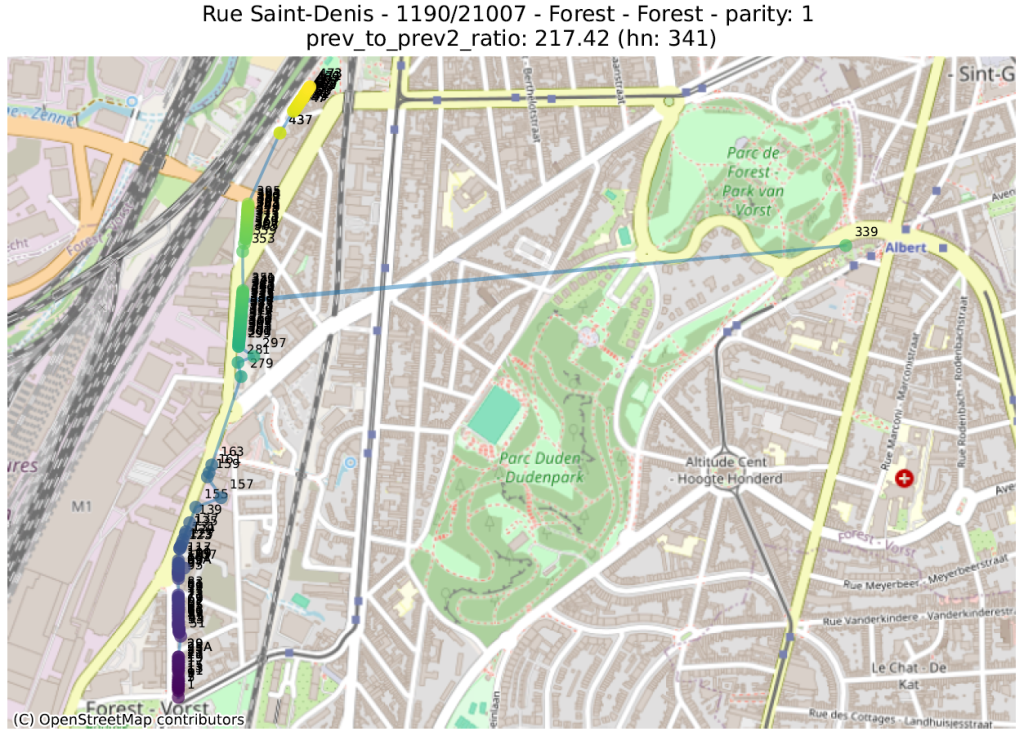
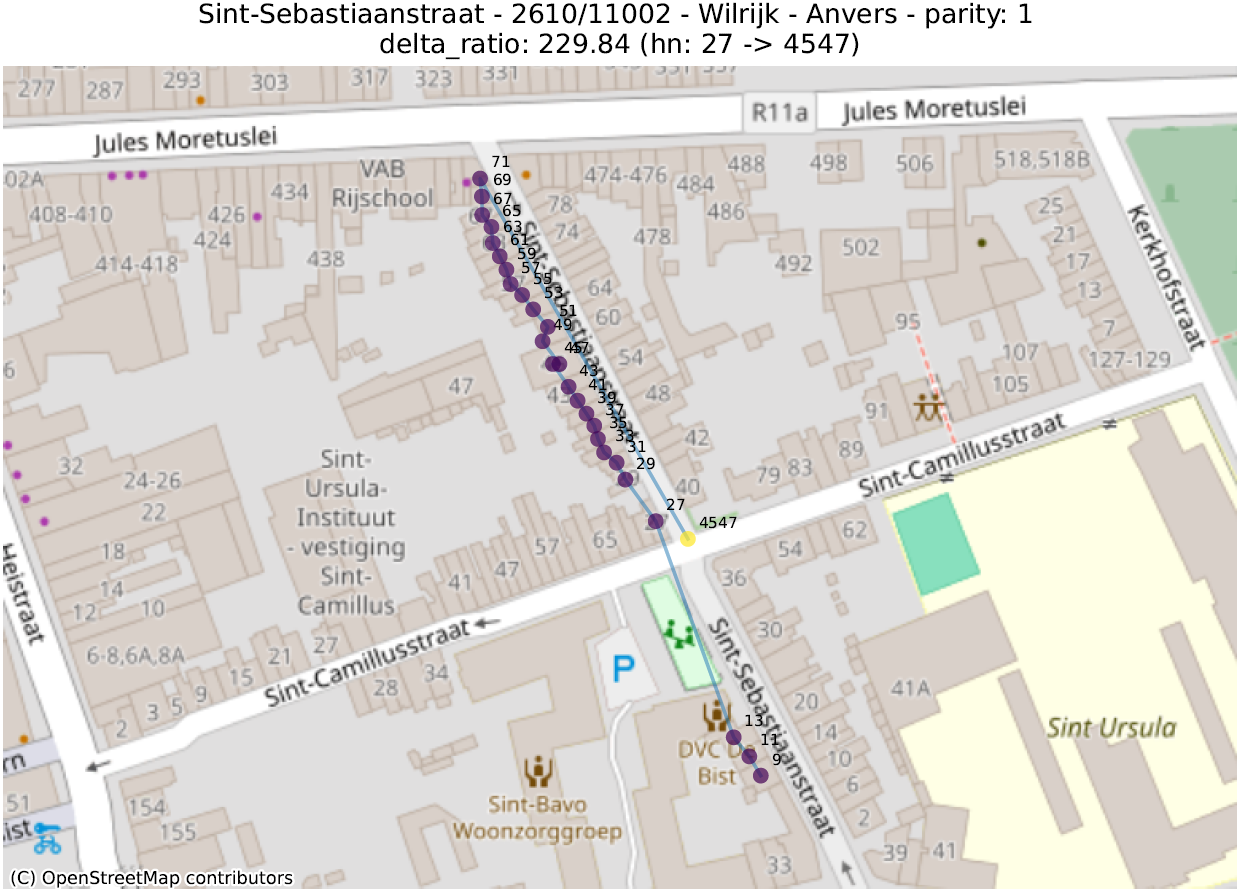
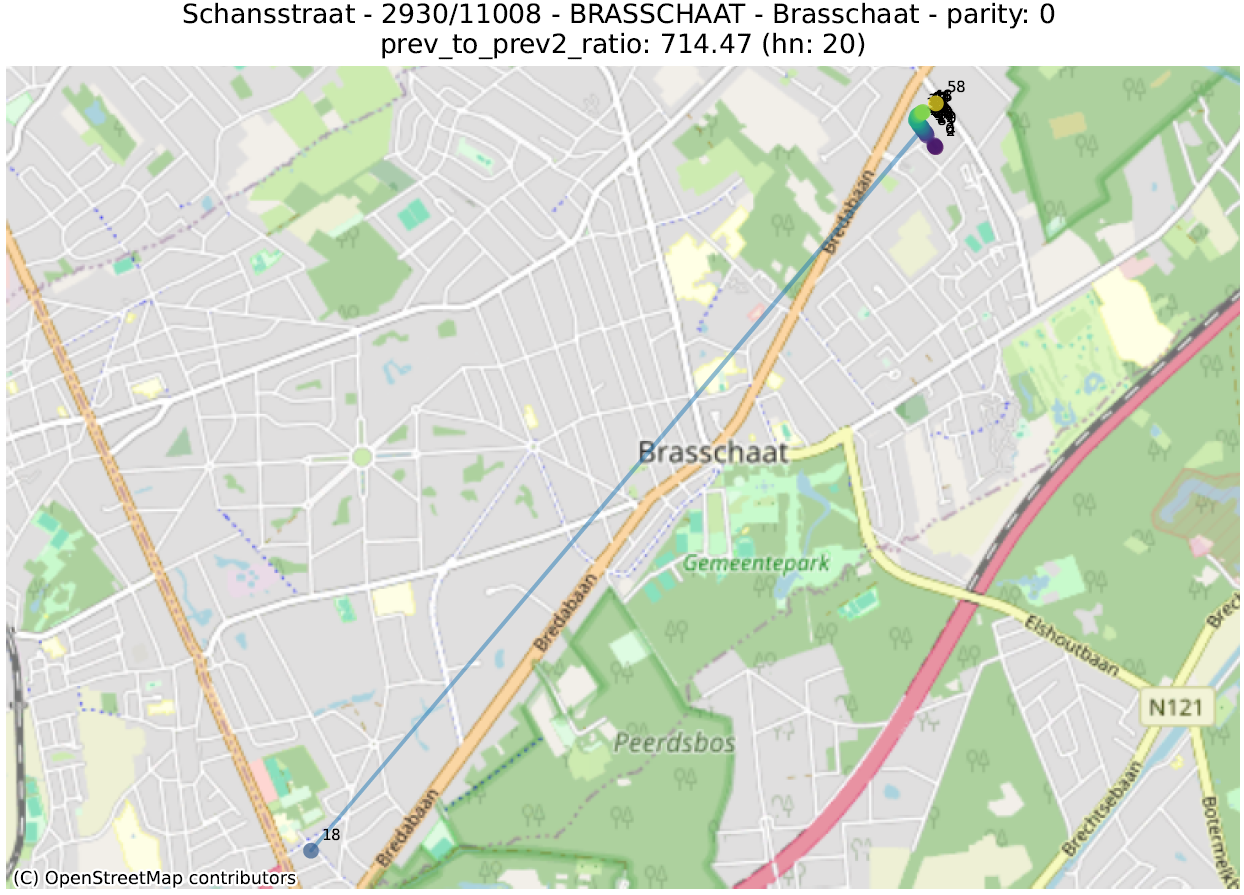
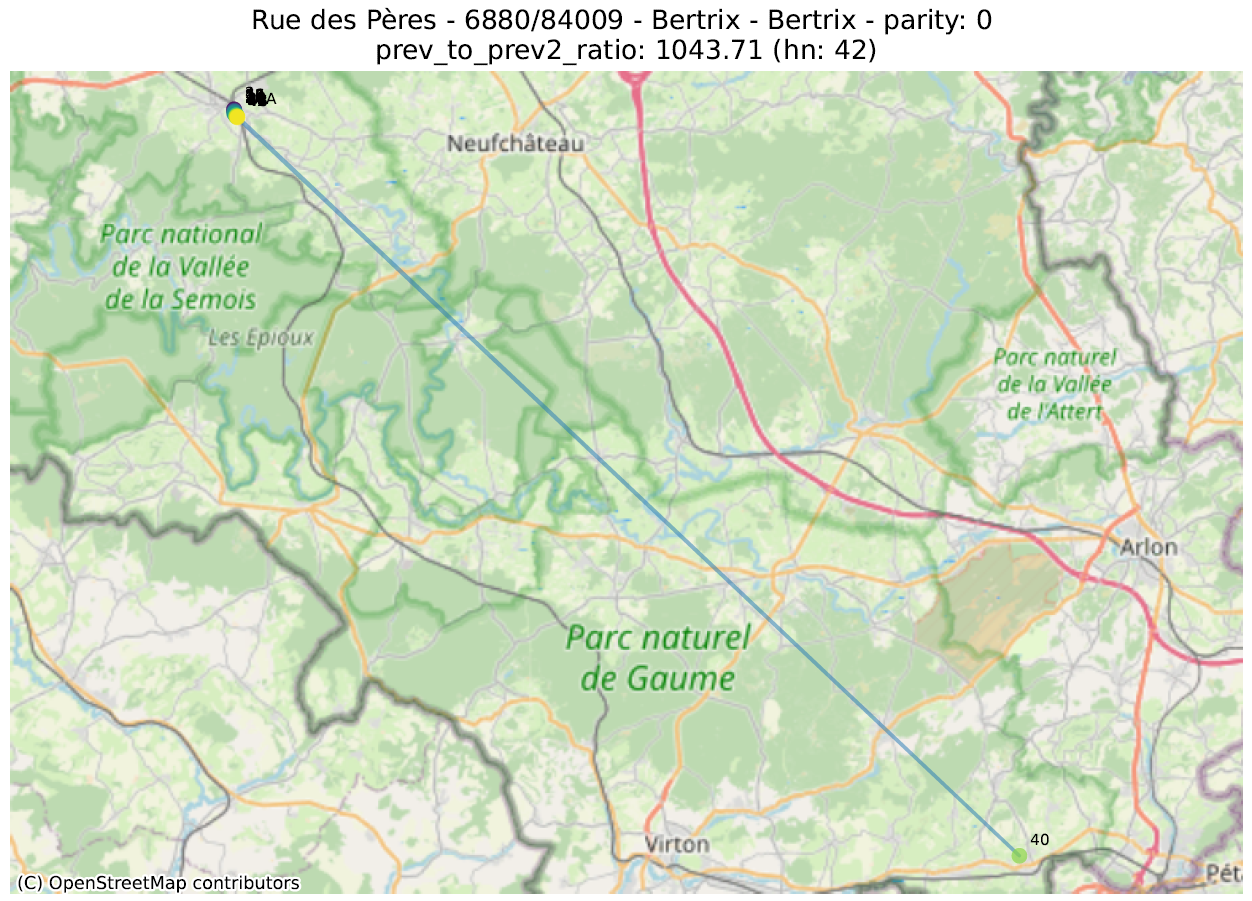
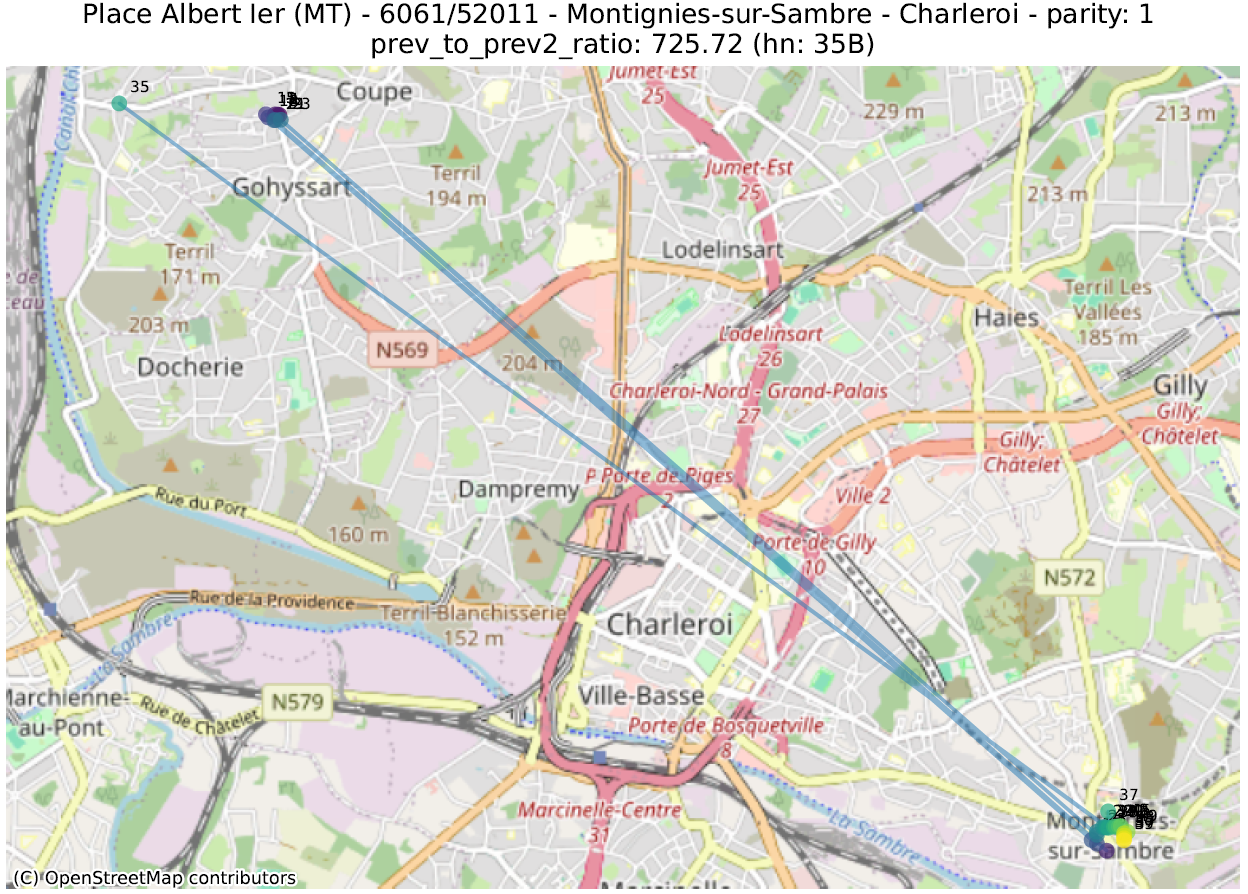
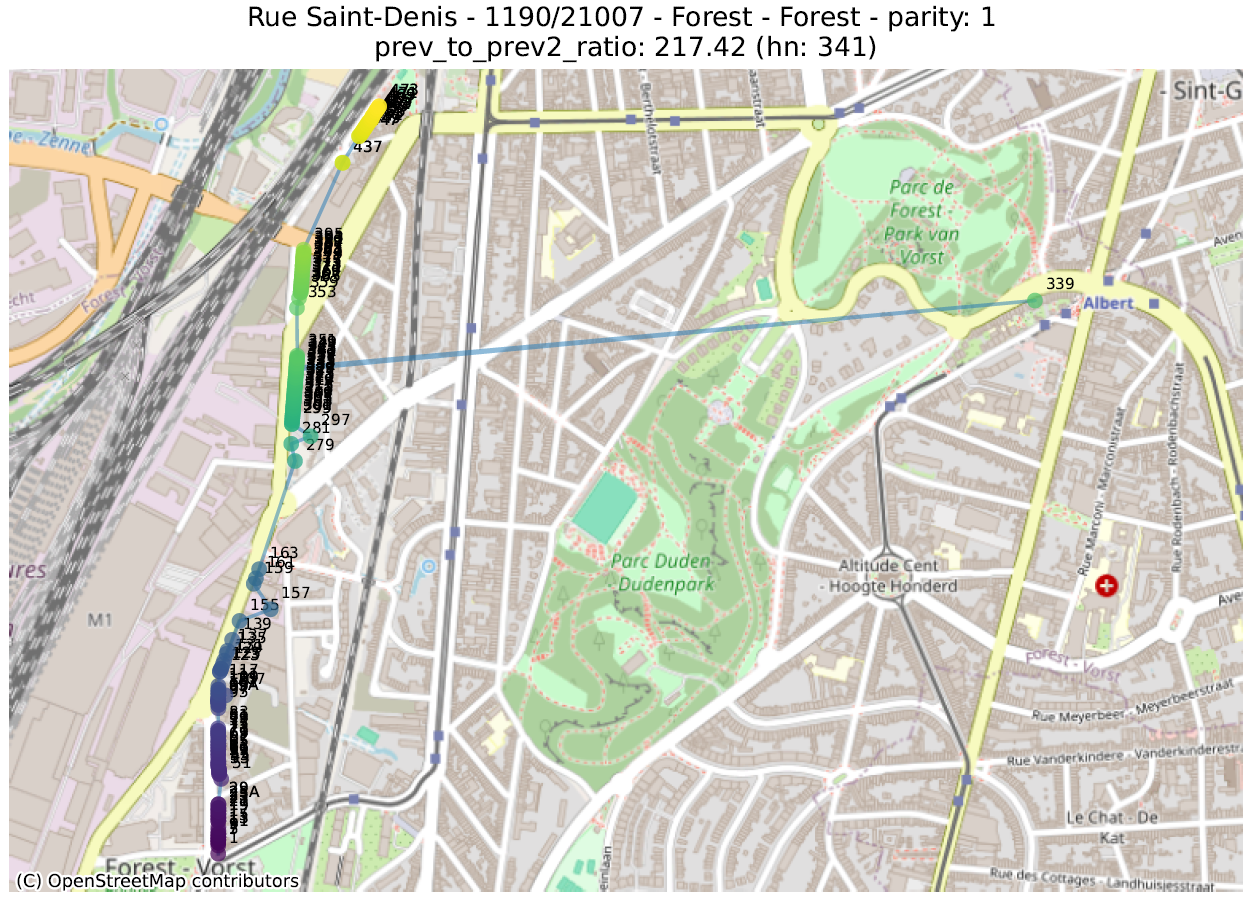
prev_to_prev²_ratio : on s’attend en général à ce qu’un numéro soit plus proche du numéro suivant (de même parité) que de celui d’encore après. Si le numéro 2 est beaucoup plus proche du 6 que du 4, il est probable que le 4 soit mal placé. On calcule ici le ratio de la distance d’un numéro au numéro précédent (par ex. entre 4 et 6) sur la distance entre ce numéro et celui qui précède le précédent (par ex. entre 2 et 6). Une valeur de 100 indique donc qu’un numéro (indiqué un ‘hn:…’ dans le titre du graphique) est 100 fois plus proche de deux numéros en arrière que du numéro précédent.
La première métrique mettra en évidence des adresses qui ont été localisées dans la bonne rue, mais pas au bon endroit. La seconde fera ressortir des adresses qui ont été localisées très loin des autres numéros de la même rue.
Dans les illustrations suivantes, les points sont colorés séquentiellement selon la valeur numérique du numéro de police, allant de mauve pour la plus petite valeur à jaune pour la plus grande. Une ligne relie ces points dans l’ordre numérique.
16 juste à côté du 116 4547 juste à côté du 27 Rue circulaire (pas d’anomalie) 1179 juste à côté du 117delta ratio 18 mal placé 40 mal placé plusieurs mal placés 339 mal placéprev to prev² ratio
L’analyse de ces anomalies nécessite souvent une attention au cas par cas, pour savoir s’il s’agit d’une erreur manifeste, ou du reflet d’une disposition un peu particulière. Ce travail ne peut être fait que par des instances de terrain, à savoir les communes, qui transmettent ces informations aux régions puis au SPF BOSA.
Le mot de la fin
Le code (notebook Python) qui nous a permis d’identifier toutes ces anomalies est disponible sur Github, et permet entre autres une vue interactive de toutes les cartes présentées ci-dessus. Pour chacune des anomalies, il ne nous revient pas de déterminer s’il s’agit réellement d’une erreur (il y aura beaucoup de faux positifs), et, le cas échéant, à quel niveau elle se situe : la commune, la consolidation par les régions ou le SPF BOSA, bpost, la plaque de rue…
Par ailleurs, le nombre de cas problématiques reste faible par rapport aux 6,5 millions d’adresses que contient BeSt Address. Mais la méthodologie nous paraissait suffisamment intéressante pour la publier. On pourrait par ailleurs l’appliquer à d’autres jeux de données, comme par exemple OpenStreetMap, ou d’autres sources ouvertes.
Quelle que soit la façon dont est alimentée une base de données, des erreurs s’y introduisent. Les régions et le SFP BOSA font déjà un travail considérable pour garantir des données d’une très bonne qualité. Mais il sera toujours possible de détecter des nouveaux problèmes. Par cet article, nous espérons apporter notre modeste contribution à l’édifice.
Ce post est une contribution individuelle de Vandy Berten, spécialisé en data science chez Smals Research. Cet article est écrit en son nom propre et n’impacte en rien le point de vue de Smals.